当前位置:网站首页>c语言进阶篇:数据的存储(深度剖析-整型)
c语言进阶篇:数据的存储(深度剖析-整型)
2022-07-21 07:23:00 【虎太郎的继承】
前言:
这篇是对数据类型的介绍以及整型在内存存储,希望能够对大家有所提升!
一、数据类型介绍
类型的意义:
- 使用这个类型开辟内存空间的大小(大小决定了使用范围)
- 如何看待内存空间的视角
基本归类:
1.整型家族:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
2.浮点数家族
float
double
3.构造类型:
//数组类型
//结构体类型 struct
//枚举类型 enum
//联合类型 union
4.指针类型:
int *pi;
char *pc;
float* pf;
void* pv;
5.空类型
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
二、整形在内存中的存储
我们知道一个变量的创建是需要开辟空间的,空间的大小是根据不同的类型而定的。可是数据在所开辟的内存中到底是如何存储的呢?
例如:
int a = 20;
我们只知道为a分配了四个字节大小的空间,并不知道其内存到底是如何存储的。
下面我们来了解一下:
整型在内存中的存储
数据在内存中是以二进制的形式存储的。
整数二进制有三种表示形式:原码、补码、反码
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位正数的原、反、补码都相同。
原码:
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码:
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码:
反码+1就得到补码。
对于整数来说
正整数的原码、反码、补码相同;负整数的原码、反码、补码需要通过进行计算得到。
数据存放内存中其实存放的是补码。
为什么?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
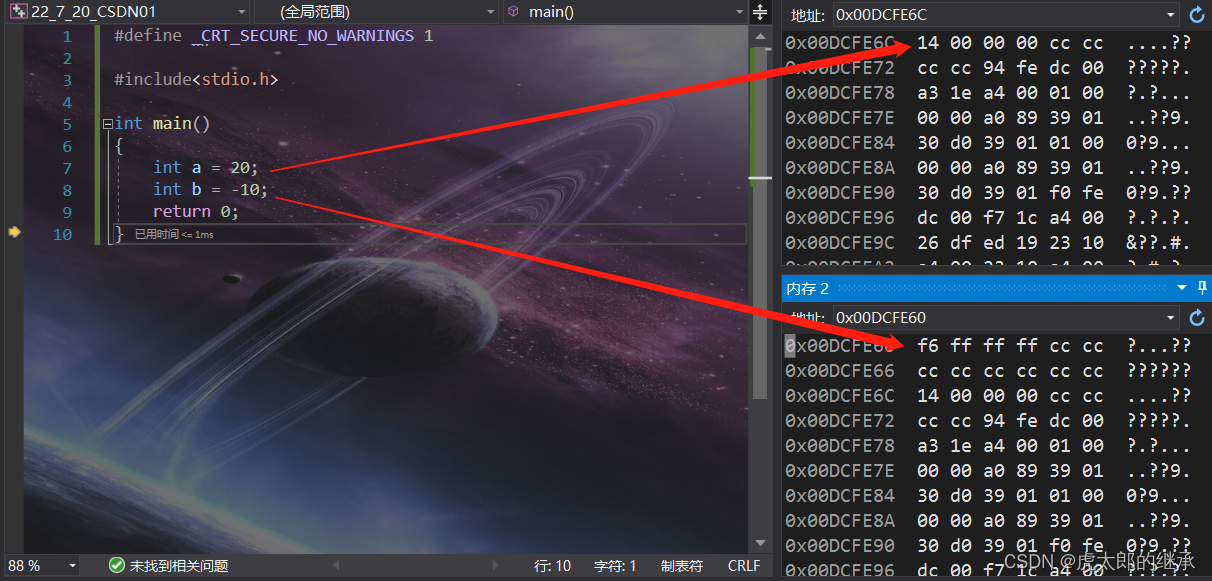
我们可以看到对于a存储的补码,但是发现顺序有点不对劲,这又是为什么呢?
三、大小端介绍
在这里,我们又将引入大小端存储模式的介绍:
大端存储模式:数据的低位保存在内存的高地址处,而数据的高位保存在内存的低地址处。
小端存储模式:数据的低位保存在内存的低地址处,而数据的高位保存在内存的高地址处。
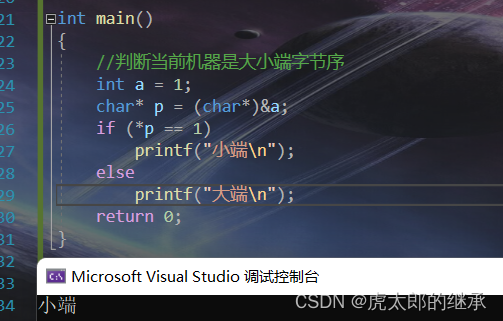
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int check_sys()
{
int a = 1;
char* p = (char*)&a;
/*if (*p == 1) { return 1; } else { return 0; }*/
return *p;
}
int main()
{
//判断当前机器是大小端字节序
/*int a = 1; char* p = (char*)&a; if (*p == 1) printf("小端\n"); else printf("大端\n"); return 0;*/
int ret = check_sys();
if (ret == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}
为什么会有大端和小端:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
四、练习
通过以上对整型在内存中的存储的理解,下面我们通过几个练习来给大家巩固一下:







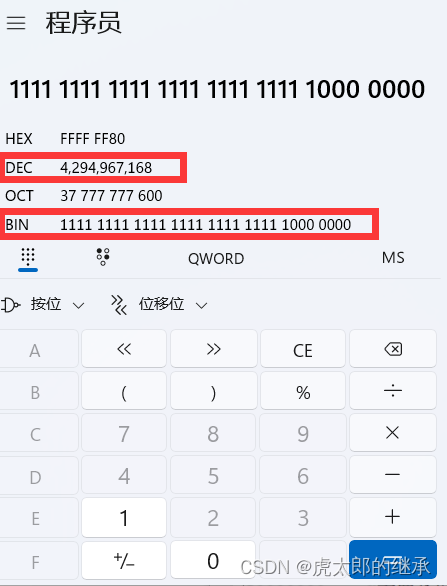

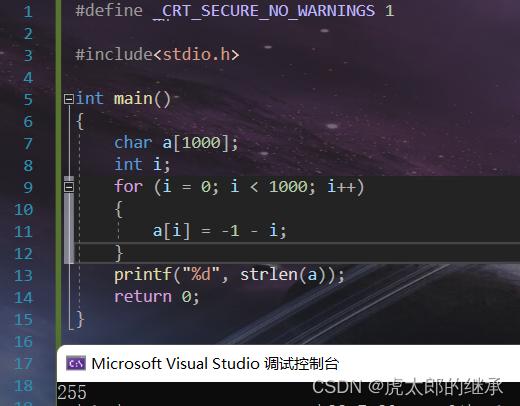


可分析,因为定义的i为无符号的char,所以i的取值范围为0~255;故在for循环的判断条件中,一直成立,所以该程序的输出结果是死循环。
同上题一样,因为定义的i是无符号整型,所以i永远大于等于0,故在for循环中,判断条件永远成立,该程序输出结果是死循环。
边栏推荐
- 软件测试面试小技巧 | 如果你没收到offer我倒立洗头
- 1306_ Comparison test of resource usage of two open source printf
- LeetCode 10. Regular Expression Matching
- 【微信小程序】解决代码上传超过大小限制,小程序分包
- [semidrive source code analysis] [module bringup] 37 - LCM driven bringup process
- Steve Aoki's Avatar will come to the sandbox metauniverse!
- 怎么学自动化测试
- 【集训DAY9】Light Tank【动态规划】
- Leetcode sword finger offer II 061 And the minimum K number pairs***
- easyexcel简单使用
猜你喜欢

OpenGL渲染管道

Allure测试报告怎么设置

【MSP430G2553】图形化开发笔记(2) 系统时钟和低功耗模式

The classification of artificial neural network includes: the classification of artificial neural network includes

Uniapp introduces Tencent map

【集训DAY10】Linear【数学】【思维】

百度工程师眼中的云原生可观测性追踪技术

A 股指数历史数据 API 数据接口

Using completable future to implement asynchronous callback

weirdo The interview topics include toilet habits, eating time and sleeping time
随机推荐
零基础转行软件测试学习要不要报培训班学习,还是自学好?
Appium元素定位——App自动化测试
【集训DAY8】Tent【数学】【DP】
SSM整合其他组件
Uniapp, wechat applet input regular verification can only be input as numbers and decimal places
可视化:这十个数据可视化工具软件平台你必须知道
uniapp,微信小程序input正则校验只能输入为数字和小数点位数限制
Ala-PNA丙氨酸改性PNA肽核酸|Ac-Ala-PNA的合成路线
Visualization: you must know these ten data visualization tool software platforms
Pycharm使用教程:5个非常有用的技巧
Mysql07 (data update DML)
word2vec简单总结
网络 IO 模型的演化过程
weirdo The interview topics include toilet habits, eating time and sleeping time
【sciter】:窗口通信
Mysql08 (transaction)
docker搭建redis及集群
List parsing < STL elementary > (runner's notes)
【MSP430G2553】图形化开发笔记(2) 系统时钟和低功耗模式
铜牛机房项目的优势和劣势