当前位置:网站首页>Elasticsearch 第六篇:聚合統計查詢
Elasticsearch 第六篇:聚合統計查詢
2020-11-06 20:10:00 【itread01】
前面一直沒有記錄 Elasticsearch 的聚合查詢或者其它複雜的查詢。本篇做一下筆記,為了方便測試,索引資料依然是第五篇生成的測試索引庫 db_student_test ,別名是 student_test
第一部分 基本聚合
1、最大值 max、最小值 min、平均值 avg 、總和 sum
場景:查詢語文、數學、英語 這三科的最大值、最小值、平均值
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs" : {
"max_chinese" : { "max" : { "field" : "chinese" } },
"min_chinese" : { "min" : { "field" : "chinese" } },
"avg_chinese" : { "avg" : { "field" : "chinese" } },
"max_math": { "max" : { "field" : "math" } },
"min_math": { "min" : { "field" : "math" } },
"avg_math": { "avg" : { "field" : "math" } },
"max_english": { "max" : { "field" : "english" } },
"min_english": { "min" : { "field" : "english" } },
"avg_english": { "avg" : { "field" : "english" } }
}
}
查詢結果是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"avg_english": {
"value": 57.78366490546798
},
"max_chinese": {
"value": 98
},
"min_chinese": {
"value": 25
},
"min_math": {
"value": 15
},
"max_english": {
"value": 98
},
"avg_chinese": {
"value": 59.353859695794505
},
"avg_math": {
"value": 56.92907568735187
},
"min_english": {
"value": 21
},
"max_math": {
"value": 99
}
}
}
也可以來查詢語文科目分數總和,相當於 sql 的 sum 邏輯,雖然在這裡並沒有什麼意義:
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs" : {
"sum_chinese" : { "sum" : { "field" : "chinese" } }
}
}
2、求個數,相當於 sql 的 count 邏輯
場景:查詢所有學生總數,這裡隨便 count 一個 欄位就可以,例如數學這個欄位
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs": {
"age_count": {
"value_count": {
"field": "math"
}
}
}
}
返回結果是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_count": {
"value": 50084828
}
}
}
課間總數是:50084828 跟第五篇我們生成的資料總量一致
3、distinct 聚合,相當於 sql 的 count ( distinct )
場景:統計語文成績有多少種值
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "chinese"
}
}
}
}
返回結果是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"type_count": {
"value": 74
}
}
}
從結果上看,只有74個不同的分數,與第五篇隨機生成資料的規則匹配
4、統計聚合
場景:查詢語文成績 總個數、最大值、最小值、平均值、總和等
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs": {
"chinese_stats": {
"stats": {
"field": "chinese"
}
}
}
}
返回結果是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"chinese_stats": {
"count": 50084828,
"min": 25,
"max": 98,
"avg": 59.353859695794505,
"sum": 2972727854
}
}
}
5、加強版統計聚合,查詢結果在上面的基礎上,加上方差等統計學上的資料
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs": {
"chinese_stats": {
"extended_stats": {
"field": "chinese"
}
}
}
}
6、分位聚合統計
預設的分位是 1% 5% 25% 50% 75% 95% 99% 《= 的概念
分位數的概念:25% 的分位數是 54,意思是小於等於 54 的樣本佔據了總樣本的 25% ,即是 54 這個數將最底層的1/4 的資料分割出來。
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs": {
"chinese_percents": {
"percentiles": {
"field": "chinese"
}
}
}
}
也可以自定義分位:
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs": {
"chinese_percents": {
"percentiles": {
"field": "chinese",
"percents" : [10,20,30,40,50,60,70,80,90]
}
}
}
}
7、範圍聚合統計
場景:分別查詢語文成績小於40分、小於50分、小於60分的比例
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs": {
"gge_perc_rank": {
"percentile_ranks": {
"field": "chinese",
"values": [40,50,60]
}
}
}
}
以上是查詢成績小於40,小於50,小於60的佔比,得到的資料是: 21.29% 36.09% 51.12% 可以看到這是一個接近等差的數列,可見測試資料的隨機性還是很好的。
第二部分 其它聚合方式
1、Term 聚合
場景:想知道學生的語文成績,在所有分數值上的個數
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "chinese"
}
}
}
}
這個查詢會將欄位Chinese進行聚合,例如87分聚合成一個組,88分聚合成一個組,等等;
但是這裡預設是按組的大小排序,而且不會將所有的組都顯示出來,數量太小的組可能被忽略,查詢結果如下:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"genres": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 42560269,
"buckets": [
{
"key": 61,
"doc_count": 752863
},
{
"key": 68,
"doc_count": 752835
},
{
"key": 55,
"doc_count": 752749
},
{
"key": 59,
"doc_count": 752444
},
{
"key": 76,
"doc_count": 752405
},
{
"key": 74,
"doc_count": 752309
},
{
"key": 56,
"doc_count": 752283
},
{
"key": 49,
"doc_count": 752273
},
