当前位置:网站首页>ORM初识和数据库操作
ORM初识和数据库操作
2022-07-21 11:51:00 【全栈程序员站长】
大家好,又见面了,我是你们的朋友全栈君。
ORM简介
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。简单的说,ORM是通过使用描述对象和数据库之间
映射的元数据,将程序中的对象自动持久化到关系数据库中。那么,到底如何实现持久化呢?一种简单的方案是采用硬编码方式,为每一种可能的数据库访问操作提供单独的方法。
这种方案存在以下不足:
1.持久化层缺乏弹性。一旦出现业务需求的变更,就必须修改持久化层的接口
2.持久化层同时与域模型与关系数据库模型绑定,不管域模型还是关系数据库模型发生变化,毒药修改持久化曾的相关程序代码,增加了软件的维护难度。
ORM提供了实现持久化层的另一种模式,它采用映射元数据来描述对象关系的映射,使得ORM中间件能在任何一个应用的业务逻辑层和数据库层之间充当桥梁。
Java典型的ORM中间件有:Hibernate,ibatis,speedframework。
ORM的方法论基于三个核心原则:
· 简单:以最基本的形式建模数据。
· 传达性:数据库结构被任何人都能理解的语言文档化。
· 精确性:基于数据模型创建正确标准化了的结构。 ORM概念及特点
让我们从O/R开始。字母O起源于"对象"(Object),而R则来自于"关系"(Relational)。几乎所有的程序里面,都存在对象和关系数据库。在业务逻辑层和用户界面层中,我们是面向对象的。
当对象信息发生变化的时候,我们需要把对象的信息保存在关系数据库中。
当你开发一个应用程序的时候(不使用O/R Mapping),你可能会写不少数据访问层的代码,用来从数据库保存,删除,读取对象信息,等等。你在DAL中写了很多的方法来读取对象数据,改变
状态对象等等任务。而这些代码写起来总是重复的。
ORM解决的主要问题是对象关系的映射。域模型和关系模型分别是建立在概念模型的基础上的。域模型是面向对象的,而关系模型是面向关系的。一般情况下,一个持久化类和一个表对应,类的
每个实例对应表中的一条记录,类的每个属性对应表的每个字段。
ORM技术特点:
1.提高了开发效率。由于ORM可以自动对Entity对象与数据库中的Table进行字段与属性的映射,所以我们实际可能已经不需要一个专用的、庞大的数据访问层。
2.ORM提供了对数据库的映射,不用sql直接编码,能够像操作对象一样从数据库获取数据。为什么用ORM
ORM是一种程序技术,用来实现面向对象编程语言里不同类型系统的数据之间的转换 。从效果上说,它其实是创建了一个可在编程语言里使用的——“虚拟对象数据库”ORM的作用
ORM它的作用是在关系型数据库和业务实体对象之间作一个映射,这样,我们在具体的操作业务对象的时候,就不需要再去和复杂的SQL语句打交道,只需简单的操作对象的属性和方法。ORM的优劣势
ORM的优势
ORM解决的主要问题是对象和关系的映射。它通常把一个类和一个表一一对应,类的每个实例对应表中的一条记录,类的每个属性对应表中的每个字段。
ORM提供了对数据库的映射,不用直接编写SQL代码,只需像操作对象一样从数据库操作数据。
让软件开发人员专注于业务逻辑的处理,提高了开发效率。ORM的劣势
ORM的缺点是会在一定程度上牺牲程序的执行效率。
ORM用多了SQL语句就不会写了,关系数据库相关技能退化...ORM总结
ORM只是一种工具,工具确实能解决一些重复,简单的劳动。这是不可否认的。
但我们不能指望某个工具能一劳永逸地解决所有问题,一些特殊问题还是需要特殊处理的。
但是在整个软件开发过程中需要特殊处理的情况应该都是很少的,否则所谓的工具也就失去了它存在的意义。映射关系
表名 --------------------》类名
字段--------------------》属性
表记录-----------------》类实例化对象 ORM的俩大功能
操作表:
- 创建表
- 修改表
- 删除表
操作数据行:
- 增删改查ORM利用pymysql第三方工具链接数据库
Django没办法帮我们创建数据库,只能我们创建完之后告诉它,让django去链接ORM链接数据库
创建表之前的准备工作
1、自己创建数据库
create database django;2、在Django项目的settings.py文件中,配置数据库连接信息:
# 修改django默认的数据库的sqlite3为mysql
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', #通过这个去链接mysql
'NAME': 'djangotsgl',
'USER':'root',
'PASSWORD':'123456',
'HOST':'localhost',
'PORT':'3306',
}
} 这样写上以后django会默认的就去链接数据库,这时你会看到报错了,那么解决的办法就是下面的这样
3、在项目文件夹中的–init–文件中写入:
import pymysql
pymysql.install_as_MySQLdb()4、创建数据库表(app/models.py)
models.py
class Book(models.Model): #必须要继承的
nid = models.AutoField(primary_key=True) #自增id(可以不写,默认会有自增id)
title = models.CharField(max_length=32)
publishDdata = models.DateField() #出版日期
author = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5,decimal_places=2) #一共5位,保留两位小数5.执行命令创建:(需要记住的!!!)
