当前位置:网站首页>[machine learning] kmeans clustering
[machine learning] kmeans clustering
2022-07-22 03:08:00 【jeffery0207】
Write in front of the article
Kmeans The algorithm is a classical clustering algorithm , It belongs to the category of unsupervised learning . Clustering , That is, for a given sample set , According to the distance between samples , Divide the sample set into K A cluster of , And let the points in the cluster be connected as closely as possible , And make the distance between clusters as large as possible .
advantage :
- The principle of simple
- Fast
- It has good scalability for large data sets
shortcoming :
- You need to specify the number of clusters K
- Sensitive to outliers
- Sensitive to initial values
Principle overview
Algorithm flow
The following description is based on Lloyd’s Algorithm
- Set up a k value , That is, set how many clusters need to be clustered
- Random choice k A center of mass (centroids)
- Calculate the distance from each sample point to the centroid , Clustering
- Repeat the first 2、3 step , Until the number of iterations reaches the set maximum or the center of mass no longer moves
Evaluation criteria
The k-means algorithm divides a set of N samples X into K disjoint clusters C, each described by the mean μ j \mu_j μj of the samples in the cluster. The means are commonly called the cluster “centroids”; note that they are not, in general, points from X, although they live in the same space. The K-means algorithm aims to choose centroids that minimise the inertia, or within-cluster sum of squared criterion:
E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 E = \sum\limits_{i=1}^k\sum\limits_{x \in C_i} ||x-\mu_i||_2^2 E=i=1∑kx∈Ci∑∣∣x−μi∣∣22
attention, μ j \mu_j μj is just the so-called centroids:
μ i = 1 ∣ C i ∣ ∑ x ∈ C i x \mu_i = \frac{1}{|C_i|}\sum\limits_{x \in C_i}x μi=∣Ci∣1x∈Ci∑x
It is worth noting that :
Inertia Suppose clustering is convex and isotropic (convex and isotropic), But it is not good for clustering slender clusters or irregular shape data ;
Inertia Not a standardized measure : We only know that a lower value is better , Zero is the best ;
Algorithm improvements
Kmeans ++
k The location of the initial centroids has a great influence on the final clustering results and running time , So we need to choose the right k A center of mass .K-Means++ The algorithm is right K-Means Optimization of the method of randomly initializing the centroid :
Randomly select a point from the set of input data points as the first clustering center \mu_1
For every point in the dataset x_i, Calculate the distance between it and the nearest cluster center in the selected cluster center
D ( x i ) = a r g    m i n ∣ ∣ x i − μ r ∣ ∣ 2 2      r = 1 , 2 , . . . k s e l e c t e d D(x_i) = arg\;min||x_i- \mu_r||2^2\;\;r=1,2,...k{selected} D(xi)=argmin∣∣xi−μr∣∣22r=1,2,...kselectedSelect a new data point as a new clustering center , The principle of choice is :D(x) Larger point , The probability of being selected as cluster center is high
repeat b and c Until you choose k A cluster centroid
Use this k A centroid is used as the initial centroid to run the standard K-Means Algorithm
elkan
In traditional K-Means In the algorithm, , In each iteration , To calculate the distance from all sample points to all centroids , This will be more time-consuming .elkan K-Means The algorithm is improved from this . Its goal is to reduce unnecessary distance calculation .elkan K-Means The sum of two sides is greater than or equal to the third side , And the triangle property that the difference between two sides is less than the third side , To reduce the calculation of distance . Use the two laws above ,elkan K-Means Compared with the traditional K-Means The iteration speed has been greatly improved . But if the characteristics of our sample are sparse , If there are missing values , This method is not used , Some distances cannot be calculated at this time , The algorithm cannot be used .
mini-batch
MiniBatch-KMeans yes KMeans A variant of the algorithm , It USES mini-batch To reduce computing time , Still trying to optimize the same objective function .mini-batch Is a subset of the input dataset , Random sampling in each training iteration . It greatly reduces the amount of computation required to converge to the local optimal value , And achieve roughly the same effect .
Algorithm implementation
In this article, we mainly rely on sklearn Package to implement kmeans Algorithm , Of course, we can directly look at the source code for the specific implementation ~ Let's first look at the constructor :
def __init__(self,
n_clusters=8, # That is, the theoretical part k value