{
"key": 52,
"doc_count": 752201
},
{
"key": 50,
"doc_count": 752197
}
]
}
}
}
如果想要自定義篩選條件,Term聚合還可以按照以下設定來查詢:
post http://localhost:9200/student_test1/_search?size=0
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "chinese",
"size" : 100, // 可能有100個不用的分數,我們將全部都展示出來
"order" : { "_count" : "asc" }, // 按照組數由小到大排序
"min_doc_count": 752200 //過濾條件:組數最小值是752200
}
}
}
}
查詢結果是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"genres": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 52,
"doc_count": 752201
},
{
"key": 49,
"doc_count": 752273
},
{
"key": 56,
"doc_count": 752283
},
{
"key": 74,
"doc_count": 752309
},
{
"key": 76,
"doc_count": 752405
},
{
"key": 59,
"doc_count": 752444
},
{
"key": 55,
"doc_count": 752749
},
{
"key": 68,
"doc_count": 752835
},
{
"key": 61,
"doc_count": 752863
}
]
}
}
}
2、Filter 聚合
Filter 聚合會先進行條件過濾,在進行聚合
場景:查詢華南理工大學的學生的數學科目平均分(先篩選學校,再進行分數統計聚合)
{
"aggs" : {
"scut_math_avg" : {
"filter" : { "term": { "school": "華南理工大學" } },
"aggs" : {
"avg_price" : { "avg" : { "field" : "math" } }
}
}
}
}
查詢結果是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"scut_math_avg": {
"doc_count": 1854993,
"avg_price": {
"value": 56.93080027795253
}
}
}
}
3、Filters 多重聚合
場景:查詢各個學校,語文、數學、英語的平均分都是多少,可以採用多重聚合,速度可能有點慢,如下
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs" : {
"messages" : {
"filters" : {
"filters" : {
"school_1" : { "term" : { "school" : "華南理工大學" }},
"school_2" : { "term" : { "school" : "中山大學" }},
"school_3" : { "match" : { "school" : "暨南大學" }}
}
},
"aggs" : {
"avg_chinese" : { "avg" : { "field" : "chinese" } },
"avg_math" : { "avg" : { "field" : "math" } }
}
}
}
}
於是得到結果:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"messages": {
"buckets": {
"school_1": {
"doc_count": 1854993,
"avg_chinese": {
"value": 59.353236912484306
},
"avg_math": {
"value": 56.93080027795253
}
},
"school_2": {
"doc_count": 1855016,
"avg_chinese": {
"value": 59.349129064115886
},
"avg_math": {
"value": 56.93540918245449
}
},
"school_3": {
"doc_count": 44519876,
"avg_chinese": {
"value": 59.35397212247402
},
"avg_math": {
"value": 56.92948502372289
}
}
}
}
}
}
4、Range 範圍聚合
場景:想要查詢語文成績各個分數段的人數,可以這樣查詢
POST http://localhost:9200/student_test1/_search?size=0
{ "aggs" : { "chinese_ranges" : { "range" : { "field" : "chinese", "ranges" : [ { "to" : 60 }, { "from" : 60, "to" : 75 }, { "from" : 75, "to" : 85 }, { "from" : 85 } ] } } } }
查詢結果是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"chinese_ranges": {
"buckets": [
{
"key": "*-60.0",
"to": 60,
"doc_count": 25096839
},
{
"key": "60.0-75.0",
"from": 60,
"to": 75,
"doc_count": 11278543
},
{
"key": "75.0-85.0",
"from": 75,
"to": 85,
"doc_count": 7424634
},
{
"key": "85.0-*",
"from": 85,
"doc_count": 6284812
}
]
}
}
}
這個返回結果的組名分別是 *-60.0 60.0-75.0 75.0-85.0 85.0-*
如果我們不想要這樣的組名,可以自定義組名,例如:
POST http://localhost:9200/student_test1/_search?size=0
{
"aggs" : {
"chinese_ranges" : {
"range" : {
"field" : "chinese",
"keyed" : true,
"ranges" : [
{ "key" : "不及格", "to" : 60 },
{ "key" : "及格", "from" : 60, "to" : 75 },
{ "key" : "良好", "from" : 75, "to" : 85 },
{ "key" : "優秀", "from" : 85 }
]
}
}
}
}
查詢結果將會是:
{
"took": 1675,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"chinese_ranges": {
"buckets": {
"不及格": {
"to": 60,
"doc_count": 25096839
},
"及格": {
"from": 60,
"to": 75,
"doc_count": 11278543
},
"良好": {
"from": 75,
"to": 85,
"doc_count": 7424634
},
"優秀": {
"from": 85,
"doc_count": 6284812
}
}
}
}
}
還有其它各種各樣的、複雜的聚合查詢,都是可以網上查資料,甚至還支援推薦系統的一些計算方法,例如矩陣的概念等等。
還可以參考 https://blog.csdn.net/alex_xfboy/article/details/8610
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢
https://www.itread01.com/content/1604650142.html
边栏推荐
- Electron应用使用electron-builder配合electron-updater实现自动更新
- 连肝三个通宵,JVM77道高频面试题详细分析,就这?
