当前位置:网站首页>PIPNet:面向自然场景的人脸关键点检测《Pixel-in-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild》
PIPNet:面向自然场景的人脸关键点检测《Pixel-in-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild》
2022-07-19 01:05:00 【烧技湾】


单位:MBZUAI,起源研究院(邵岭团队)
ArXiv: https://arxiv.org/abs/2003.03771
Github: https://github.com/jhb86253817/PIPNet
导读:人脸关键点的研究在人脸编辑(抖音各种效果)、人脸识别和表情识别等方面起着越来越重要的作用。本篇文章从几个角度来解决识别过程中遇到的挑战比如如何鲁棒性检测极端面部、如何兼顾速度与精度等,1、提出一个新的范式,除了传统的坐标回归与热力图回归,很大程度上解决了速度的问题;2、针对人脸关键点的特性,提出了近邻约束,增强了鲁棒性。3、提出一个自训练策略,进一步提升跨域检测性能。作者没有设计新的网络结构,但从训练策略再到面向任务的特性着手,也能提供了有价值的参考意义。

一个好用的gif制作与压缩网址: https://ezgif.com/
摘要
当前,热力图回归模型因其在人脸关键点识别中取得了卓越的性能而变得流行。但是,这些模型之间仍然存在三个主要的问题:
- 这些模型的计算量很大;
- 他们通常缺乏对全局形状的明确约束;
- 不同领域间的间隙普遍存在。
为了解决这些问题,作者提出了PIPNet用于人脸关键点检测(facial landmark detection, FLD)。所提出的模型配备了一个基于热力图回归的新型检测头,它能够在低分辨率的特征图上同时预测得分与偏移量。通过这样做,重复上采样过程就不再需要,使得推导时间大大降低而不牺牲模型精度。此外,一个简单而有效的近邻回归模型被提出,通过融合相邻监测点的预测来强制局部约束,能够提升新检测头的鲁棒性。为了进一步提升PIPNet跨领域泛化性能,作者提出带有课程的自我训练。这种训练策略能够从跨域的未标注的数据中挖掘更多可靠的伪标签,它通过从一个简单的任务开始,逐渐增加难度以提供更精确的标签。大量实验证明了PIPNet的优越性,它能在有监督的设置下,在6个流行的数据集上取得三个新的领先结果。与基线方法比较,在两个跨域测试集上结果也是持续提升。值得注意是,作者提出PIPNet轻量级版本在CPU和GPU下分别取得了35和200FPS的速度,同时保持了一个有竞争力的精度与领先的方法比较。
一、介绍
1.1 基本定义
面部关键点定位旨在定位人脸上预定义的关键点,其结果可用于多个人脸分析任务,如人脸识别、人脸跟踪、面部编辑等。这些应用通常在不受控的环境下在线运行,需要人脸关键点检测子能够同时准确、鲁棒和计算效率高。
1.2 新的检测范式:除了热力图和坐标回归之外
在过去几年中,该领域取得了重大进展,特别被端到端的CNN推动。在最近研究中,一些方法重在改进损失函数;一些方法专注数据增强以更好泛化;还有一些方法解决语义歧义问题。但是,很少研究针对检测头的研究,尽管对于FLD检测器非常重要。特别地,检测头能够影响精度、鲁棒性和模型的效率。对于基于深度学习的FLD,通常有两种常用的检测头,即基于热力图回归和坐标回归。热力图回归方法能够取得好结果,但是它有两个缺陷:一是运算量大,二是对异常情况很敏感。相反,坐标回归的方法快而鲁棒,但不够准确。尽管坐标回归方法能够以多阶段方式产生更好的结果,它的推理速度还是比较慢。因此,作者尝试去回答下列问题:是否有检测头能够同时具有两者的优势?
1.3 跨域的泛化性能
跨域的泛化能力是FLD另一个挑战。有研究表明,在域内和跨域测试集上存在巨大性能差距。为了模型能够在不受约束的环境下稳健执行,域间间隙尽可能小。当前有一些工作解决这个问题,通过有监督训练一个模型,然后直接在跨域数据集上评估性能。作者将这种范式称为可泛化的有监督学习(Generalizable Supervised Learning, GSL)。它的缺点是它依赖人工设计模型进行跨域泛化,可扩展性不好。或许有人建议直接在多个数据库上使用监督学习去训练模型,但人工标注的成本太高而不现实。因此,作者去探索可泛化的半监督学习(Generalizable Semi-Supervised Learning, GSSL)应用于FLD,它能够使用跨域中的标注和未标注数据去获取更好泛化能力。与GSL相比,GSSL更具扩展性因为它是数据驱动的,并且无标签样本相对更容易获取。无监督领域适应性(unsupersived domain adaptation, UDA),作为GSSL的一种特殊情况,已经在图像识别、目标检测和行人重识别等任务中成功采用。但是对于FLD,UDA有效性仍未可知。
上图展示了几种训练与测试范式的区别。可以发现,GSSL和UDA之间的区别主要在于:GSSL对于无标签数据域不是非常严格,而UDA通常要求无标签数据与测试数据通常来自同一个数据域。
二、贡献
为了获得有效的面部关键点检测器,能够在自然场景下运行,作者提出了一个新模型叫PIPNet,它有三个核心部分:
- PIP回归;
- 一个近邻回归模块;
- 带有课程的自训练方法。
PIP回归,也就是PIPNet的检测头,基于热力图回归,除了预测分数之外,进一步预测在每个特征图像素中的偏移量。通过这样做,模型仍然能够获得好结果,甚至网络的步长比较大(即会产生低分辨率的特征图)时候。因此,为了热力图回归的上采样层能够去掉而节省可观的运算开销,而不牺牲精度。
启发于坐标回归,近邻回归模块的设计是为了提升PIP回归的鲁棒性。对于每个面部标记点,近邻回归模型能够预测在每个特征图像素中近邻标记点的位置。在额外的边际成本下,近邻回归模型能够提升模型鲁棒性,通过引入局部约束到预测的标记点形状中。通过PIP回归和近邻回归模块,该模型继承了热力图和坐标回归的优点。实际上,热力图和坐标回归可以看成PIP回归在不同滑动步长的两个特殊例子。此外,作者还证明了PIP在偏差-方差均衡下的优越性(此处,需要弄清楚,就要看对应章节)。
为了更好利用跨域的无标签样本,作者提出带有课程的自训练方法用于可泛化的半监督学习。与标准的自监督方法不同,带有课程的自训练从一个更简单的任务开始,然后逐渐增强难度去获取更多细化的伪标签。通过这种方式,从估计的伪标签中引入更少的误差,缓解了自训练中的错误强化问题。
二、方法
2.1 PIP回归

