当前位置:网站首页>数据分析demo
数据分析demo
2022-07-20 22:54:00 【ZJH'blog】
摘要
降水情况的预测对城市管理、居民生活都有巨大影响。本文利用逻辑回归、支持向量机、决策树分类、随机森林四种方法对洛杉矶的天气进行预测,并对这几种方法的预测准确度进行比较。
关键词 回归预测;逻辑回归;支持向量机;决策树分类;随机森林
Abstract:
The forecast of precipitation had a huge impact on urban management, residents live. This paper, by us-ing logistic regression, support vector machines, decision tree classification, gaussian naive bayes, gradient in-creasing tree, random forests, XGBoost, CatBoost several methods to predict the weather of the Los Angeles, and prediction accuracy of these methods were compared.
Key words: Regression prediction; Logistic regression; SVM; decision tree classification; Random forests
目前降水季节趋势预报主要分为统计学、动力学和动力统计相结合三类方法。统计方法充分利用历史资料规律,选取有明确物理意义和显著相关的因子进行建模。但由于各预测因子相互作用过程复杂,不同时间尺度的预测信号不一致,加大了预测的难度。随着数值模式的发展,动力模式成为气候预测的主要工具,许多国家建立了数值预报模式。近年来,我国季节预测模式对大气环流、ENSO(El Niňo-Southern Oscillation)现象、亚洲夏季风等的预测能力已有明显提升,但对降水预测技巧依然有限,特别是对东亚地区夏季降水的预报技巧相对较低。
机器学习强调从历史数据中学习规则,对新数据进行推理和预测。区别于传统统计方法,机器学习擅长处理非线性问题,利用机器学习的优势可以从地球系统中发现并提取新的相互关联信号(贺圣平等,2021)。近年来,机器学习在气象领域的应用越来越广泛,常用的机器学习算法有支持向量机、贝叶斯算法、神经网络、决策树算法等。随着计算能力的提高和深度学习理论的发展,以卷积神经网络(Convolutional Neural Networks, CNN)和长短期时间记忆网络(Long Short-Term Memory, LSTM)为代表的深度学习方法在气候领域得到应用。
洛杉矶降水时空分布不均,影响因子复杂,当前对其机理和预测的研究还存在短板,动力模式预测水平与业务服务需求存在差距,有必要利用机器学习的优势进一步提高当地预测水平。本文采用逻辑回归、支持向量机、决策树分类、高斯朴素贝叶斯、梯度提升树、随机森林、XGBoost、CatBoost,建立适用于洛杉矶的降水统计预测方法。
1 资料和方法
1.1 数据介绍
数据来源kaggle的[Precipitation Prediction in LA] 。
本次处理的天气数据有如下特征:
PRCP = 降水量(十分之一毫米)
TMAX = 最高温度(十分之一摄氏度)
TMIN = 最低温度(十分之一摄氏度)
PGTM = 阵风高峰时间(小时和分钟,即 HHMM)
AWND = 每日平均风速(每秒十分之一米)
TAVG = 平均温度(十摄氏度)
WDFx = 最快 x 分风向(度)
WSFx = 最快 x 分钟风速(每秒十分之一米)
WT = 天气类型
1.2 数据预处理
使用pandas框架导入数据并对其进行进一步分析。
使用seaborn库将数据分析的结果进行可视化。
首先处理PRCR列(目标列),降雨量为0的不下雨情况标记为标签0,降雨量不为0的下雨情况标记为标签1,处理后发现不下雨的天数过多,柱状图可视化天数后如图1-1

