当前位置:网站首页>Common algorithm interview has been out! Machine learning algorithm interview - KDnuggets
Common algorithm interview has been out! Machine learning algorithm interview - KDnuggets
2020-11-06 01:20:00 【On jdon】
If the common algorithm is the common programmer's necessary knowledge , So is a more practical machine learning algorithm ? Or is it a necessary knowledge for data scientists ?
In preparing for an interview in Data Science , It is necessary to have a clear understanding of the various machine learning models - Give a brief description of each ready-made model . ad locum , We summarize various machine learning models by highlighting the main points , To help you communicate complex models .
Linear regression
Linear regression involves the use of the least square method to find “ Best fit line ”. The least squares method involves finding a linear equation , The equation minimizes the sum of squares of residuals . The residual is equal to the actual negative predictive value .
for instance , The red line is a better fit than the green line , Because it's closer to the point , So the residuals are small .
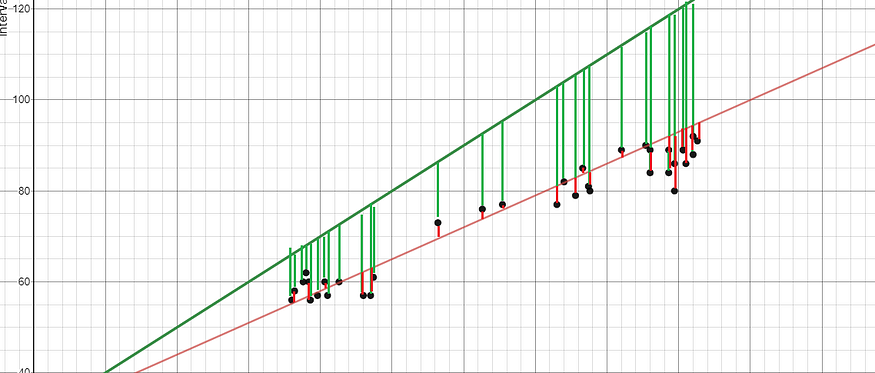
The picture was created by the author .
Ridge Return to
Ridge Return to ( Also known as L2 Regularization ) It's a regression technique , A small amount of deviation can be introduced to reduce over fitting . It works by minimizing the square of residuals And plus Penalty points to achieve this goal , The penalty is equal to λ Times the slope squared .Lambda It means the severity of the punishment .
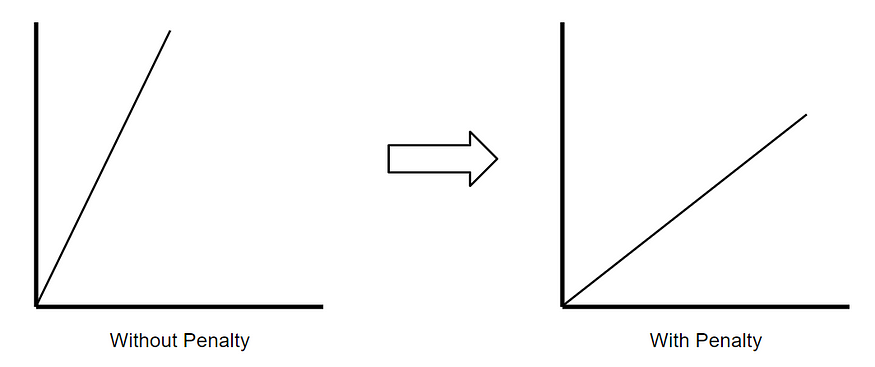
The picture was created by the author .
If there is no punishment , Then the slope of the best fit line becomes steeper , That means it's good for X More sensitive to subtle changes in . By introducing punishment , Best fit line pairs X It becomes less sensitive . Back of the ridge return .
Lasso Return to
Lasso Return to , Also known as L1 Regularization , And Ridge Return to similar . The only difference is , The penalty is calculated using the absolute value of the slope .
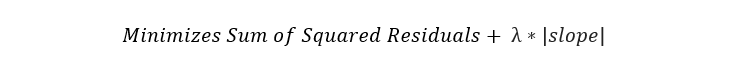
Logical regression
Logistic Regression is a classification technique , You can also find “ The most suitable straight line ”. however , Unlike linear regression , In linear regression , Use the least square to find the best fit line , Logistic regression uses maximum likelihood to find the best fit line ( The logic curve ). This is because y Value can only be 1 or 0. watch StatQuest In the video , Learn how to calculate the maximum likelihood .