- 免费的专利下载教程(知网、espacenet强强联合)
- 6.8 multipartresolver file upload parser (in-depth analysis of SSM and project practice)
- Top 10 best big data analysis tools in 2020
- c++学习之路:从入门到精通
- 用Python构建和可视化决策树
- 选择站群服务器的有哪些标准呢?
- Dapr實現分散式有狀態服務的細節
- 链表的常见算法总结
猜你喜欢
Pattern matching: The gestalt approach一种序列的文本相似度方法

车的换道检测
【C/C++ 1】Clion配置与运行C语言

Technical director, to just graduated programmers a word - do a good job in small things, can achieve great things
连肝三个通宵,JVM77道高频面试题详细分析,就这?
python 保存list数据
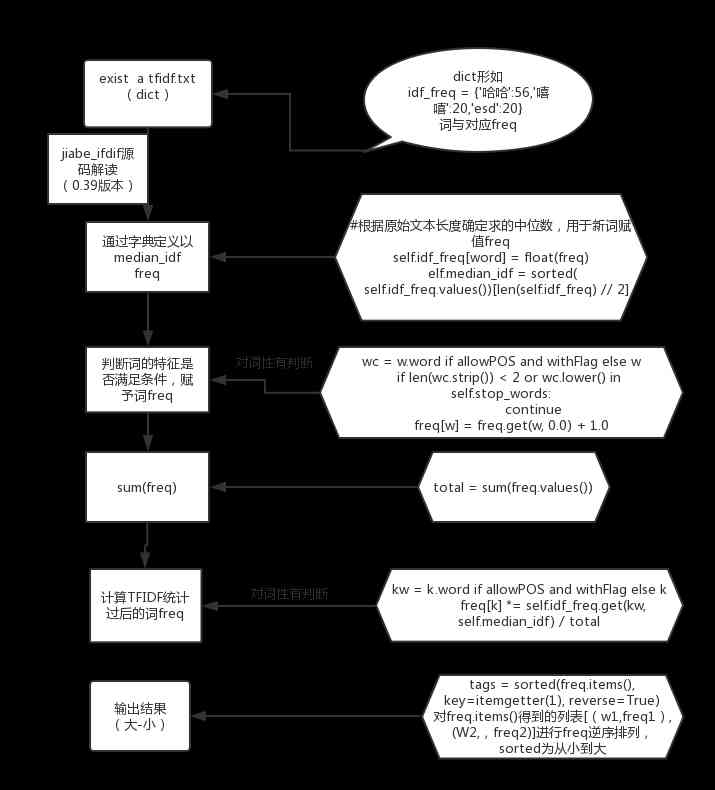
python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库

Pycharm快捷键 自定义功能形式
文本去重的技术方案讨论(一)

【C/C++ 2】Clion配置与运行C语言
随机推荐
从零学习人工智能,开启职业规划之路!
DevOps是什么
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
Asp.Net Core learning notes: Introduction
C language 100 question set 004 - statistics of the number of people of all ages
DTU连接经常遇到的问题有哪些
7.2.1 cache configuration of static resources
有关PDF417条码码制的结构介绍
中国提出的AI方法影响越来越大,天大等从大量文献中挖掘AI发展规律
高级 Vue 组件模式 (3)
使用Asponse.Words處理Word模板
利用 AWS SageMaker BlazingText 对不均衡文本进行多分类
python 保存list数据
简直骚操作,ThreadLocal还能当缓存用
不吹不黑,跨平臺框架AspNetCore開發實踐雜談
[performance optimization] Nani? Memory overflow again?! It's time to sum up the wave!!
Cocos Creator 原始碼解讀:引擎啟動與主迴圈
用Keras LSTM构建编码器-解码器模型
Jmeter——ForEach Controller&Loop Controller
神经网络简史