当前位置:网站首页>Data Lake: evolution of data Lake Technology Architecture
Data Lake: evolution of data Lake Technology Architecture
2022-07-22 16:56:00 【YoungerChina】
1. background
Large domestic Internet companies , Dozens of... Are generated every day 、 A few hundred TB, Even a few PB Raw data . These companies usually use open source big data components to build big data platforms . Big data platform experience “ With Hadoop Offline data platform represented by ”、“Lambda Architecture platform ”、“Kappa Architecture platform ” Three stages .
Data lake can be regarded as the latest generation of big data technology platform , In order to better understand the basic architecture of the data Lake , Let's first look at the evolution of big data platforms , So as to understand why we should learn data Lake Technology .

2. Offline big data platform - first generation
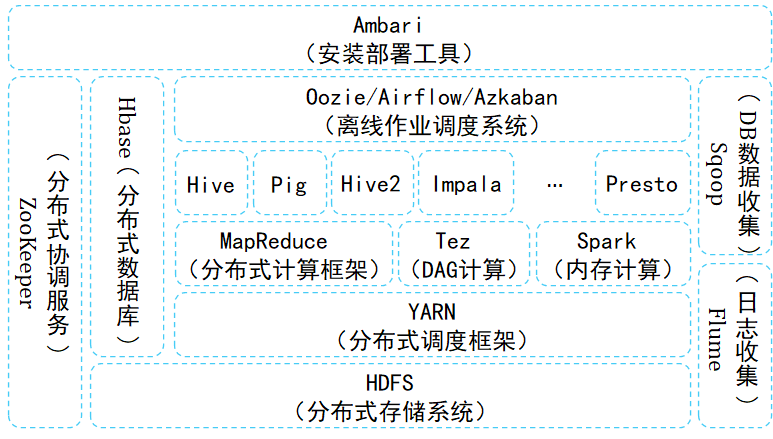
The first stage : With Hadoop Offline data processing components represented by .Hadoop In order to HDFS For core storage , With MapReduce It is the basic component of batch data processing of basic calculation model . around HDFS and MR, In order to continuously improve the data processing capacity of the big data platform , A series of big data components have been born , For example, real-time oriented KV Operation of the HBase、 oriented SQL Of Hive、 Workflow oriented Pig etc. . meanwhile , With the increasing demand for batch processing performance , New computational models have been proposed , Produced Tez、Spark、Presto Wait for the computing engine ,MR The model gradually evolved into DAG Model .
In order to reduce the intermediate result of data processing, write file operation ,Spark、Presto And other computing engines try to use the memory of the computing node to cache the data , So as to improve the efficiency of the whole data process and system throughput .
3. Lambda framework
3.1 Architecture introduction
With the continuous change of data processing capacity and processing requirements , More and more users are finding , Batch mode improves performance anyway , Nor can it meet the processing scenarios with high real-time requirements , Streaming computing engine came into being , for example Storm、Spark Streaming、Flink etc. .
However , With more and more applications online , We found , In fact, batch processing and stream computing are used together , To meet most application needs , Scenes with high real-time requirements , Will use Flink+Kafka Build a real-time stream processing platform , To meet the real-time needs of users . therefore Lambda Architecture proposed , As shown in the figure below .
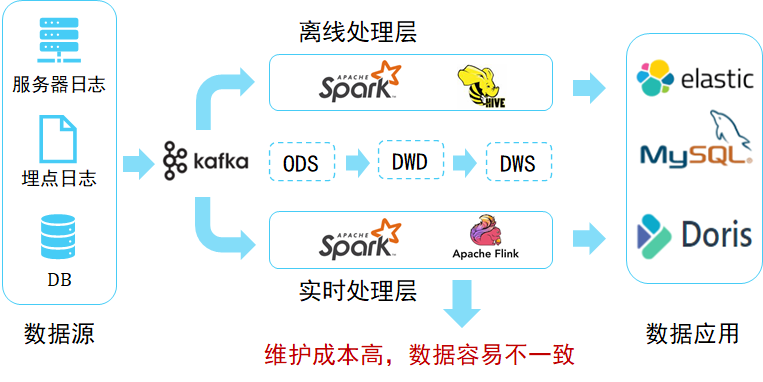
Lambda The core idea of architecture is “ Flow batch separation ”, As shown in the figure above , The entire data flow flows from left to right into the platform . After entering the platform, one is divided into two , Some of them go to batch processing mode , Part of the flow calculation mode . No matter which calculation mode , The final processing results are provided to the application through the service layer , Ensure consistency of access .
This data architecture contains many big data components , It greatly increases the complexity and maintenance cost of the overall architecture .
3.2 Pain points
After years of development ,Lambda The architecture is relatively stable , It can meet the past application scenarios . But it has many fatal weaknesses :