数据库迁移
python manage.py makemigrations 记录models.py中的改动,具体的记录在
python manage.py migrate 把相关的改动翻译成SQL语句并执行ORM单表操作
基本操作(单表操作)
# 增
#
# models.Tb1.objects.create(c1='xx', c2='oo') 增加一条数据,可以接受字典类型数据 **kwargs
# obj = models.Tb1(c1='xx', c2='oo')
# obj.save()
# 查
#
# models.Tb1.objects.get(id=123) # 获取单条数据,不存在则报错(不建议)
# models.Tb1.objects.all() # 获取全部
# models.Tb1.objects.filter(name='seven') # 获取指定条件的数据
# 删
#
# models.Tb1.objects.filter(name='seven').delete() # 删除指定条件的数据
# 改
# models.Tb1.objects.filter(name='seven').update(gender='0') # 将指定条件的数据更新,均支持 **kwargs
# obj = models.Tb1.objects.get(id=1)
# obj.c1 = '111'
# obj.save() # 修改单条数据View Code
进阶操作(双下划线操作)
# 获取个数
#
# models.Tb1.objects.filter(name='seven').count()
# 大于,小于
#
# models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值
# models.Tb1.objects.filter(id__gte=1) # 获取id大于等于1的值
# models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lte=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
# in
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
# isnull
# Entry.objects.filter(pub_date__isnull=True)
# contains
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven")
# range
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
# 其他类似
#
# startswith,istartswith, endswith, iendswith,
# order by
#
# models.Tb1.objects.filter(name='seven').order_by('id') # asc
# models.Tb1.objects.filter(name='seven').order_by('-id') # desc
# group by
#
# from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=1).values('id').annotate(c=Count('num'))
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id"
# limit 、offset
#
# models.Tb1.objects.all()[10:20]
# regex正则匹配,iregex 不区分大小写
#
# Entry.objects.get(title__regex=r'^(An?|The) +')
# Entry.objects.get(title__iregex=r'^(an?|the) +')
# date
#
# Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1))
# Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1))
# year
#
# Entry.objects.filter(pub_date__year=2005)
# Entry.objects.filter(pub_date__year__gte=2005)
# month
#
# Entry.objects.filter(pub_date__month=12)
# Entry.objects.filter(pub_date__month__gte=6)
# day
#
# Entry.objects.filter(pub_date__day=3)
# Entry.objects.filter(pub_date__day__gte=3)
# week_day
#
# Entry.objects.filter(pub_date__week_day=2)
# Entry.objects.filter(pub_date__week_day__gte=2)
# hour
#
# Event.objects.filter(timestamp__hour=23)
# Event.objects.filter(time__hour=5)
# Event.objects.filter(timestamp__hour__gte=12)
# minute
#
# Event.objects.filter(timestamp__minute=29)
# Event.objects.filter(time__minute=46)
# Event.objects.filter(timestamp__minute__gte=29)
# second
#
# Event.objects.filter(timestamp__second=31)
# Event.objects.filter(time__second=2)
# Event.objects.filter(timestamp__second__gte=31)View Code
其他操作(执行原生SQL)
# 执行原生SQL 1.执行自定义SQL # from django.db import connection, connections # cursor = connection.cursor() # cursor = connections['default'].cursor() # cursor.execute("""SELECT * from auth_user where id = %s""", [1]) # row = cursor.fetchone() 2.使用extra方法 # # extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) # Entry.objects.extra(where=['headline=%s'], params=['Lennon']) # Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) # Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) 3.