清楚地看到,降水发生时的样本数量远小于降水不发生的情况。因此,存在阶级失衡,于是采用smote方法对数据过采样,增多下雨天数来平衡不下雨和下雨的计数。
通过热力图检查缺失值发现,缺失值很多,如图1-2:
根据热力图看出,白色的部分是缺失值,由此可知,PGTM和TAVG属性空值过多,应当删除,其余属性的空值使用缺失值处理。
在数据中,站点名和地区名相同,因此对实验的预测没有影响,可以删除此两列,此外,此次分析的气象数据不具有季节性,所以是否下雨与日期值无关,所以删除此列。
将缺失值标记为NA,再使用众数进行填补,最后删除重复值,对处理后的数据使用热力图进行检查:
2 特征选择和数据规范化
基本方法是使用卡方检验进行特征选择和使用 MinMaxScaler 对数据进行规范化。
2.1 特征选择
卡方检验介绍:
基本思想:根据样本数据推断总体分布与期望分布是否有显著性差异,或者推断两个分类变量是否相关或者独立。
一般可以设原假设为:察频数与期望频数没有差异,或者两个变量相互独立不相关。
实际应用中,我们先假设原假设成立,计算出卡方值,卡方表示观察值与理论值间的偏离程度。
通过卡方检验进行特征选择,其中p-value值依据不同特征进行可视化:
由于WT02具有高p_value值(显著>0.05),因此表示此变量与PRCP无关,可以不用考虑用于模型训练,并删除特征’WT02’。
2.2 归一化
归一化是指将数据集中的要素设置比例。此实验中随机划分x和y的训练集和测试集,对训练集里面样本数量较少的类别(PRCP=1)进行过采样,合成新的样本来缓解类不平衡。并且将数据映射到[0~1]的区间。
3 不同模型的实现
3.1 逻辑回归
3.1.1 原理
对率回归属于监督学习。在对率回归分类器中,先输入样本和对应的标签,对率回归就是根据样本的特征值,把样本映射为 区间中的一个值(以下称这个值为回归值),在根据回归值的大小进行分类。本次二分类任务是把回归值在 区间中的样本归为标签为0的类,回归值在 中的样本归为标签为1的类。
下面给出具体的数学原理解释:
假设一组样本具有n维的属性,且属性值 与回归值之间满足线性关系:

这就是常见的Logistic模型表达式,X是自变量,p是因变量的函数图像如下:

可见,在二分类任务中,当对每一个输入特征 都给定一个权值 ,对特征值进行加权,再通过logistic模型(1-1)得到
样本属于1类别的概率:
3.1.2 实验结果
偏置值为51.8,惩罚值为12,ROC_AUC得分为0.97,两类错误矩阵及其可视化如下:

3.2 支持向量机
3.2.1 原理
支持向量机 (SVM)是一组用于分类、 回归和异常值检测的监督学习方法。
支持向量机的优点是:
- 在高维空间中有效。
- 在维度数大于样本数的情况下仍然有效。
- 在决策函数中使用训练点的子集(称为支持向量),因此它也具有内存效率。
- 通用性:可以为决策函数指定不同的内核函数提供了通用内核,但也可以指定自定义内核。
支持向量机的缺点包括:
- 如果特征数量远大于样本数量,在选择核函数时避免过度拟合,正则化项至关重要。
- SVM 不直接提供概率估计,这些是使用昂贵的五折交叉验证计算的(参见下面的分数和概率)。
SVM学习的基本想法是求解能够正确划分训练数据集(下图中实心黑点与空心点)并且几何间隔最大的分离超平面。如下图所示, w·x+b=0即为分离超平面作为决策边界,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。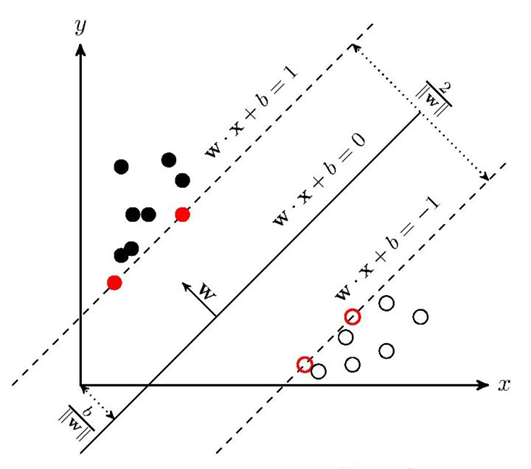
在几何中,超平面是一个空间的子空间,它是维度比所在空间小一维的空间。 如果数据空间本身是三维的,则其超平面是二维平面,而如果数据空间本身是二维的,则其超平面是一维的直线。在二分类问题中,如果一个超平面能够将数据划分为两个集合,其中每个集合中包含单独的一个类别,我们就说这个超平面是数据的“决策边界“。
SVM目标是"找出边际最大的决策边界",听起来是一个十分熟悉的表达,这是一个最优化问题,而最优化问题往往和损失函数联系在一起。和逻辑回归中的过程一样,SVM也是通过最小化损失函数来求解一个用于后续模型使用的重要信息:决策边界。
这里梳理一下这整个过程:
3.2.2 实验结果
支持向量机最优参数:惩罚系数C=100,选择kernel=rbf,gamma=1
ROC_AUC得分为0.95
两类错误矩阵及其可视化如下: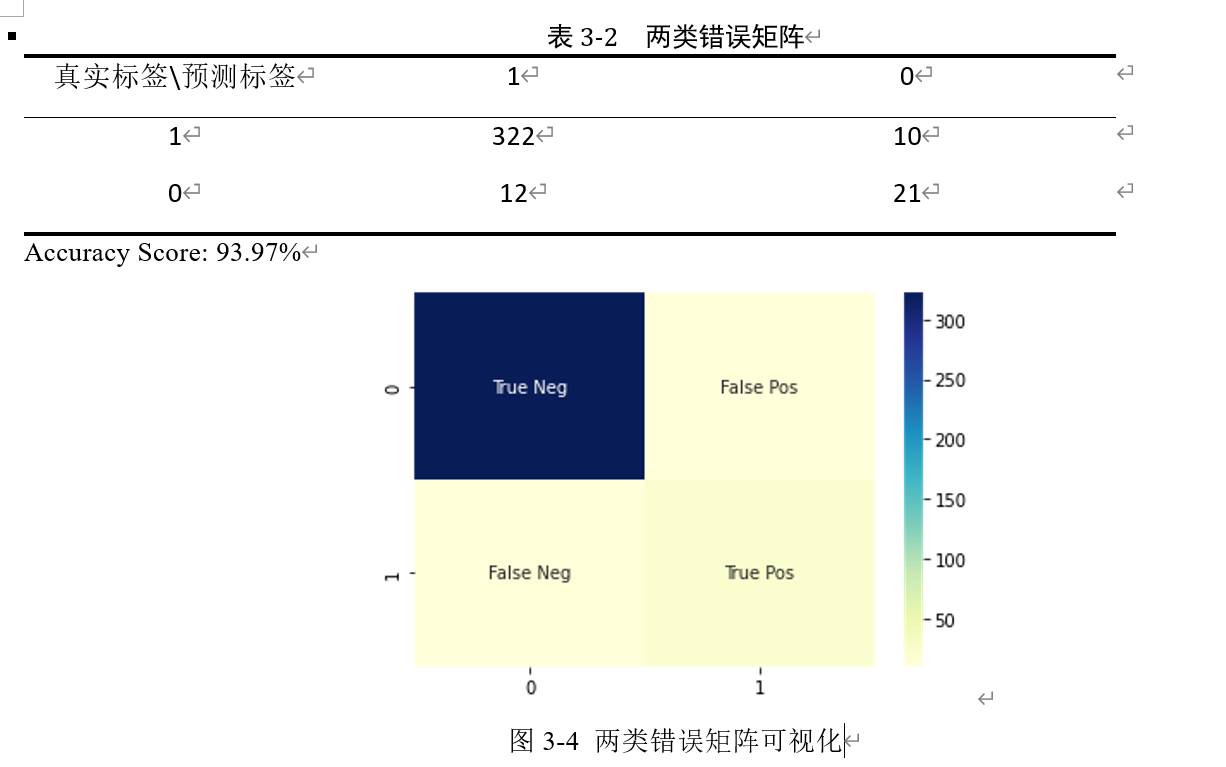