1、 High data governance costs
The real-time computing process cannot reuse the data kinship of the offline warehouse 、 Data quality management system . We need to re implement a set of data kinship for real-time computing 、 Data quality management system .
2、 The cost of development and maintenance is high
It is necessary to maintain both offline and real-time data warehouse systems , The same set of calculation logic needs to store two copies of data . for example , Update of one or more original data , You need to run the offline data warehouse again , The cost of data updating is very large .
3、 The data caliber is inconsistent
Because real-time computing and offline computing are completely different , Because the delayed arrival of data is different from the running time of the two types of code , Result in inconsistent calculation results .
So is there an architecture that can solve Lambda The problem of architecture ?
4. Kappa framework
Lambda Architecturally “ Flow batch separation ” Processing links increase the complexity of research and development . therefore , Some people ask whether we can use a system to solve all problems . At present, the more popular method is based on flow computing . So let's talk about that Kappa framework , adopt Flink+Kafka Connect the entire link in series .Kappa Architecture solves Lambda The computing engine in the architecture is inconsistent between the offline processing layer and the real-time processing layer , Development 、 The operation and maintenance cost is high , The calculation results are inconsistent .
4.1 Architecture introduction

Kappa The architecture scheme is also called “ Batch flow integration ” programme . We borrow Flink+Kafka To build a flow batch integration scenario , When need is right ODS For further analysis of layer data , take Flink The result of the calculation DWD Layer write to Kafka, It will also be part of DWS Calculation results of layer Kafka.Kappa The architecture is not perfect , It also has many pain points .
4.2 Pain points

1、 Weak data backtracking ability
Kafka Weak support for complex demand analysis , In the face of more complex data analysis , And we will DWD and DWS The data of the layer is written to ClickHouse、ES、MySQL Or is it Hive For further analysis , This undoubtedly brings the complexity of the link . The bigger problem is when doing data backtracking , Due to the complexity of the link, the data backtracking ability is very weak .
2、OLAP Weak analytical ability
because Kafka It is a sequential storage system , There is no way to implement sequential storage system directly OLAP Analytical , For example, predicate pushdown is an optimization strategy , On the sequential storage platform (Kafka) It is difficult to implement on .
3、 Data timing is challenged
Kappa The architecture is heavily dependent on message queuing , We know that the accuracy of the message queue itself depends strictly on the order of its upstream data , however , The more data layers of message queues , The greater the likelihood of disorder . Usually ,ODS The data of layer is absolutely accurate , hold ODS After calculation, the layer data is written to DWD There will be disorder when the layer is ,DWD To DWS More likely to cause disorder , Such data inconsistency is a big problem .
5. Summary of big data architecture pain points
From traditional hadoop The architecture goes to Lambda framework , from Lambda The architecture goes to Kappa Evolution of Architecture , The evolution of big data platform infrastructure gradually includes all kinds of data processing capabilities required by applications , But these platforms still have many pain points .

Is there a storage technology , It can not only support data efficient backtracking ability , Support data update , It can also read and write data in batches , And it can also realize data access from minute level to second level ?
6. Real time data warehouse construction needs
This is also the urgent need of real-time data warehouse construction . In fact, it can be done through Kappa Architecture upgrade , To solve the problem Kapp
a Some problems encountered in the architecture , Next, we will mainly share the current hot data Lake technology .

So is there such an architecture , It can meet the needs of real-time , It can also meet the requirements of offline computing , And it can also reduce the cost of development and operation , Solve the problem of Kappa Pain points encountered in architecture ? The answer is yes .
7. Data Lake Architecture
7.1 Data Lake concept
The data lake is a centralized repository , It can store structured and unstructured data . It can be stored as business data ( No need to structure the data first ), And run different types of analysis – From control panel and visualization to big data processing 、 Real time analysis and machine learning , To guide better decisions .