使用raw方法 解释:执行原始sql并返回模型 说明:依赖model多用于查询 用法: book = Book.objects.raw("select * from hello_book") for item in book: print(item.title)https://www.cnblogs.com/413xiaol/p/6504856.html # F # # from django.db.models import F # models.Tb1.objects.update(num=F('num')+1) # Q # # 方式一: # Q(nid__gt=10) # Q(nid=8) | Q(nid__gt=10) # Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root') # 方式二: # con = Q() # q1 = Q() # q1.connector = 'OR' # q1.children.append(('id', 1)) # q1.children.append(('id', 10)) # q1.children.append(('id', 9)) # q2 = Q() # q2.connector = 'OR' # q2.children.append(('c1', 1)) # q2.children.append(('c1', 10)) # q2.children.append(('c1', 9)) # con.add(q1, 'AND') # con.add(q2, 'AND') # # models.Tb1.objects.filter(con)链表操作
创建表
书籍表:
书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);
一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
创建一对一的关系:OneToOne(“要绑定关系的表名”)
创建一对多的关系:ForeignKey(“要绑定关系的表名”)
创建多对多的关系:ManyToMany(“要绑定关系的表名”) 会自动创建第三张表
class Book(models.Model):
nid = models.AutoField(primary_key=True) # 自增id(可以不写,默认会有自增id)
title = models.CharField(max_length=32)
publishDdata = models.DateField() # 出版日期
price = models.DecimalField(max_digits=5, decimal_places=2) # 一共5位,保留两位小数
#一个出版社有多本书,关联字段要写在多的一方
# 不用命名为publish_id,因为django为我们自动就加上了_id
publish = models.ForeignKey("Publish") #foreignkey(表名)建立的一对多关系
# publish是实例对象关联的出版社对象
authorlist = models.ManyToManyField("Author") #建立的多对多的关系
def __str__(self): #__str__方法使用来吧对象转换成字符串的,你返回啥内容就打印啥
return self.title
class Publish(models.Model):
#不写id的时候数据库会自动给你增加自增id
name =models.CharField(max_length=32)
addr = models.CharField(max_length=32)
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
class AuthorDeital(models.Model):
tel = models.IntegerField()
addr = models.CharField(max_length=32)
author = models.OneToOneField("Author") #建立的一对一的关系View Code
注意:临时添加的字段,首先你得考虑之前的数据有没有。设置一个默认值。
wordNum = models.IntegerField(default=0)
通过logging可以查看翻译成的sql语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
} 注意事项:
1、 表的名称myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称
2、id 字段是自动添加的
3、对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
4、这个例子中的CREATE TABLE SQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。
5、定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加models.py所在应用的名称。
6、外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
字段选项
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的:
1)null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
(1)blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
(2)default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。
(3)primary_key
如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。
(4)unique
如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的
(5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,
默认的表单将是一个选择框而不是标准的文本框,而且这个选择框的选项就是choices 中的选项。
这是一个关于 choices 列表的例子:
YEAR_IN_SCHOOL_CHOICES = (
('FR', 'Freshman'),
('SO', 'Sophomore'),
('JR', 'Junior'),
('SR', 'Senior'),
('GR', 'Graduate'),
)
每个元组中的第一个元素,是存储在数据库中的值;第二个元素是在管理界面或 ModelChoiceField 中用作显示的内容。
在一个给定的 model 类的实例中,想得到某个 choices 字段的显示值,就调用 get_FOO_display 方法(这里的 FOO 就是 choices 字段的名称 )。例如:
from django.db import models
class Person(models.Model):
SHIRT_SIZES = (
('S', 'Small'),
('M', 'Medium'),
('L', 'Large'),
)
name = models.CharField(max_length=60)
shirt_size = models.CharField(max_length=1, choices=SHIRT_SIZES)
>>> p = Person(name="Fred Flintstone", shirt_size="L")
>>> p.save()
>>> p.shirt_size
'L'
>>> p.get_shirt_size_display()
'Large一旦你建立好数据模型之后,django会自动生成一套数据库抽象的API,可以让你执行关于表记录的增删改查的操作。
