当前位置:网站首页>string的模拟实现
string的模拟实现
2022-07-22 04:16:00 【韩悬子】
string的模拟实现
1.简单实现string
我们先实现一个简单的string,只考虑资源管理深浅拷贝问题
暂且不考虑增删查改,增删查改版本在下面目录会有源代码
那么实现string先把基本的写了些,比如构造析构函数等等
因为库里面有个string所以这里有二种做法,一种是命名空间就是我下面那种,另一种把我们写的类把小写string改成大写String这样来区分来
代码
#pragma once
namespace str
{
// 先实现一个简单的string,只考虑资源管理深浅拷贝问题
// 暂且不考虑增删查改
class string
{
public:
string(const char* str)
:_str(new char[strlen(str) + 1])//这个加1是留给'\0'的
{
strcpy(_str, str);
}
~string()
{
if (_str)
{
delete[] _str;
}
}
private:
char* _str;
};
}
这上面有个小问题,就是在主函数记得包我们写的这个头文件,要不然strlen它会找不到,为什么包含了这个就会找到呢?
因为主函数里面保含了#include这些库,执行文件的时候会预处理,预处理里面有头文件展开,而前面的文件展开了,那么就有定义strlen了
没保含头文件的执行结果
图片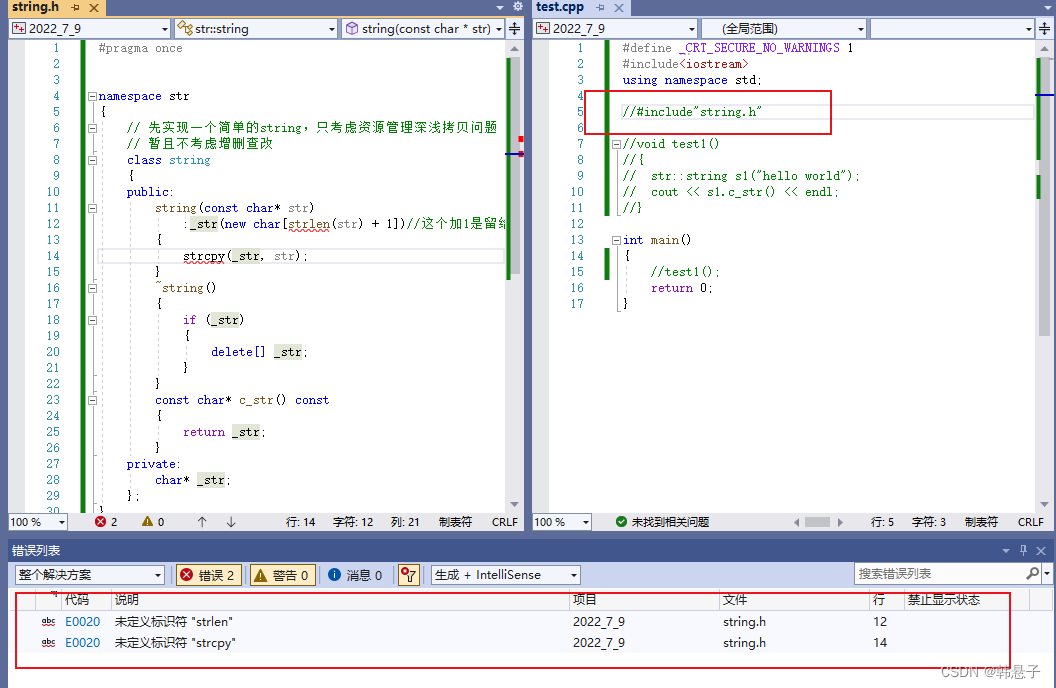
包含的
除了这个还有一个问题,如果没有加
#define _CRT_SECURE_NO_WARNINGS 这一串有的编译器是编译不过的,比如我的vs2022就会有下面图片的报错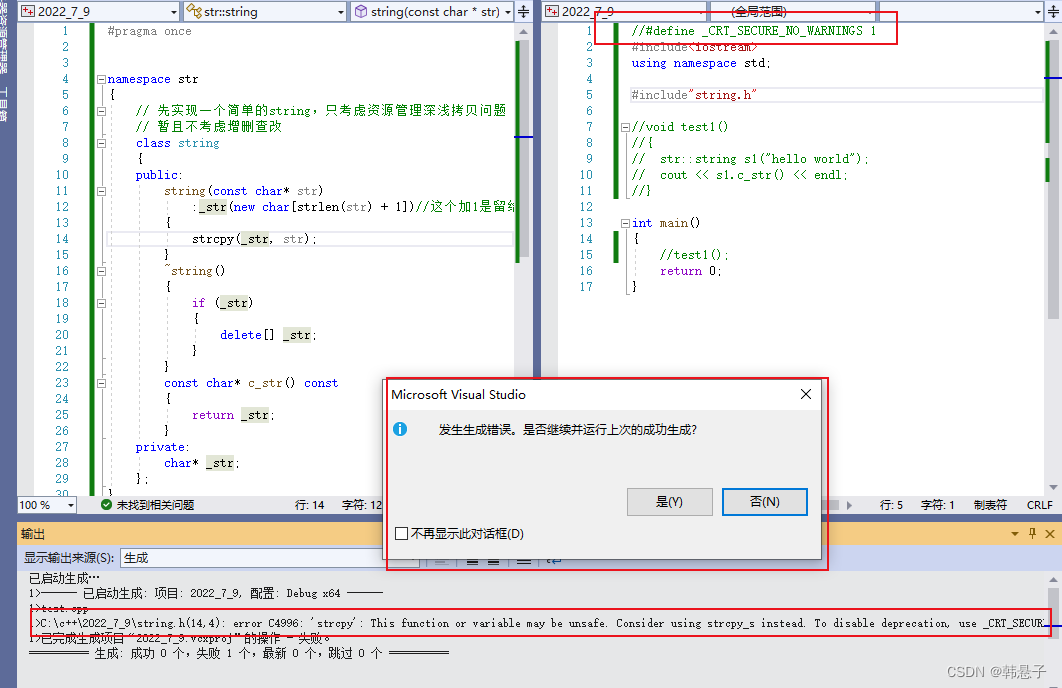
这个报错其实是认为这个函数不安全所以报错,
而#define _CRT_SECURE_NO_WARNINGS是屏蔽这个报错
写完了析构和构造,那么我们就要实现string的基本用法了,比如用string创建一个字符串再打印出来,我们发现直接打印是打印不出来的
代码
#pragma once
namespace str
{
// 先实现一个简单的string,只考虑资源管理深浅拷贝问题
// 暂且不考虑增删查改
class string
{
public:
string(const char* str)
:_str(new char[strlen(str) + 1])//这个加1是留给'\0'的
{
strcpy(_str, str);
}
~string()
{
if (_str)
{
delete[] _str;
}
}
const char* c_str() const
