当前位置:网站首页>欠拟合与过拟合 (正则化)
欠拟合与过拟合 (正则化)
2022-07-22 04:46:00 【Zhichao_97】
学习B站课程(【北京大学】Tensorflow2.0_哔哩哔哩_bilibili)所做的笔记。
目录
一、欠拟合与过拟合示意图:

二、欠拟合与过拟合的解决方法
欠拟合的解决方法:
1.增加输入的特征项
2.增加网络参数
3.减少正则化参数
过拟合的解决方法:
1.数据清洗
2.增大数据集
3.采用正则化
4.增大正则化参数
三、正则化缓解过拟合
正则化是在损失函数中引入模型复杂度指标,利用给W加权值,弱化了训练数据的噪声(一般不正则化b)
loss = loss(y与y_)+REGULARIZER*loss(w)loss():模型中所有参数的损失函数,如:交叉熵,均方误差
REGULARIZER:用超参数REGULARIZER给出参数w在总loss中的比例,即正则化的权重
w:需要正则化的参数
四、正则化的选择
1.L1正则化大概率会使很多参数变为0,因此该方法可通过稀疏参数,即减少参数的数量,降低复杂度。
2.L2正则化会使参数很接近0但不为0,因此该方法可通过减少参数值的大小降低复杂度。
五、代码
代码1:(加入L2正则化前)
(dot.csv:正则化数据集dot.csv_正则化数据集-其它文档类资源-CSDN下载
或:https://pan.baidu.com/s/19XC28Hz_TwnSQeuVifg1UQ 提取码:mocm,在class2里)
# 导入所需模块
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
# 读入数据/标签 生成x_train y_train
df = pd.read_csv('dot.csv')
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df['y_c'])
x_train = np.vstack(x_data).reshape(-1, 2)
y_train = np.vstack(y_data).reshape(-1, 1)
Y_c = [['red' if y else 'blue'] for y in y_train]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型问题报错
x_train = tf.cast(x_train, tf.float32)
y_train = tf.cast(y_train, tf.float32)
# from_tensor_slices函数切分传入的张量的第一个维度,生成相应的数据集,使输入特征和标签值一一对应
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
# 生成神经网络的参数,输入层为2个神经元,隐藏层为11个神经元,1层隐藏层,输出层为1个神经元
# 用tf.Variable()保证参数可训练
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[11]))
w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.constant(0.01, shape=[1]))
lr = 0.005 # 学习率
epoch = 800 # 循环轮数
# 训练部分
for epoch in range(epoch):
for step, (x_train, y_train) in enumerate(train_db):
with tf.GradientTape() as tape: # 记录梯度信息
h1 = tf.matmul(x_train, w1) + b1 # 记录神经网络乘加运算
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2) + b2
# 采用均方误差损失函数mse = mean(sum(y-out)^2)
loss = tf.reduce_mean(tf.square(y_train - y))
# 计算loss对各个参数的梯度
variables = [w1, b1, w2, b2]
grads = tape.gradient(loss, variables)
# 实现梯度更新
# w1 = w1 - lr * w1_grad tape.gradient是自动求导结果与[w1, b1, w2, b2] 索引为0,1,2,3
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
# 每20个epoch,打印loss信息
if epoch % 20 == 0:
print('epoch:', epoch, 'loss:', float(loss))
# 预测部分
print("*******predict*******")
# xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成间隔数值点
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# 将xx , yy拉直,并合并配对为二维张量,生成二维坐标点
grid = np.c_[xx.ravel(), yy.ravel()]
grid = tf.cast(grid, tf.float32)
# 将网格坐标点喂入神经网络,进行预测,probs为输出
probs = []
for x_test in grid:
# 使用训练好的参数进行预测
h1 = tf.matmul([x_test], w1) + b1
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2) + b2 # y为预测结果
probs.append(y)
# 取第0列给x1,取第1列给x2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
# probs的shape调整成xx的样子
probs = np.array(probs).reshape(xx.shape)
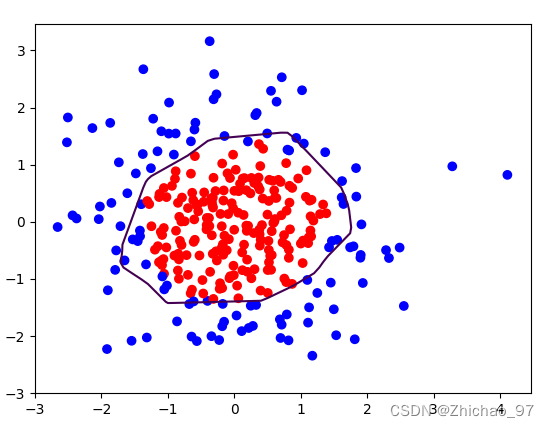
plt.scatter(x1, x2, color=np.squeeze(Y_c)) # squeeze去掉纬度是1的纬度,相当于去掉[['red'],[''blue]],内层括号变为['red','blue']
# 把坐标xx yy和对应的值probs放入contour函数,给probs值为0.5的所有点上色 plt.show()后 显示的是红蓝点的分界线
plt.contour(xx, yy, probs, levels=[.5])
plt.show()
# 读入红蓝点,画出分割线,不包含正则化
# 不清楚的数据,建议print出来查看
效果:

代码2:(加入L2正则化后)
# 导入所需模块
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
# 读入数据/标签 生成x_train y_train
df = pd.read_csv('dot.csv')
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df['y_c'])
x_train = x_data
y_train = y_data.reshape(-1, 1)
Y_c = [['red' if y else 'blue'] for y in y_train]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型问题报错
x_train = tf.cast(x_train, tf.float32)
y_train = tf.cast(y_train, tf.float32)
# from_tensor_slices函数切分传入的张量的第一个维度,生成相应的数据集,使输入特征和标签值一一对应
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
# 生成神经网络的参数,输入层为4个神经元,隐藏层为32个神经元,2层隐藏层,输出层为3个神经元
# 用tf.Variable()保证参数可训练
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[11]))
w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.constant(0.01, shape=[1]))
lr = 0.005 # 学习率为
epoch = 800 # 循环轮数
# 训练部分
for epoch in range(epoch):
for step, (x_train, y_train) in enumerate(train_db):
with tf.GradientTape() as tape: # 记录梯度信息
h1 = tf.matmul(x_train, w1) + b1 # 记录神经网络乘加运算
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2) + b2
# 采用均方误差损失函数mse = mean(sum(y-out)^2)
loss_mse = tf.reduce_mean(tf.square(y_train - y))
# 添加l2正则化
loss_regularization = []
# tf.nn.l2_loss(w)=sum(w ** 2) / 2
loss_regularization.append(tf.nn.l2_loss(w1))
loss_regularization.append(tf.nn.l2_loss(w2))
# 求和
# 例:x=tf.constant(([1,1,1],[1,1,1]))
# tf.reduce_sum(x)
# >>>6
loss_regularization = tf.reduce_sum(loss_regularization)
loss = loss_mse + 0.03 * loss_regularization # REGULARIZER = 0.03
# 计算loss对各个参数的梯度
variables = [w1, b1, w2, b2]
grads = tape.gradient(loss, variables)
# 实现梯度更新
# w1 = w1 - lr * w1_grad
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
# 每200个epoch,打印loss信息
if epoch % 20 == 0:
print('epoch:', epoch, 'loss:', float(loss))
# 预测部分
print("*******predict*******")
# xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成间隔数值点
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# 将xx, yy拉直,并合并配对为二维张量,生成二维坐标点
grid = np.c_[xx.ravel(), yy.ravel()]
grid = tf.cast(grid, tf.float32)
# 将网格坐标点喂入神经网络,进行预测,probs为输出
probs = []
for x_predict in grid:
# 使用训练好的参数进行预测
h1 = tf.matmul([x_predict], w1) + b1
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2) + b2 # y为预测结果
probs.append(y)
# 取第0列给x1,取第1列给x2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
# probs的shape调整成xx的样子
probs = np.array(probs).reshape(xx.shape)
plt.scatter(x1, x2, color=np.squeeze(Y_c))
# 把坐标xx yy和对应的值probs放入contour函数,给probs值为0.5的所有点上色 plt.show()后 显示的是红蓝点的分界线
plt.contour(xx, yy, probs, levels=[.5])
plt.show()
# 读入红蓝点,画出分割线,包含正则化
# 不清楚的数据,建议print出来查看
效果:
边栏推荐
- 【Leetcode数组--排序+辗转相除法最大公约数】6122.使数组可以被整除的最少删除次数
- AT4379 [AGC027E] ABBreviate
- Win10 系统一天蓝屏好多次,怎么解决?
- LeetCode 每日一题——814. 二叉树剪枝
- Inventory of e-mail security incidents in China in the first half of 2022
- Diversified distribution methods of NFT
- Glide source code analysis
- Binary tree OJ question, IO question
- Jincang database kmonitor user guide --3. deployment
- UE4 将蓝图写在Actor类里面 实现复用
猜你喜欢
Random forest learning notes

解析优化机器人课程体系与教学策略

ECCV 2022 | 修正FPN帶來的大目標性能損害:You Should Look at All Objects
![[leetcode array -- sorting + rolling division maximum common divisor] 6122. The minimum number of deletions that make the array divisible](/img/75/a1c2781ab259336411a3351ae7fc0e.png)
[leetcode array -- sorting + rolling division maximum common divisor] 6122. The minimum number of deletions that make the array divisible

Diversified distribution methods of NFT

UE4 植被工具的使用

The Prospectus has written "yuancosmos" 318 times! Feitian Yundong fights Hong Kong stocks again "yuancosmos first share"“

High number_ Chapter 3 multiple integration

复杂网络建模(网络鲁棒性)

PXE network installation
随机推荐
ECCV 2022 | 修正FPN带来的大目标性能损害:You Should Look at All Objects
JVM: parental delegation mechanism for class loading
左耳朵耗子:云原生时代的开发者应具备这5大能力
[ARC116F] Deque Game
Operation tutorial: UOB camera registers the detailed configuration of easycvr platform through gb28181 protocol
立即执行函数 分号问题
模板学堂丨JumpServer安全运维审计大屏
toString()及重写的作用与应用
mysql 数据库列拼接查询写法
How to configure webrtc protocol for low latency playback on easycvr platform v2.5.0 and above?
CF1635F Closest Pair
C language program practice - (write a function, its prototype is int continumax (char *outputstr, char *intputstr))
UE4 用灰度图构建地形
ECCV 2022 | 修正FPN帶來的大目標性能損害:You Should Look at All Objects
正则表达式相关
QDataStream
MySQL查询计划key_len如何计算
UE4 键盘按键实现开关门
IBM的免费机器怎么装宝塔
Jincang database kmonitor user guide --3. deployment