3.3 决策树分类
3.3.1 原理
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构建决策树来 进行分析的一种方式,是一种直观应用概率分析的一种图解法;决策树是一种预 测模型,代表的是对象属性与对象值之间的映射关系;决策树是一种树形结构, 其中每个内部节点表示一个属性的测试,每个分支表示一个测试输出,每个叶节 点代表一种类别;决策树是一种非常常用的有监督的分类算法。
决策树的决策过程就是从根节点开始,测试待分类项中对应的特征属性,并按照 其值选择输出分支,直到叶子节点,将叶子节点的存放的类别作为决策结果。
决策树分为两大类:分类树和回归树,前者用于分类标签值,后者用于预测连续值,常用算法有ID3、C4.5、CART等
构建步骤如下:
- 将所有的特征看成一个一个的节点;
- 遍历每个特征的每一种分割方式,找到最好的分割点;将数据划分为不同的子节点,eg: N1、N2…; 计算之后所有子节点的’纯度’信息;
- 对第二步产生的分割,选择出最优的特征以及最优的划分方式;得出最终的子节点: N1、N2…Nm
- 对子节点N1、N2…Nm分别继续执行2-3步,直到每个最终的子节点都足够’纯’。
决策树特征属性类型
- 属性是离散值,而且不要求生成的是二叉决策树,此时一个属性就是一个分支
- 属性是离散值,而且要求生成的是二叉决策树,此时使用属性划分的子集进行测试,按照 “属于此子集”和“不属于此子集”分成两个分支
- 属性是连续值,可以确定一个值作为分裂点split_point,按照>split_point和 <=split_point生成两个分支
3.3.2 实验结果
两类错误矩阵及其可视化如下:ROC_AUC=0.81

3.4 随机森林
3.4.1 原理
随机森林算法是由Breiman于2001年提出的一种基于Bagging重复采样技术,将多棵决策树进行组合的方法。该方法由随机向量θ构成一个组合模型:{h(X,θi),i=1,…,k},θ服从独立同分布,X为自变量,k为决策树的数量。一般按照8:2的比例将原始数据集分为训练集和测试集,在训练集中建立随机森林模型,对特征变量重要性进行分析,在测试集中对模型评估效果进行检验。
随机森林模型对于数据的容忍度较强,并且可以很好地处理存在异常值和缺失值的数据。在对特征变量进行重要性程度分析时,区别于线性回归模型,随机森林算法具有分类速度快、抗噪音能力强、不会出现过度拟合、不需对函数形式进行事先假定等优点。模型会选择一个噪声随机加入特征变量中,并观察结果是否会出现差异,通过比较方差大小来判断是否存在差异,并确定该变量的重要性程度。
随机森林包含分类和回归两种技术,本文研究的保值率影响因素问题属于回归预测问题。回归的基本思路是:
(1)在n个原始样本数据基础上,应用bootstrap有放回地随机抽取K个自助样本集,并以此构建K棵回归树,每次抽样时未被抽到的样本又组成K个袋外数据,组成随机森林的测试样本;
(2)假设原始数据变量个数为N,在每棵回归树的每个节点处随机抽取mtry个变量作为备选分支变量,然后根据最优分支原则选取最优分支数。同时由于树可以最大化地生长,因此无需采取剪枝操作;
3.4.2 实验结果
准确率为95.62%,两类错误矩阵及其可视化如下: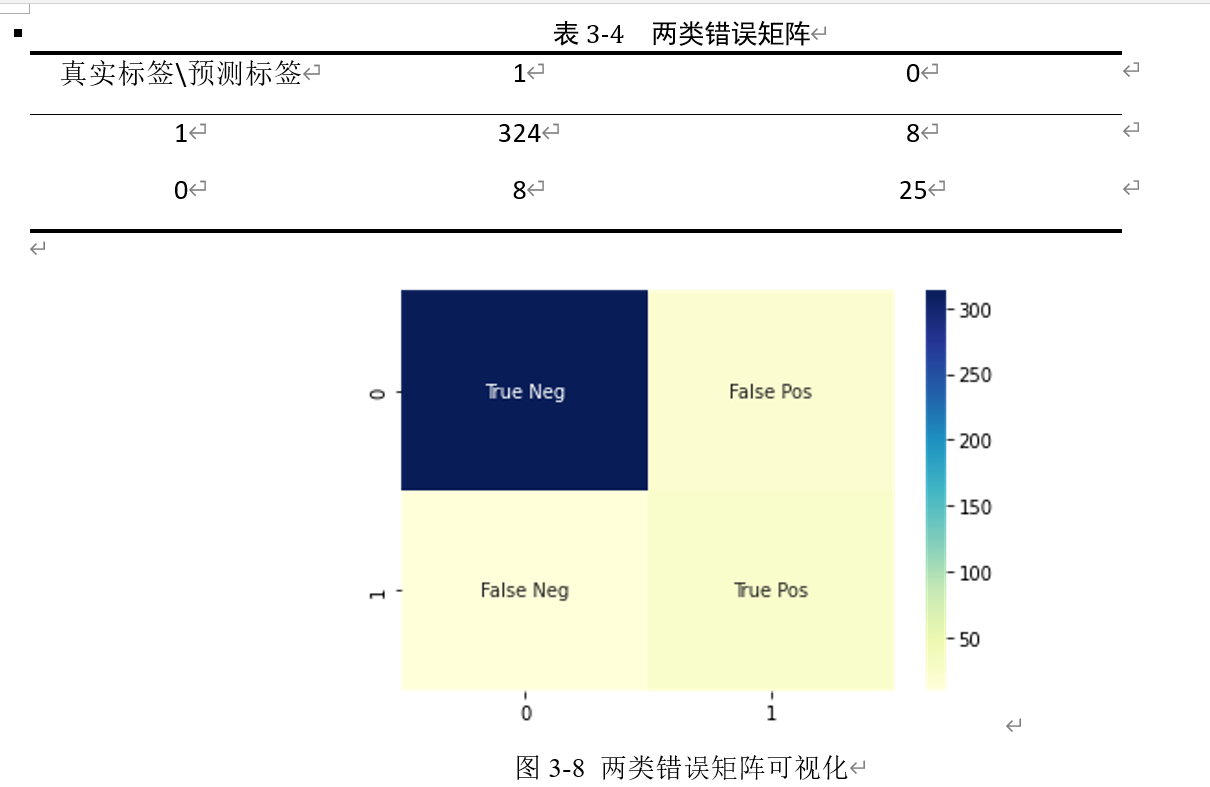
AUC值为0.95427,结果可视化如下:

4 模型比较
模型的MLA Train Accuracy、MLA Test Accuracy、MLA Precission、MLA Recall、MLA AUC比较如下表:
5 结论
天气数据最常见的问题是数据的缺失和异常,所以在数据的处理上要采用合适的方法。从预测结果来看,LR测试集极低的准确度可以看出天气特征随是否降雨呈非线性关系。并且从社会意义上来看,降雨预测的高准确率可以对城市的管理及居民的生活产生极大的效益。传统的天气预报方法已经发展的很完善,在短时间内很难有质的飞跃,数值预报技术是气象预报工作中重要的预报方式,但该技术的运行速度和预报准确率都有待提高,且还存在着一些弱点和问题需要解决。近年来,机器学习方法在很多领域中得到广泛使用,且在诸多方面取得了突破性的进展,但是有些理论和方法不够完善,需要进一步探索出更有实效性的机器学习方法来提高天气预报能力。这些机器学习方法也被应用于临近预报中。
由于不同的机器学习方法的构建方式不同,运算机理也不同,临近预报结果的好坏很大程度上依赖于机器学习方法本身及初始参数的设定,这些都增加使用不同机器学习方法临近预报时的不确定性。目前本文的研究仅针对是否降雨使用不同的机器学习方法进行临近降雨预报及不同预报方法之间的预报效果比较,还有更多的问题需要研究和探索。
机器学习方法还处于不断发展的阶段,许多方法还未被挖掘使用,有些方法的理论也还不够完善。机器学习方法训练模型时各内部各参数的最优配置也因训练数据集的不同而发生变化,另外训练数据集的分布情况及数量等也影响机器学习方法临近预报的效果。如何提高临近预报的准确率、预报的质量,探究有效的适应复杂气象数据特点的预报方法都是今后还需要深入研究的问题。
参考文献(References)
[1]陈明轩,俞小鼎,等.对流天气临近预报技术的发展与研究进展[J.应用气象学报,200415(6):754-766
[2]Eilts M D,Johnson J T,et al.Severe warning decision support system[J].18th Conf on severe local storms,Amer Meteor Soc,San Fransisco,CA,1996:536-540AA.
[3]Dixon M.TITAN:Thunderstorm identification,tracking,analysis,and nowcasting aradar-based methodolo-gy[J].Atoms Oceanic Technol,1993,8:467-476.
[4]Golding B W.Nimrod:A system for generating automated very short range forecasts [J]Meteor Appl,1998,5:1-16.
[5]Wilson J W,Ebert EE,Saxen T R,et al.Sydney 2000 forecast demonstration project:convective storm nowcast-ing[J].Weather and Forecasting,2004,19:131-150.
[6]Pierce C E,Collier C G,et al.GANDOLF:a system for generating automated now casts of convective precipita-tion[J].Meteor Appl,2000,7:341-360.
[7]陈云浩,史培军,李晓兵.不同热力背景对城市降雨(暴雨)的影响()一基于人工神经网络的集成预报模型[J.自然灾害学报,2001,10(3):26-31
[8]熊聪聪,王静,宋鹏,等.遗传算法在多模式集成天气预报中的应用[.天津科技大学学报,2008,23(4):80-84.
[9]吴清佳,张庆平,万健.遗传神经网络的智能天气预报系统[J.计算机工程,2005,31(14):176-177
[10]吴建生,金龙,汪灵枝.遗传算法进化设计BP神经网络气象预报建模研究[).热带气象学报,2006,22(4):411-416.
[11]陈永义,俞小鼎,等.处理非线性分类和回归问题的一种新方法(1)一支持向量机方法简[J.应用气象学报,2004,15(3):345-354
[12]冯汉中,陈永义.处理非线性分类和回归问题的一种新方法一支持向量机方法在天气预报中的应用[J).应用气象学报,2004,15(3):335-365.
[13]李智才,马文瑞.支持向量机在短期气候预测中的应用[J.气象,2016,32(5):58-60.
[14]熊秋芬,曾晓青.SVM方法在降水预报中的应用及改进[J.气象,2008,34(12):90-95.
[15]贺佳佳,陈劲松等.一种多时间尺度SVM局部短时临近降雨预测方法).气象,2017,43(4):402-412.
边栏推荐
猜你喜欢