{
return _str;
}
private:
char* _str;
};
}
打印使用方式
void test1()
{
str::string s1("hello world");
cout << s1.c_str() << endl;
}
那我们现在再做其他功能,简单修改字符串和打印每个字符用空格分割
代码
char& operator[](size_t pos)
{
assert(pos < strlen(_str));
return _str[pos];
}
size_t size()
{
return strlen(_str);
}
void test1()
{
str::string s1("hello world");
cout << s1.c_str() << endl;
s1[0] = 'x';
cout << s1.c_str() << endl;
for (size_t i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
}
打印结果
接下来我们复制字符串
代码
void test2()
{
str::string s1("hello world");
str::string s2(s1);
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
}
运行结果
可以看到打印结果出来了,但是报错了这是怎么回事?
我们来调试一下
可以看到s1和s2指向的是同一个位置,而这里有问题的是析构了二次,还有就是其中一个改变其他也会改变,而会造成这样的有个专属的名字叫浅拷贝
那么这时候我们就要用深拷贝了
深拷贝的意思是有一样大的空间一样的值,但是用的不是同一个空间
代码
//s2(s1) s1是s s2是this 指针
string(const string& s)
:_str(new char[strlen(s._str) + 1])//这个加1是留给'\0'的
{
strcpy(_str, s._str);
}
这样就不会浅拷贝的问题了
接下来来实现赋值
这里实现赋值一样有和之前一样的问题析构二次,还有就是内存问题就是内存太大或者不够越界,还有可能自己和自己赋值,自己和自己赋值就直接返回自己就好了
写法
先释放要被赋值的空间,拷贝赋值的空间大小给被赋值的空间,再把内容拷贝过去
代码
//s1=s3
string& operator=(const string& s)
{
if (this != &s)
{
delete[] _str;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
return *this;
}
不过这种代码有个问题就是,如果拷贝失败了怎么办?