添加记录
一对多添加记录:
# 一对多的添加
# 方式一:如果是这样直接指定publish_id字段去添加值,前提是你的主表里面必须有数据
# 主表:没有被关联的(因为book表是要依赖于publish这个表的)也就是publish表
# 子表:关联的表
models.Book.objects.create(title="追风筝的人",publishDdata="2015-5-8",price="111",publish_id=1)
# 方式二:推荐
pub_obj = models.Publish.objects.filter(name="人民出版社")[0]
print(pub_obj)
models.Book.objects.create(title = "简爱",publishDdata="2000-6-6",price="222",publish=pub_obj)
# 方式三:save
pubObj= models.Publish.objects.get(name="人民出版社") #只有一个的时候用get,拿到的直接就是一个对象
bookObj = models.Book(title = "真正的勇士",publishDdata="2015-9-9",price="50",publish=pubObj)
bookObj.save()多对多添加记录:
书和作者是多对多的关系:一个书可以有多个作者,一个作者可以出版多本书
步骤:先找到书对象
再找到需要的作者对象
给书对象绑定作者对象(用add方法),也就是绑定多对多的关系
# 多对多的添加的两种方式
# 方式一:
# 先创建一本书:
pub_obj=models.Publish.objects.filter(name="万能出版社").first()
book_obj = models.Book.objects.create(title="醉玲珑",publishDdata="2015-4-10",price="222",publish=pub_obj)
# #通过作者的名字django默认找到id
haiyan_obj = models.Author.objects.filter(name="haiyan")[0]
egon_obj = models.Author.objects.filter(name="egon")[0]
xiaoxiao_obj = models.Author.objects.filter(name="xiaoxiao")[0]
# 绑定多对多的关系、
book_obj.authorlist.add(haiyan_obj, egon_obj, xiaoxiao_obj)
# 方式二=========,查出所有的作者
pub_obj = models.Publish.objects.filter(name="万能出版社").first()
book_obj = models.Book.objects.create(title="醉玲珑", publishDdata="2015-4-10", price="222", publish=pub_obj)
authers = models.Author.objects.all()
# #绑定多对多关系
book_obj.authorlist.add(*authers)解除绑定:remove: # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])
# 解除多对多的关系(remove)
book_obj=models.Book.objects.filter(title="醉玲珑").last() #找到书对象
authers=models.Author.objects.filter(id__lt=3) #找到符合条件的作者对象
book_obj.authorlist.remove(*authers) #因为清除的是多条,得加个*清除绑定:clear” #清空被关联对象集合。
# 清除关系方法(clear)
book_obj= models.Book.objects.filter(title="红楼梦")
for book_obj_item in book_obj:#把所有红楼梦的都给清空了
book_obj_item.authorlist.clear()总结:remove和clear的区别 remove:得吧你要清除的数据筛选出来,然后移除 clear:不用查,直接就把数据都清空了。 各有应用场景
三、基于对象的查询记录(相当于sql语句的where子查询)
一对一查询记录:author和authordetile是一对一的关系
正向查询(按字段author)
反向查询(按表名authordeital):因为是一对一的关系了,就不用_set了。
# 一对一的查询
# 正向查询:手机号为13245的作者的姓名
deital_obj = models.AuthorDeital.objects.filter(tel="13245").first()
print(deital_obj.author.name)
# 反向查询:查询egon的手机号
egon_obj = models.Author.objects.filter(name="egon").first()
print(egon_obj.authordeital.tel)一对多查询记录:
正向查询(按字段:publish):
反向查询(按表名:book_set):
# 正向查询:查询真正的勇士这本书的出版社的地址
book_obj = models.Book.objects.filter(title="真正的勇士")[0] # 找对象
print("======", book_obj.publish) # 拿到的是关联出版社的对象
print(book_obj.publish.addr)
# 反向查询:查询人民出版社出版过的所有的书的价格和名字
pub_obj = models.Publish.objects.filter(name="人民出版社")[0]
book_dic = pub_obj.book_set.all().values("price", "title")[0]
print(book_dic)
print(book_dic["price"])
# 查询 人民出版社出版过的所有书籍publish=models.Publish.objects.get(name="人民出版社") #get得到的直接是一个对象,不过get只能查看有一条记录的
book_list=publish.book_set.all() # 与人民出版社关联的所有书籍对象集合
forbook_obj inbook_list:
print(book_obj.title)
注意这里用for循环或是用values,vauleslist都是可以的。多对多查询记录:
正向查询(按字段authorlist)
反向查询(按表名book_set)
# 多对多的查询
# 正向查询:查询追风筝的人的这本书的所有的作者的姓名和年龄
book_obj = models.Book.objects.filter(title="红楼梦")[0]
print(book_obj.authorlist.all().values("name", "age")) # 这本书关联的所有作者对象的集合
# 反向查询:查询作者是haiyan的这个人出了哪几本书的信息
haiyan_obj = models.Author.objects.filter(name="haiyan")[0]
print("bookinfo====", haiyan_obj.book_set.all().first().title) # 与该作者关联的所有书对象的集合
