当前位置:网站首页>B tree and b+ tree hash index
B tree and b+ tree hash index
2022-07-22 07:02:00 【It could be something else】
B Trees
As we saw earlier , Although balanced binary tree has the characteristics of quick insertion and deletion of linked list , It also has the advantage of fast array search , But this is not the most suitable data structure for disk reading and writing .
in other words , We need to find such a data structure , Can effectively control the tree height , So let's turn a binary tree into m Fork tree , This is the data structure shown in the figure below :B Trees .
B A tree is such a data structure :
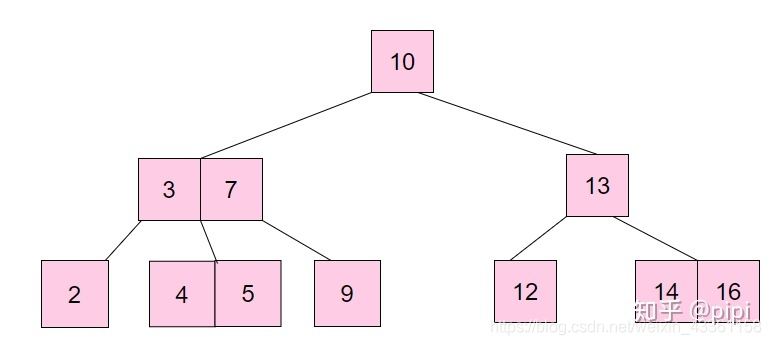
The root node has at least two children ;
Each intermediate node contains k-1 Elements and k Child nodes , among m/2 <= k <= m;
Every leaf node contains k-1 Elements , among m/2 <= k <= m;
All leaf nodes are on the same layer ;
The keywords in each node are arranged from small to large , And when the child of the node is a non leaf node , The k-1 An element is exactly k The partition of the value range of the elements contained in the child node .
You can see ,B In the premise of preserving the binary tree pre partition range to improve the query efficiency , Do the following optimization :
The binary tree becomes m Fork tree , This m Can be adjusted according to the size of a single page , So that a page can store more data , Read a page from the disk can read more data , Random IO Fewer times , Greatly improve efficiency .
But we see that , We can only query the whole table through the middle order traversal , When doing range queries , It may be necessary to backtrack in the middle order .
Constantly optimizing B Trees :B+ Trees
Based on the above defects , A new kind of optimization has been born B Trees of trees :B+ Trees

B+ Trees in B The following optimizations are added to the tree
Leaf nodes add pointers to connect , That is, the leaf nodes form a linked list ;
Non leaf nodes only store keywords key, No more data storage , Only store data in leaf nodes ;
explain : The advantage of two-way list connection is that any node in the list can find other nodes specified in the list by traversing forward or backward .
The advantage of this is
1. The range query can be traversed orderly by accessing the linked list of leaf nodes , It is no longer necessary to access the node in the middle order backtracking .
2. Non leaf nodes only store keywords key, On the one hand, this structure is equivalent to dividing more areas , Speed up the query speed , On the other hand, it means that the size of a single index value becomes smaller , The same page can store more keywords , Read a single page to get more keywords , The scope of search has become larger , relative IO The number of reading and writing decreased .
Some summary
B+ Trees and B The difference between trees ?
1.B Both non leaf nodes and leaf nodes store data , So when querying data , The best time complexity is O(1), The worst is O(log n).
B+ Trees store data only at leaf nodes , Non leaf nodes store keywords , And the keywords of different non leaf nodes may be repeated , So when querying data , The time complexity is fixed to O(log n).
2.B+ The leaf nodes of trees are connected with each other by linked list , Therefore, only scanning the linked list of leaf nodes can complete a traversal operation ,B Trees can only be traversed through the middle order .
Why? B+ Tree ratio B Trees are more suitable for database indexes ?
B+ Trees are more adaptable to the characteristics of disk , comparison B There are fewer trees I/O The number of times you read and write . Because the index file is very large, the index file is stored on disk ,B+ The non leaf nodes of the tree only store keywords, not data , As a result, a single page can store more keywords , That is to say, the more keywords need to be searched when reading into memory at one time , Random disk I/O The number of reads is relatively reduced .
B+ The query efficiency of tree is compared with B Trees are more stable , Because the data only exists on the leaf node , So the search efficiency is fixed to O(log n).
B+ The leaf nodes of a tree are connected in order by a linked list , So to scan all the data, you only need to scan the leaf node once , Easy to scan database and range query ;B Trees also store data because they are not leaf nodes , Therefore, we can only scan in order by traversing the middle order . in other words , For range queries and ordered traversal ,B+ More efficient trees .
B+tree Index and hash Indexes
because Hash The bottom layer of the index is the hash table , Hash table is a kind of key-value Structure of stored data , So there is no sequential relationship between multiple data in the storage relationship , therefore , For interval query, it is impossible to query directly through index , You need a full scan . therefore , Hash index is only applicable to the scenario of equivalent query . and B+ Tree is a multi-channel balanced query tree , So his nodes are natural and orderly ( The left child node is smaller than the parent node 、 The parent node is smaller than the right child ), Therefore, full table scanning is not necessary for range query .
difference :
Hash index is suitable for equivalent query , But we can't do range query
Hash index can't use index to complete sorting
Hash index does not support the leftmost matching rule of multi column union index
If there are a lot of duplicate key values , Hash indexing is inefficient , Because there is a hash collision problem
边栏推荐
猜你喜欢







随机推荐
面试题 01.02. 判定是否互为字符重排
输入一个URL到这个页面呈现出来,这个过程发生了什么?
1024节日快乐
C语言基础练习题
Qt之生成连接库
【数学基础】 foundation of mathematics :Jensen不等式
flask - { “message“: “Failed to decode JSON object: Expecting value: line 1 column 1 (char 0)“ }
How can elastic group by intercepting the values of fields?
Matlab写入excel-字符串与数字合并
EF linq杂记
接口与抽象类
微信小程序列表(数据渲染之列表渲染)
ENVI shp转roi并对栅格进行掩膜提取
Qt在Win10下嵌入记事本
【数学基础】 foundation of mathematics :拉格朗日优化和对偶
IDEA SSH 工具远程链接失败
容器与容器 & 容器与主机 - 通过ssh协议互联(多节点、跨主机)
709. 转换成小写字母
Sword finger offer 17 Print from 1 to the maximum n digits (large number problem)
EF杂项