init='k-means++', # Centroid initialization method
n_init=10, # Number of centroid initialization , The final result is the best one
max_iter=300, # Maximum number of iterations
tol=1e-4, # Tolerance , namely kmeans Conditions for convergence of operating criteria
precompute_distances='auto', # Whether it is necessary to calculate the distance in advance , And put it in memory
verbose=0, # Lengthy mode , Looking into the source code, you will find that it is related to the bottom of the operating system , Personally, I think it has nothing to do with the algorithm itself
random_state=None, # It's actually a seed , Changing parameters will be passed in check_random_state() function
copy_x=True, # When parallel computing , It has to be for True, Build for data copy
n_jobs=1, # Number of parallel computing processes ,-1 Tense means full cpu
algorithm='auto' # ‘auto’, ‘full’, ‘elkan’, among 'full’ To express with EM How to achieve , Traditional kmeans The algorithm calculates the distance
)
The above parameters can correspond to the theoretical part mentioned above one by one , In order to further understand, we continue to deepen , Look at one. Kmeans What properties and methods does the object have , Also look directly at the code :
#! /usr/bin/python
# _*_ coding: utf-8 _*_
__author__ = 'Jeffery'
import numpy as np
from sklearn.cluster import KMeans
data = np.random.rand(100, 3) # Generate a random data ,shape(100, 3)
estimator = KMeans(n_clusters=3,
init='k-means++',
n_init=10,
max_iter=300,
tol=1e-4,
precompute_distances='auto',
verbose=0,
random_state=None,
copy_x=False,
n_jobs=1,
algorithm='auto') # For non sparse data , Will choose elkan Algorithm
estimator.fit(data) # clustering
# -------------------- attribute -------------------------
# obtain estimator Properties set in constructor
print('n_clusters:', estimator.n_clusters)
print('init:', estimator.init)
print('max_iter:', estimator.max_iter)
print('tol:', estimator.tol)
print('precompute_distances:', estimator.precompute_distances)
print('verbose:', estimator.verbose)
print('random_state:', estimator.random_state)
print('copy_x:', estimator.copy_x)
print('n_jobs:', estimator.n_jobs)
print('algorithm:', estimator.algorithm)
print('n_init:', estimator.n_init)
# Other important attributes
print('n_iter_:', estimator.n_iter_) # The actual number of iterations
print('cluster_centers_:', estimator.cluster_centers_) # Get the result of clustering center
print('inertia_:', estimator.inertia_) # Get the sum of clustering criteria , The smaller the better.
print('labels_:', estimator.labels_) # Get the clustering label results
# -------------------- function -------------------------
print('get_params:', estimator.get_params(deep=True)) # And set_params() relative
# Let's not talk about the introduction here fit()、transform()、fit_transform()、fit_predict()、predict()、score() Such as function
# These functions are put in the case
Case study
This example comes from Official website , This example is intended to illustrate k-means Some inappropriate scenes : In the first three figures , The input data does not conform to k-means Some implicit assumptions generated , The result is an undesirable clustering result ; In the last figure ,k-means Return to intuition 、 Reasonable cluster , Although the size is uneven . This example is simple , But we must fully see kmeans The key to the application of , such as k The importance of selection 、 Limitations of clustering anisotropic data
#! /usr/bin/python
# _*_ coding: utf-8 _*_
__author__ = 'Jeffery'
__date__ = '2018/11/11 13:55'
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
plt.figure(figsize=(12, 12))
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# Incorrect number of clusters
y_pred = KMeans(n_clusters=2, random_state=random_state).fit_predict(X)
plt.subplot(221)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("Incorrect Number of Blobs")
# Anisotropicly distributed data
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
X_aniso = np.dot(X, transformation)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_aniso)
plt.subplot(222)
plt.scatter(X_aniso[:, 0], X_aniso[:, 1], c=y_pred)
plt.title("Anisotropicly Distributed Blobs")
# Different variance
X_varied, y_varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_varied)
plt.subplot(223)
plt.scatter(X_varied[:, 0], X_varied[:, 1], c=y_pred)
plt.title("Unequal Variance")
# Unevenly sized blobs
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
y_pred = KMeans(n_clusters=3,
random_state=random_state).fit_predict(X_filtered)
plt.subplot(224)
plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=y_pred)
plt.title("Unevenly Sized Blobs")
plt.show()