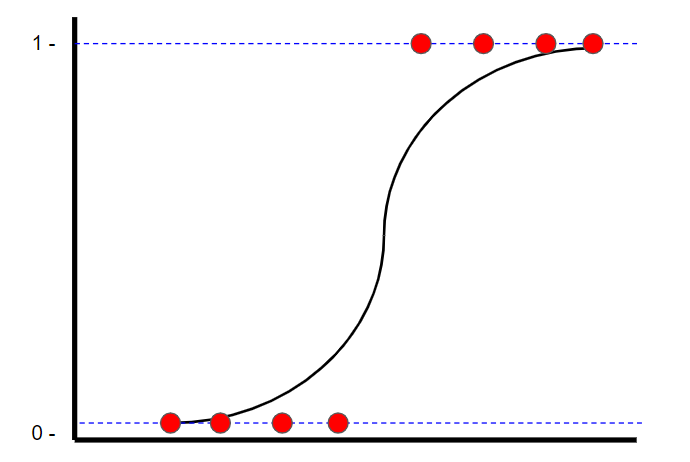
The picture was created by the author .
K Nearest neighbor
K Nearest neighbor is a classification technique , Classify the new samples by looking at the nearest classification point , So called “ K lately ”. In the following example , If k = 1, Then unclassified points are classified as blue dots .
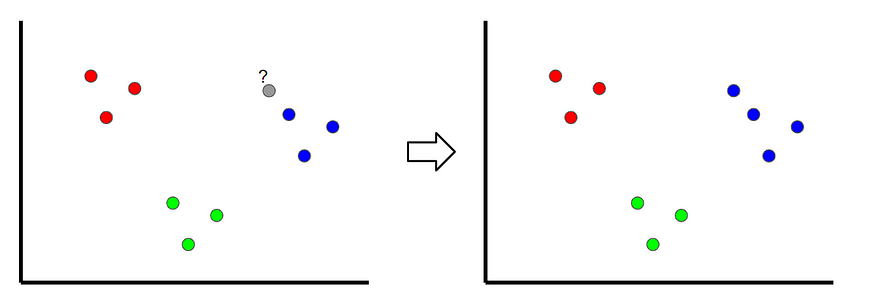
The picture was created by the author .
If k The value of is too low , There may be outliers . however , If it's too high , It is possible to ignore classes with only a few samples .
Naive Bayes
Naive Bayes classifier is a classification technique inspired by Bayes theorem , The following equation is stated :
Because of naive assumptions ( Hence the name ), Variables are independent in the case of a given class , So it can be rewritten as follows P(X | y):
Again , Because we have to solve y, therefore P(X) It's a constant , This means that we can remove it from the equation and introduce proportionality .
therefore , Each one y The probability of value is calculated as given y Conditional probability of x n The product of the .
Support vector machine
Support vector machine is a classification technique , We can find the best boundary called hyperplane , This boundary is used to separate different categories . Find hyperplanes by maximizing the margin between classes .
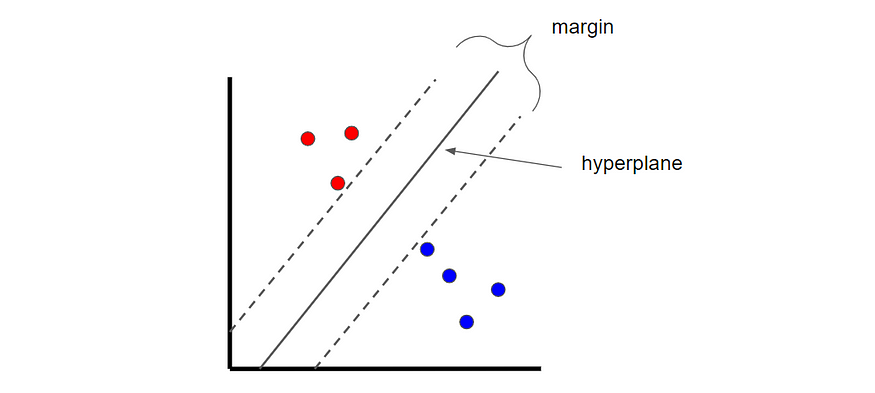
The picture was created by the author .
Decision tree
Decision tree is essentially a series of conditional statements , These conditional statements determine the path taken by the sample before it reaches the bottom . They are intuitive and easy to build , But it's often inaccurate .