因为它是先释放了再拷贝的
更好的版本
//s1=s3
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[strlen(s._str) + 1];
strcpy(tmp,s._str);
delete[] _str;
_str = tmp;
}
return *this;
}
使用场景代码
void test3()
{
str::string s1("hello wprld");
str::string s2(s1);
str::string s3("111111");
s1 = s3;
cout << s1.c_str() << endl;
}
2.考虑增删查改的string模拟实现
因为这里是要考虑增删查改的了,而插入肯定不能一个一个插入,所以
成员要加上size,capacity之类的
因为有些部分比较简单所以就直接放上代码(代码会有注释的)如果不知道里面的函数有什么用可以去翻翻我上期写的string讲解也可以在评论区问我,或者不知道函数怎么实现的可以在评论区问我
string模拟实现代码
#pragma once
#include<assert.h>
namespace str
{
// 先实现一个简单的string,只考虑资源管理深浅拷贝问题
// 暂且不考虑增删查改
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
iterator begin() const
{
return _str;
}
iterator end() const
{
return _str + _size;
}
iterator begin()
{
return _str;
}
iterator end()
{
return _str+_size;
}
string(const char* str="")//""这个就是默认'\0'
:_size(strlen(str))
,_capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
//s2(s1) s1是s s2是this 指针
string(const string& s)
:_size(s._size)
,_capacity(_size)
{
_str = (new char[_capacity + 1]);//这个加1是留给'\0'的
strcpy(_str, s._str);
}
//s1=s3
string& operator=(const string& s)
{
if (this != &s)//避免自己赋值自己的情况
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
~string()
{
if (_str)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}
const char* c_str() const
{
return _str;
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
//这里分三种情况,第一种是缩容,n<_size的情况,那么就把n的位置当作'\0',第二种 n>_size,但是n<capacity,这种情况不用增容
//第三种 n>capacity 这种情况就要考虑增容
void resize(size_t n, const char ch = '\0')
{
if (n < _size)
{
_size = n;
_str[_size] = ch;
}
else
{
if (n > _capacity)
{
reserve(n);
}
for (size_t i = _size; i < n; i++)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
char& operator[](size_t pos) const
{
assert(pos < strlen(_str));
return _str[pos];
}
size_t size() const
{
return strlen(_str);
}
void push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);//这个考虑capacity开始可能是0的情况
}
_str[_size]=ch;
++_size;
_str[_size] = '\0';
}
void append(const char* str)
{
size_t len = _size + strlen(str);
if (len > _capacity)
{
reserve(len);
}
strcpy(_str + _size, str);
_size = len;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
bool operator<(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2; } bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}
}
测试string模拟代码
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
#include"string.h"
//void test1()
//{
// str::string s1("hello world");
// cout << s1.c_str() << endl;
// s1[0] = 'x';
// cout << s1.c_str() << endl;
// for (size_t i = 0; i < s1.size(); i++)
// {
// cout << s1[i] << " ";
// }
//}
//void test2()
//{
// str::string s1("hello world");
// str::string s2(s1);
// cout << s1.c_str() << endl;
// cout << s2.c_str() << endl;
//}
//
//void test3()
//{
// str::string s1("hello world");
// str::string s2(s1);
// str::string s3("111111");
// s1 = s3;
// cout << s1.c_str() << endl;
//
//}
//void test4()
//{
// str::string s1("hello world");
// cout << s1.c_str() << endl;
//
// str::string s2;
// cout << s2.c_str() << endl;
// str::string s3(s1);
//
//}
void test5()
{
str::string s1("hello world");
s1.push_back('1');
s1.push_back('1');
cout << s1.c_str() << endl;
s1 += '2';
s1 += '3';
s1 += '4';
cout << s1.c_str() << endl;
//s1 += "bitejiuyeke";
cout << s1.c_str() << endl;
str::string s2;
//s2.reserve(20);
s2 += '1';
s2 += '1';
s2 += '1';
s2 += '1';
s2 += '1';
s2 += '1';
s2 += '1';
s2 += '1';
s2 += '1';
s2 += '1';
str::string s3("hello world");
s3.reserve(15);
//s3.resize(21, 'x');
s3.resize(14, 'x');
//s3.resize(5);
//s1 < s2;
}
void test6()
{
str::string s1("hello world");
str::string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
*it++;
}
}
int main()
{
test6();
return 0;
}
接下来就来实现函数insert,在任意位置插入
代码
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size;
while (end >= pos)
{
_str[end + 1] = _str[end];
--end;
}
_str[pos] = ch;
_size++;
return *this;
}
运行结果
这样子就看起来好像没问题了,但是上面代码其实是有问题的,我们来试试头插
运行结果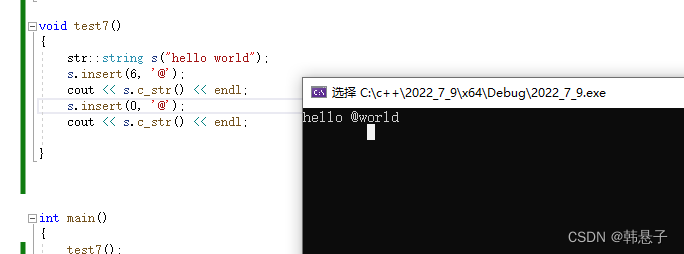
可以看到死循环了,为什么?