Let me tell you how a grass-roots programmer can counter attack and successfully enter bat!

Shell 脚本特殊变量列表
![[Interview: concurrence19: Multithreading: Park & unpark]](/img/c5/0ba6a1645ddb3ace70f64c10cf9f98.png)
[Interview: concurrence19: Multithreading: Park & unpark]

Kubernetes deploy mysql5.7 (single node)
【面試:並發篇19:多線程:Park&Unpark】

进程的创建(创建原语,引起其发生的事件)

对等网主机的通信过程以及原理,很简单

Detailed explanation of JUC concurrent programming wait notify
![[solved] Splunk :Non-200/201 status_ code=401; {“messages“:[{“type“:“WARN“,“text“:“call not properly](/img/54/ac3d4f05001cb4ad7df12c9f4a2122.png)
[solved] Splunk :Non-200/201 status_ code=401; {“messages“:[{“type“:“WARN“,“text“:“call not properly

Okaleido tiger NFT即将登录Binance NFT平台,你期待吗?
随机推荐
How kubelet works
tars源码分析之22
主成分分析及SPSS的使用------笔记
【面試:並發篇19:多線程:Park&Unpark】
OpenCV学习——ArUco模块
1190. Invert the substring between each pair of parentheses
Is there a completely independent localization database technology
Kube controller manager principle
Summary of internal keywords in C #
进程的组织方式:链接方式和索引方式
What is a video content recommendation engine?
[pictures and texts] this article explains the JVM architecture, class file structure and bytecode structure!!
How Kube proxy works
The top three suddenly changed, revealing the latest ranking of programming languages in July
Listen for attribute value changes in swift (observer mode)
【MySQL】在CentOS 7 简单安装
redis集群安装
Splunk HEC 開啟8088 port
Ce PIP utilise une petite copie, doit avoir tout!
tars源码分析之27