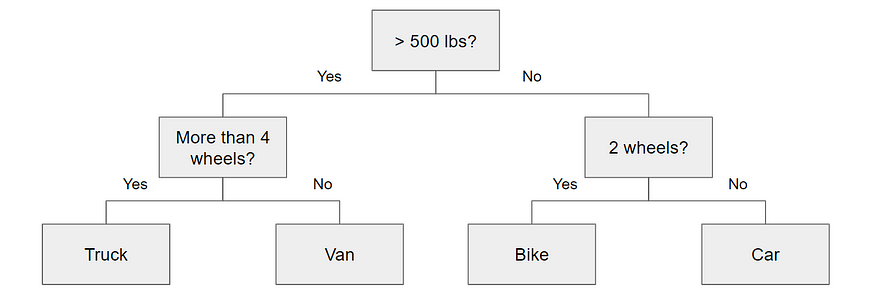
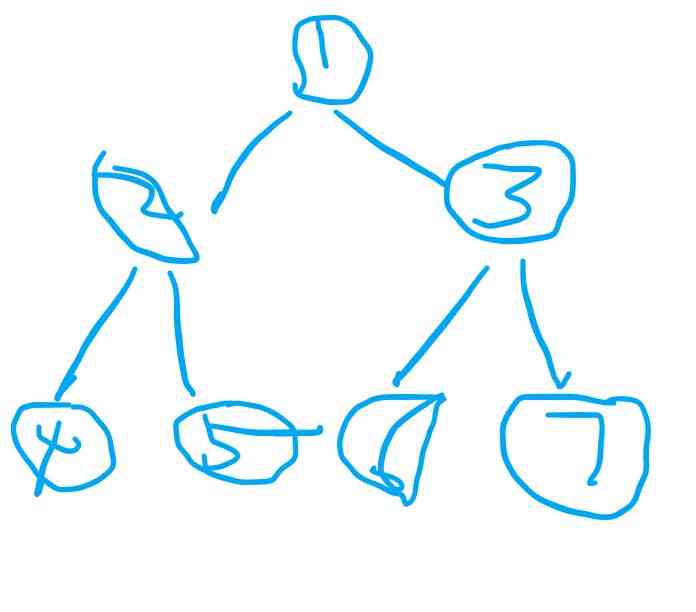
Random forests
Random forest is an integrated technology , This means that it combines multiple models into one model to improve its predictive power . say concretely , It uses bootstrap data sets and random subsets of variables ( Also known as bagging ) Thousands of smaller decision trees have been built . With thousands of smaller decision trees , Random forest use “ The majority wins ” Model to determine the value of the target variable .

for example , If we create a decision tree , The third decision tree , It will predict 0. however , If we rely on all 4 A decision tree model , Then the predicted value will be 1. This is the power of random forests .
AdaBoost
AdaBoost It's an enhancement algorithm , Be similar to “ Random forests ”, But there are two important differences :
- AdaBoost It's not usually made up of trees , It's a forest of stumps ( A stump is a tree with only one node and two leaves ).
- The decision of each stump has a different weight in the final decision . The total error is small ( High accuracy ) The stump has a higher voice .
- The order in which the stumps are created is important , Because each subsequent stump emphasizes the importance of samples that were not correctly classified in the previous stump .
Gradient rise
Gradient Boost And AdaBoost similar , Because it can build multiple trees , Each of these trees was built from the previous tree . And AdaBoost You can build stumps differently ,Gradient Boost Can be built, usually with 8 to 32 A leafy tree .
what's more ,Gradient Boost And AdaBoost The difference is in the way decision trees are constructed . Gradient enhancement starts with the initial prediction , It's usually the average . then , The decision tree is constructed based on the residuals of samples . By using the initial prediction + The learning rate is multiplied by the result of the residual tree to make a new prediction , Then repeat the process .
XGBoost
XGBoost Essentially with Gradient Boost identical , But the main difference is how to construct the residual tree . Use XGBoost, The residual tree can be determined by calculating the similarity score between the leaf and the previous node , To determine which variables are used as roots and nodes .
版权声明
本文为[On jdon]所创,转载请带上原文链接,感谢
边栏推荐
- Working principle of gradient descent algorithm in machine learning
- hadoop 命令总结
- Use of vuepress
- This article will introduce you to jest unit test
- Python3 e-learning case 4: writing web proxy
- Vue 3 responsive Foundation
- A debate on whether flv should support hevc
- 從小公司進入大廠,我都做對了哪些事?
- Basic principle and application of iptables
- Summary of common algorithms of binary tree
猜你喜欢




随机推荐
html
Python自动化测试学习哪些知识?
做外包真的很难,身为外包的我也无奈叹息。
Process analysis of Python authentication mechanism based on JWT
Use of vuepress
采购供应商系统是什么?采购供应商管理平台解决方案
Network security engineer Demo: the original * * is to get your computer administrator rights! 【***】
2019年的一个小目标,成为csdn的博客专家,纪念一下
C language 100 question set 004 - statistics of the number of people of all ages
H5 makes its own video player (JS Part 2)
Asp.Net Core學習筆記:入門篇
Aprelu: cross border application, adaptive relu | IEEE tie 2020 for machine fault detection
你的财务报告该换个高级的套路了——财务分析驾驶舱
选择站群服务器的有哪些标准呢?
DRF JWT authentication module and self customization
Menu permission control configuration of hub plug-in for azure Devops extension
Classical dynamic programming: complete knapsack problem
PLC模拟量输入和数字量输入是什么
Keyboard entry lottery random draw
比特币一度突破14000美元,即将面临美国大选考验