其实很简单因为end是无符号整型,当end=-1的时候他就变成了一个超大的数
要是把end改成int能行吗?
答案也是不行的因为pos也是无符号整型,当整型和无符号整型相加,那么就会出现整型提升,按照无符号整型来算
不过要是二个都强转成int就没问题了
不过这种也挺怪的,明明是二个size_t的类型便要强转成int
所以就要用这种
代码
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size+1;
while (end > pos)
{
_str[end] = _str[end-1];
--end;
}
_str[pos] = ch;
_size++;
return *this;
}
前面是把自己往后面移动,现在是把前面移动到后面,这样子就不会出现-1了
搞了这个只能插入一个字符的insert,那么就要搞能插入一个字符串的insert
代码
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end>pos-len-1)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
string里面有个npos

这是最正规的定义和声明,但是他还可以这样
声明和定义一起居然没有报错,明明它是静态成员变量
接下来就要写earse,在任意位置删除
这里分为二种情况
看下图
代码
string& earse(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)//len=npos代表着没给npos值默认是size_t的-1
{
_str[pos] = '\0';
_size = pos;
}
else
{
size_t begin = pos + len;
while (begin <= _size)
{
_str[begin - len] = _str[begin];
++begin;
}
_size -= len;
}
return *this;
}
find,找到某个函数或字符串代码
size_t find(char ch, size_t pos = 0)
{
for (; pos < _size; ++pos)
{
if (_str[pos] == ch)
{
return pos;
}
}
return npos;
}
size_t find(const char* str, size_t pos = 0)
{
const char* p = strstr(_str + pos, str);
if (p == nullptr)
{
return npos;
}
else
{
return p-_str;
}
}
写完了这个还有最后一步了,那就是流插入和流输出
第一种
ostream& operator<<(ostream& out, const string& s)
{
cout << s.c_str();
return out;
}
第二种
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}
上面的到底有什么问题?第一种对还是第二种对,还是二种都没问题
我们来看看他们分别加入’\0’会怎么样
这是第二种的
这里打印了x,但是有的vs可能是先打印三个空格,在打印x的
我们再看看不是用范围for的
可以看到X没有打印出来,说明没有打印’\0‘,所以用范围for的是正确的
接下来就是流提出
istream& operator>>(istream& in, string& s)
{
char ch;
ch = in.get();
char buff[128] = {
'\0' };
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
s += buff;
return in;
}
string模拟的全代码
#pragma once
#include<assert.h>
namespace str
{
// 先实现一个简单的string,只考虑资源管理深浅拷贝问题
// 暂且不考虑增删查改
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
iterator begin()
{
return _str;
}
iterator end()
{
return _str+_size;
}
string(const char* str="")//""这个就是默认'\0'
:_size(strlen(str))
,_capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
//s2(s1) s1是s s2是this 指针
string(const string& s)
:_size(s._size)
,_capacity(_size)
{
_str = (new char[_capacity + 1]);//这个加1是留给'\0'的
strcpy(_str, s._str);
}
//s1=s3
string& operator=(const string& s)
{
if (this != &s)//避免自己赋值自己的情况
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
~string()
{
if (_str)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}
const char* c_str() const
{
return _str;
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
//这里分三种情况,第一种是缩容,n<_size的情况,那么就把n的位置当作'\0',第二种 n>_size,但是n<capacity,这种情况不用增容
//第三种 n>capacity 这种情况就要考虑增容
void resize(size_t n, const char ch = '\0')
{
if (n < _size)
{
_size = n;
_str[_size] = ch;
}
else
{
if (n > _capacity)
{
reserve(n);
}
for (size_t i = _size; i < n; i++)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
char& operator[](size_t pos) const
{
assert(pos < strlen(_str));
return _str[pos];
}
size_t capacity() const
{
return _capacity;
}
size_t size() const
{
return strlen(_str);
}
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//size_t end = _size;
/* while ((int)end >= (int)pos) { _str[end + 1] = _str[end]; --end; }*/
size_t end = _size+1;
while (end > pos)
{
_str[end] = _str[end-1];
--end;
}
_str[pos] = ch;
_size++;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end>pos-len-1)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
string& earse(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)//len=npos代表着没给npos值默认是size_t的-1
{
_str[pos] = '\0';
_size = pos;
}
else
{
size_t begin = pos + len;
while (begin <= _size)
{
_str[begin - len] = _str[begin];
++begin;