return HttpResponse("ok")你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改: publish = ForeignKey(Blog, related_name=’bookList’),那么接下来就会如我们看到这般:
# 查询 人民出版社出版过的所有书籍
publish=Publish.objects.get(name="人民出版社")
book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合四、基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。(相当于用sql语句用join连接的方式,可以在settings里面设置,可查看sql语句)
一对多查询:
练习1、查询人民出版社出版过的所有的书的价格和名字
# 基于双下划线的方式查询1================一对多
# 第一种查法
ret = models.Publish.objects.filter(name="人民出版社").values("book__price","book__title")
print(ret)
# 第二种查法
ret2 = models.Book.objects.filter(publish__name="人民出版社").values("price","title")
print(ret2)练习2、查询linux这本书的出版社的地址:filer先过滤,,values显示要求的字段
第一种查法
ret = models.Book.objects.filter(title="linux").values("publish__addr")
print(ret)
第二种查法
ret2 = models.Publish.objects.filter(book__title="linux").values("addr")
print(ret2)多对多查询:
练习1、查询egon出过的所有书的名字
#方式一
ret = models.Author.objects.filter(name="egon").values("book__title")
print(ret)
#方式二:两种方式也就是逻辑不一样
ret2 = models.Book.objects.filter(authorlist__name="egon").values("title")
print(ret2)练习2、查询手机号以151开头的作者出版过的所有书的名称以及出版社的名称
# 方式一:
author_obj = models.AuthorDeital.objects.filter(tel__startswith="151").first()
print(author_obj.author.book_set.all().values("title","publish__name"))
# 方式二:
ret = models.Book.objects.filter(authorlist__author_deital__tel__startswith="151").values("title","publish__name")
print(ret)查看数据库的sql语句(加在settings.py)
查看数据库执行代码
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}聚合查询/分组查询
聚合查询
aggregate(*args, **kwargs),只对一个组进行聚合
from django.db.models import Avg,Sum,Count,Max,Min
# 1、查询所有图书的平均价格
print(models.Book.objects.all().aggregate(Avg("price")))aggregate()是QuerySet 的一个终止子句(也就是返回的不再是一个QuerySet集合的时候),意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
from django.db.models import Avg,Sum,Count,Max,Min
# 1、查询所有图书的平均价格
print(models.Book.objects.all().aggregate(avgprice = Avg("price")))如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
print(models.Book.objects.all().aggregate(Avg("price"),Max("price"),Min("price")))
#打印的结果是: {'price__avg': 174.33333333333334, 'price__max': Decimal('366.00'), 'price__min': Decimal('12.00')}分组查询
annotate():为QuerySet中每一个对象都生成一个独立的汇总值。是对分组完之后的结果进行的聚合
1、统计每一本书的作者个数
# 方式一:
print(models.Book.objects.all().annotate(authorNum = Count("authorlist__name")).values("authorNum"))
# 方式二:
booklist =models.Book.objects.all().annotate(authorNum=Count("authorlist__name"))
for book_obj in booklist:
print(book_obj.title,book_obj.authorNum)2、统计每一个出版社最便宜的书
# 2、统计每一个出版社的最便宜的书
# 方式一:
print(models.Book.objects.values("publish__name").annotate(nMinPrice=Min('price'))) 注意:values内的字段即group by的字段,,也就是分组条件
# 方式二:
print(models.Publish.objects.all().annotate(minprice=Min("book__price")).values("name","minprice"))
# 方式三
publishlist = models.Publish.objects.annotate(minprice = Min("book__price"))
for publish_obj in publishlist:
print(publish_obj.name,publish_obj.minprice)3、统计每一本以py开头的书籍的作者个数:print(models.Book.objects.filter(title__startswith="py").annotate(authNum = Count("authorlist__name")).values("authNum"))(4)统计不止一个作者的图书:print(models.Book.objects.annotate(num_authors=Count('authorlist__name')).filter(num_authors__gt=1).values("title","num_authors"))(5)根据一本图书作者数量的多少对查询集QuerySet进行排序:print(models.Book.objects.all().annotate(authorsNum=Count("authorlist__name")).order_by("authorsNum"))(6)查询各个作者出的书的总价格: # 方式一