1. Store original data
- The data Lake needs enough storage capacity , It can store all the data of the company .
- Data lakes can store all kinds of data , Include structured 、 Semi structured (XML、Json etc. ) And unstructured data ( picture 、 video 、 Audio ).
- The data in the data lake is a complete copy of the original business data , These data maintain their original appearance in the business system .
2. Flexible underlying storage capabilities
In actual use , The data in the data lake is usually not accessed at high frequency , In order to achieve acceptable cost performance , Data Lake construction usually selects cost-effective storage engines ( Such as S3/OSS/HDFS).
- Provide large-scale storage for big data , And scalable large-scale data processing capabilities .
- May adopt S3/HDFS/OSS Equally distributed storage platform as storage engine .
- Support Parquet、Avro、ORC And other data structure formats .
- It can provide data cache acceleration function .
3. Rich computing engine
From batch calculation of data 、 Flow computation , Interactive query analysis to machine learning , All kinds of computing engines belong to the scope of data Lake . With the combination of big data and artificial intelligence technology , All kinds of machine learning / Deep learning algorithms have also been introduced , for example TensorFlow/PyTorch The framework already supports from HDFS/S3/OSS Read the sample data on the for machine learning training . therefore , For a qualified data Lake project , Pluggability of computing storage engine , It is the basic ability that the data Lake must have .
4. Perfect data management
- Data Lake needs to have perfect metadata management ability : Including data sources 、 data format 、 Connection information 、 data schema、 Authority management and other capabilities .
- Data Lake needs to have perfect data lifecycle management capability . It can not only store raw data , It also needs to be able to save the intermediate result data of various analysis and processing , And complete records of data analysis and processing process , Help users trace the generation process of any piece of data completely .
- Data Lake needs to have perfect data acquisition and data publishing capabilities . Data Lake needs to be able to support a variety of data sources , And can obtain the full amount from the relevant data source / Incremental data ; And then normalize the storage . Data lake can push data to the appropriate storage engine , To meet different application access needs .
7.2 Data Lake Architecture
LakeHouse Architecture has become the hottest trend of architecture evolution , Direct access to stored data management systems , It combines the main advantages of data warehouse .LakeHouse It is built based on the architecture of separation of storage and accounting . The biggest problem with the separation of storage and computing is the network , Especially for data warehouse with high-frequency access , Network performance is critical . Realization Lakehouse There are many options , such as Delta,Hudi,Iceberg. Although the emphasis of the three is different , But they all have the general function of data lake , such as : Unified metadata management 、 Support a variety of calculation and analysis engines 、 Support the separation of high-order analysis and computing storage .
So what is the general open source data Lake architecture like ? Here I draw an architecture diagram , There are four main levels :

1 distributed file system
The first layer is distributed file system , For users who choose cloud technology , Usually choose S3 And Alibaba cloud storage data ; Users who like open source technology generally use their own HDFS Store the data .
2 Data acceleration layer
The second layer is the data acceleration layer . Data Lake architecture is a typical storage computing separation architecture , The performance loss of remote reading and writing is very large . Our common practice is , Put frequently accessed data ( Hot data ) Cache locally on compute node , So as to realize the hot and cold separation of data . The advantage of this is , Improve data reading and writing performance , Save network bandwidth . We can choose open source Alluxio, Or Alibaba cloud Jindofs.
3 Table format layer
The third layer is Table format layer , Encapsulate data files into tables with business implications , The data itself provides ACID、snapshot、schema、partition Semantics of equal table level . This layer can choose open source data Lake three swordsmen Delta、Iceberg、Hudi One of .Delta、Iceberg、Hudi It is a technology of building data Lake , They are not data lakes in themselves .
4 Calculation engine
The fourth layer is various data computing engines . Include Spark、Flink、Hive、Presto etc. , These computing engines can access the same table in the data Lake .
8. Reference material
边栏推荐
猜你喜欢

解析优化机器人课程体系与教学策略

ffmpeg-rk3399 ffplay 学习分析
Bryntum Scheduler Pro 5.0.6 \Gantt\Crack

汉得aPaaS低代码平台 飞搭 2.3.0 RELEASE正式发布!

keepalived

When the win10 system is turned on, the response is slower than usual. How to solve it by turning around and waiting for 1 minute?

High number_ Chapter 2 differential calculus of multivariate functions_ Partial derivatives of implicit functions

14_响应模型

看融合数学教学的steam教育模式

5.SSH远程服务
随机推荐
tf.get_default_graph
numpy.ascontiguousarray
把握机器人教育朝AI智能化发展的趋势
数据湖:数据湖技术架构演进
What are the requirements for docking with the third-party payment interface?
Complex network modeling (propagation phenomenon on the network)
Sequence traversal BFS (breadth first)
UE4 用灰度图构建地形
CF464E The Classic Problem
UE4 修改默认缓存路径
解析参与机器人教育竞赛的热潮
High number_ Chapter 3 multiple integration
ORA-16525 dg broker不可用
I, AI doctoral student, online crowdfunding research topic
numpy.around
ES6 let and Const
UE4 键盘按键实现开关门
1143. 最长公共子序列
Li Kou daily question - day 41 -645. Wrong collection
视觉系统设计实例(halcon-winform)-8.匹配查找