Write at the end of the article
If there is enough time ,K-means Will eventually converge , But this may be a local optimum , This largely depends on the initialization of the centroid ; in addition , For big data sets , You can do it first PCA Equal dimension reduction (PCA Please refer to Dimension reduction technology -PCA), Then clustering , To reduce the consumption of computing resources and possibly improve the clustering effect .
边栏推荐
- 【机器学习】层次聚类
- 网络数据包的封包格式
- Yuanqi Digitalization: existing mode or open source innovation Lixia action
- Qt creator 常用的17个快捷键
- SAP ABAP 解析 excel 文件的函数 TEXT_CONVERT_XLS_TO_SAP 单步执行分析
- Python predicts the model code demo of the next number through the first three numbers
- The difference between open and fopen
- 【Numpy学习记录】np.cov详解
- From scratch implement crnn using pytorch: read training data
- Introduction and simple application of CGI
猜你喜欢
from scratch implement crnn using pytorch :读取训练数据

A Beginner guide to Deep Learning based Semantic Segmentation using Keras

即刻报名|如何降低云上数据分析成本?

Industry analysis | logistics intercom

Teach you to upload NCBI data hand in hand, and you can learn it in the free course package!

pytorch实现 分组卷积 深度可分离卷积

MySQL 45 Lecture Notes - string prefix index & MySQL dirty page analysis

云原生 SIG 直播:关于 cni 与 hybridnet 核心技术分享 | 第 35 期
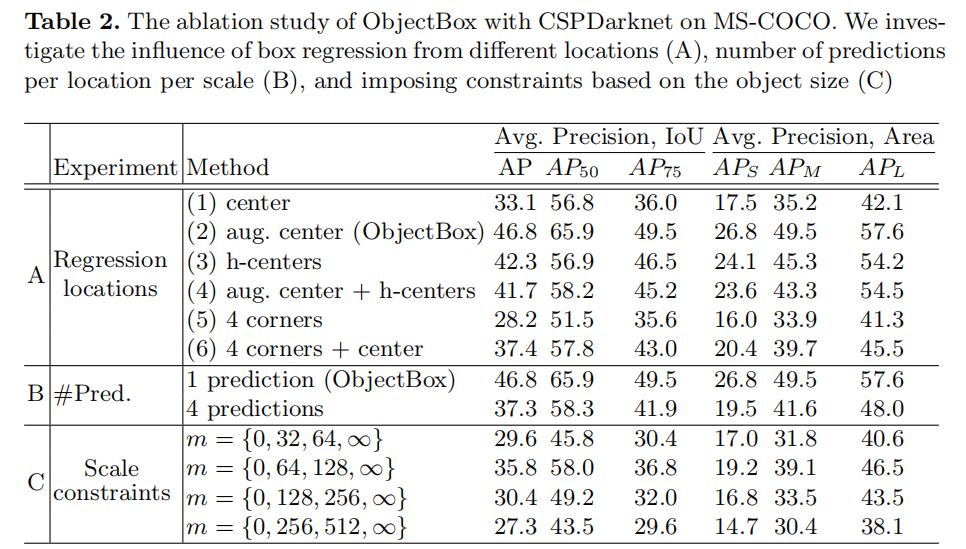
【论文笔记】ObjectBox: From Centers to Boxes for Anchor-Free Object Detection

Code representation pre training language model learning guide: principles, analysis and code
随机推荐
为配置SSL,自制CA证书
【无标题】
matplotlib. Pyplot interface summary
分页助手PageHelper的使用
Clear DNS cache on local computer + clear DNS cache on Browser
Opencv: how to remove the seal on the bill
Use of delete
Pytorch implementation of packet convolution depth separable convolution
Packet format of network packets
Introduction to pytorch - Implementation of simple linear functions
源启数字化:既有模式,还是开源创新?|砺夏行动
2019 Hangdian multi school sixth session 6641 (original 1008) TDL (regular question)
CodeQL使用流程
MySQL存储引擎大全
Mutex and smart pointer replace read-write lock
Introduction to pytorch 3 data types and functions
OpenCV:如何去除票据上的印章
即刻报名|如何降低云上数据分析成本?
C: File encryption
Mutex和智能指针替代读写锁