print(models.Author.objects.all().annotate(priceSum = Sum("book__price")).values("name","priceSum"))
# 方式二
print(models.Book.objects.values("authorlist__name").annotate(priceSum=Sum("price")).values("authorlist__name","priceSum"))F/查询Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
1、查看评论数大于阅读数的书 from django.db.models import F,Q
print(models.Book.objects.filter(commentNum__gt=F("readNum")))2、修改操作也可以使用F函数,比如将id大于1的所有的书的价格涨价100元print(models.Book.objects.filter(nid__gt=1).update(price=F("price")+100))3、Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。# 查询评论数大于收藏数2倍的书籍
models.Book.objects.filter(commnetNum__lt=F('keepNum')*2)Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
1、查询id大于1并且评论数大于100的书 print(models.Book.objects.filter(nid__gt=1,commentNum__gt=100))
print(models.Book.objects.filter(nid__gt=1).filter(commentNum__gt=100))
print(models.Book.objects.filter(Q(nid__gt=1)&Q(commentNum__gt=100)))2、查询评论数大于100或者阅读数小于200的书print(models.Book.objects.filter(Q(commentNum__gt=100)|Q(readNum__lt=200)))
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。3、查询年份等于2017年或者价格大于200的书 print(models.Book.objects.filter(Q(publishDdata__year=2017)|Q(price__gt=200)))4、查询年份不是2017年或者价格大于200的书print(models.Book.objects.filter(~Q(publishDdata__year=2017)&Q(price__gt=200)))注意:
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将”AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=models.Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017),
title__icontains="python"
)发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/124472.html原文链接:https://javaforall.cn
边栏推荐
- 找鞍点
- JS how to control the position of the scroll bar of the whole page
- [comprehensive pen test] difficulty 3.5/5, multi solution popular binary tree pen test
- Import and export of vmvare virtual machine (OVA format)
- Google浏览器另存为图片出现假死现象
- 风控文章资源合集
- Fake death occurs when Google browser is saved as an image
- 8.==与===?
- tabbar搭建
- Binary search tree and bidirectional linked list
猜你喜欢

814. Binary tree pruning: simple recursive problem
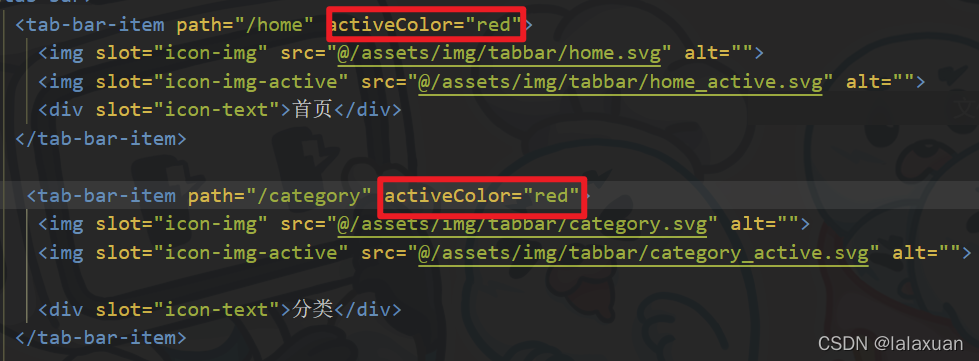
tabbar搭建

Latex多个子图进行组合

Mobile end Foundation

Judge whether to balance binary tree

Web server

Determine whether binary search tree

软件供应链攻击的新形式

The MathType DLL cannot be found.Please reinstall Math问题已解决

XXL job (2.3.0) distributed task bean mode, glue shell scheduling practice, source code debug
随机推荐
(resolved) for camerads, HR = m_ pGraph-> Connect(m_pCameraOutput, m_pGrabberInput); Solutions to implementation failures
Thesis reading: dialogpt
Word2vec (II)_ Implementation based on negative sampling method
Instant retail Three Kingdoms kill: meituan replenishment, Alibaba collaboration, jd.com drainage
5.引用类型和值类型作为函数参数?
6.ES5新增的数组的方法?
8.==与===?
Fake death occurs when Google browser is saved as an image
. Replacewith() can only work once
自动编码器的相关内容
Wuxi launched a major investigation of potential food safety hazards in Pizza Hut stores in the city
4.基本类型和引用类型?
How to use the download tool proayee down
js实现progress-steps(小练习)
登陆状态如何管理?登录流程?
下载工具-谷歌插件 tampermonkey 和 greasyfork
Relative entropy, information entropy and cross entropy
首发!这份字节大佬亲码算法面试大厂进阶宝典,让你轻松刷爆LeetCode!
Reentrant read write lock feature summary of reentrantreadwritelock
Interview must ask: from entering URL to page display, what happened? (detailed and easy to understand, organized and easy to remember)