}
_size -= len;
}
return *this;
}
void push_back(char ch)
{
//if (_size == _capacity)
//{
// reserve(_capacity == 0 ? 4 : _capacity * 2);//这个考虑capacity开始可能是0的情况
//}
//_str[_size]=ch;
//++_size;
//_str[_size] = '\0';
insert(_size, ch);
}
void append(const char* str)
{
//size_t len = _size + strlen(str);
//if (len > _capacity)
//{
// reserve(len);
//}
//strcpy(_str + _size, str);
//_size = len;
insert(_size, str);
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
size_t find(char ch, size_t pos = 0)
{
for (; pos < _size; ++pos)
{
if (_str[pos] == ch)
{
return pos;
}
}
return npos;
}
size_t find(const char* str, size_t pos = 0)
{
const char* p = strstr(_str + pos, str);
if (p == nullptr)
{
return npos;
}
else
{
return p-_str;
}
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
private:
char* _str;
size_t _size;
size_t _capacity;
const static size_t npos;
};
const size_t string::npos = -1;
ostream& operator<<(ostream& out, const string& s)
{
//cout << s.c_str();
for (auto ch : s)
{
out << ch; } return out; } istream& operator>>(istream& in, string& s)
{
s.claer();
char ch;
ch = in.get();
char buff[128] = {
'\0' };
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
s += buff;
return in;
}
bool operator<(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2; } bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}
}
3.string的现代写法
拷贝构造的现代写法
s2(s1)
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
// 现代写法:剥削,要完成深拷贝,自己不想干活,安排别人是干活,然后窃取劳动成果
// s2(s1)
string(const string& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp);
}
原理很简单,让tmp创建空间,然后拿了tmp的成果
赋值
string& operator=(const string& s)
{
if (this != &s)
{
string tmp(s._str);
swap(tmp);
}
return *this;
}
这个赋值比起上面的构造函数还多了一步,就是tmp是局部变量,局部变量出了作用域会调用析构函数,相比于构造函数赋值是:我干活,你拿我劳动成果,我还要帮你收拾烂摊子,比如s._str是hello world,那么tmp就要释放hello world这个空间。资本家见了都落泪了啊
不过这种写法不是最简介的
string& operator=( string s)
{
swap(s);
return *this;
}
这种去了&这样子就说明了s是临时拷贝,那么他就要调用构造函数。原理和上面那种写法一样
边栏推荐
- Kalman filter program of POTU PLC signal processing series
- C#上传文件到共享文件夹
- Typora free download compressed package (latest available)
- 这个好用的办公网优化工具,官宣免费了
- Mock simulates data and initiates get and post requests (nanny level tutorials are sure to succeed)
- "Demand optimization" uses PostMessage to solve the cross domain problem of localstorage
- Transparent transmission of punctual atom Lora wireless serial port point-to-point communication and Its Precautions
- Beautify multiple digits
- 【Leetcode栈与队列--最小栈】155.最小栈
- Vulkan-官方示例解读-子通道
猜你喜欢

JVM memory model: PC program counters

JVM memory model: classification and acquisition of class loaders

JVM: parental delegation mechanism for class loading

Alternet scripting, user interface design function

【STK初探】创建一条奔月轨道

6-12漏洞利用-枚举smtp用户名

About the recent online treatment of myopia with low concentration atropine
Android面试:2022请收好这份网易Android开发和抖音电商Android工程师的面经
6-12 exploit - enumerate SMTP user names
Chant Developer Workbench 2022
随机推荐
[unity project practice] game architecture
[ssm]ssm integration ① (integration configuration)
美化多位数字
记一个composer依赖问题requires composer-runtime-api ^2.0.0 -> no matching package found
科普 | 如何创建一个DAO?
mysql中not like的简化写法
EasyCVR平台如何实现无需鉴权即可接入特殊设备?
【解决】npm ERR! code E401
Automated Test Engineer Interview resume reference
Alternet scripting, user interface design function
JVM内存模型:运行时数据区及线程
字符编码问题
SOC key control LED
How far can TTL, RS232 and 485 transmit?
C# 上传图片至共享文件夹
JVM内存模型:类加载过程
mysql通过开启全局日志进行定位排查慢sql
计算机网络传输层面试题
【解决方案】解决paddlepaddle运行强化学习代码时TypeError: fc() got an unexpected keyword argument ‘is_test‘的错误
RquestMapping的注解功能、注解使用范围、注解的属性详情