如上图所示,当前面部关键点检测器能够分为两类,基于检测头的类型,即坐标回归和热力图回归。图3a所示,坐标回归方法从全链接层中输出了一个2N长度的向量,其中N表示标注点的数量。图3b所示,热力图回归方法首先逐渐上采样提取到的特征图到与输入具有相同相似的分辨率,然后输出N个通道的热力图,每个通道反应了对应标注点位置的似然估计。当比较两个检测头时,不难发现坐标回归方式计算更加高效因为热力图回归方法要么需要重复上采样特征图或在整个网络中保持高分辨率特征图。然后,热力图方法被证明始终超过坐标回归方法,在检测精度上。
作者提出一种新检测头,PIP回归是建立在热力图回归基础上。作者觉得针对特征图上的关键点定位,上采样层不是必须的。也就是说,低分辨率特征图对于定位是足够的。通过使用在低分辨率特征图上的热力图回归,作者获取针对每个关键点在热力图上最可能的点。为了获得更加准确地预测,作者同样在热力图x和y轴上预测偏移量,偏移量是相对每个格子的左上角而言。值得注意的是,PIP回归是个单阶段的方法,因为分数和偏移量预测对两者是独立的,因此能够并行计算,其输出有一张分数图( N × H M × W M N \times H_M \times W_M N×HM×WM)和一张偏移图( 2 N × H M × W M 2N \times H_M \times W_M 2N×HM×WM)。这个提出的检测图能够简单地通过一个 1 × 1 1 \times 1 1×1卷积层实现。
 上图反应了PIPNet如何从一个真实标签转化到热力图标签。假设图4a)是一张 256 × 256 256 \times 256 256×256的输入图片,右眼内角上的红点表示目标真实标注点,并且网络步长设置为32。那么,最后一层的特征图尺度为 8 × 8 8 \times 8 8×8。从图中可以看到,对于每个通道上的特征图有64个格子,我们假设落入真实标记点的格子是正样本格子,在得分图上设置为1,其它设置为0.由于真实标记点相对格子左上角有30%的x轴偏移,因此在x-偏移图上设置为0.3。同样,在y偏移图上设置为0.8。剩下设置为0.。对于PIP回归的训练误差可以表述为:
上图反应了PIPNet如何从一个真实标签转化到热力图标签。假设图4a)是一张 256 × 256 256 \times 256 256×256的输入图片,右眼内角上的红点表示目标真实标注点,并且网络步长设置为32。那么,最后一层的特征图尺度为 8 × 8 8 \times 8 8×8。从图中可以看到,对于每个通道上的特征图有64个格子,我们假设落入真实标记点的格子是正样本格子,在得分图上设置为1,其它设置为0.由于真实标记点相对格子左上角有30%的x轴偏移,因此在x-偏移图上设置为0.3。同样,在y偏移图上设置为0.8。剩下设置为0.。对于PIP回归的训练误差可以表述为:
L = L S + α L O L = L_S + \alpha L_O L=LS+αLO
其中, L S L_S LS是分数预测的损失, L O L_O LO是偏移预测的损失, α \alpha α是平衡系数。具体来说,针对一张( N × H M × W M N \times H_M \times W_M N×HM×WM)分数图的损失,可以表达为:
其中, S ∗ S* S∗表示真实分数值, S ′ S' S′表示预测的分数值,NHM是归一项,针对一张( 2 N × H M × W M 2N \times H_M \times W_M 2N×HM×WM)偏移图的损失,可以表达为:

其中, o ∗ o* o∗表示真实的偏移值, o ‘’ o‘’ o‘’表示预测的偏移值。2N是归一化项,不难发现, L O L_O LO仅仅在正样本的格子点上计算,而 L S L_S LS在得分图上所有的格子上计算。并且,它们使用了不同的损失函数,因为前者是实际上一个分类问题,后者是一个回归问题。根据研究表明,针对回归问题,L1损失能够产生更好结果,这与我们实验结果保持一致。而针对分类问题,L2损失更好。在推理阶段,一个标记点的最终预测计算为具有最高响应的网格位置和对应偏移量进行细化而来。
PIP回归的一个超参是网络的步长。给出图像尺度和网络步长,热力图的尺度能够由下得到:
H M = H I S , W M = W I S H_M = \frac{H_I}{S}, W_M = \frac{W_I}{S} HM=SHI,WM=SWI
直观来讲,PIP回归可以看成是当前两个检测头的一个泛化表达。当网络步长与输入尺度相等时,即 H M = W M = 1 H_M=W_M=1 HM=WM=1,并且去掉得分模块,PIP回归可以看成是坐标回归,其中卷积全链接可以被卷积层代替。当网络步长等于1时,移除偏移量预测,PIP回归等同于热力图回归(虽然在实现细节上仍然存在差别,如标签平滑和关键点推理)。
2.2 近邻回归模块
尽管提出的PIP回归能够处理热力图回归中计算效率的问题,但鲁棒性比较差。下图展示了使用坐标回归、热力图回归和PIP回归去预测的示意图。

如图5a所示,坐标回归方法输出预测具有合理的全局形状,即使在大图上(如第4、5和7张),但是在细节上不够准确,可以看到预测值与真实值之间在某些部位存在明显的偏移,如图1中眼睛和嘴巴区域。因此,坐标回归方法可能不适合用于检测细微变化如眨眼睛和开合嘴等,但这些对于反欺骗功能是非常必要的。反而,图5b展示热力图方法在刻画细节方面更好,但对于具有极端姿势的图像给出不一致的形状(如第4-7张)。同样,PIP回归缺乏极端姿态下的鲁棒性,如图5c(第4-7张)所示,尽管获取比热力图方法更好的归一化均值误差(normalized mean error, NME)。对于基于热力图的模型,不难理解鲁棒性差的原因,因为它们的预测是基于不同特征,即特征图中的不同位置,因此每一个都是独立的。反而,所有基于坐标回归的预测的关键点共享同一特征,我们觉得这一点是鲁棒性的关键。
基于以上发现,我们进一步提出近邻回归模型(neighbor regression module,NRM),帮助PIP回归预测更一致的标记点。详细来说,除了添加每个关键点自身的偏移量,每个关键点同时预测它C个近邻的偏移量。NRM进一步输出一个近邻图,大小为 2 C N × H M × W M 2CN \times H_M \times W_M 2CN×HM×WM,其中C表示需要预测近邻点的个数。简单地,我们使用欧氏距离作为近邻的度量。
在添加NRM之后,PIPNet的训练误差可以表示为:
L = L S + α L O + β L N L = L_S + \alpha L_O+ \beta L_N L=LS+αLO+βLN
其中,LN是NRM的损失,可以定义为: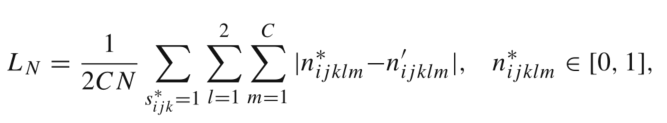
其中,n*表示真实近邻偏移值,n’表示预测的近邻偏移值。2CN是归一化项,LN同样采用L1损失,因为也是回归问题。在推理阶段,每个关键点除了收集它自己的预测值外,还接受其他关键点预测它的位置,然后计算他们的平均值作为最终输出。
在NRM帮助下,PIP回归变得更加鲁棒性,在变得更加精确同时,如图5d所示。由于很小的误差不容易通过图像感知,作者进一步将错误转换为条形图,以便更清晰说明。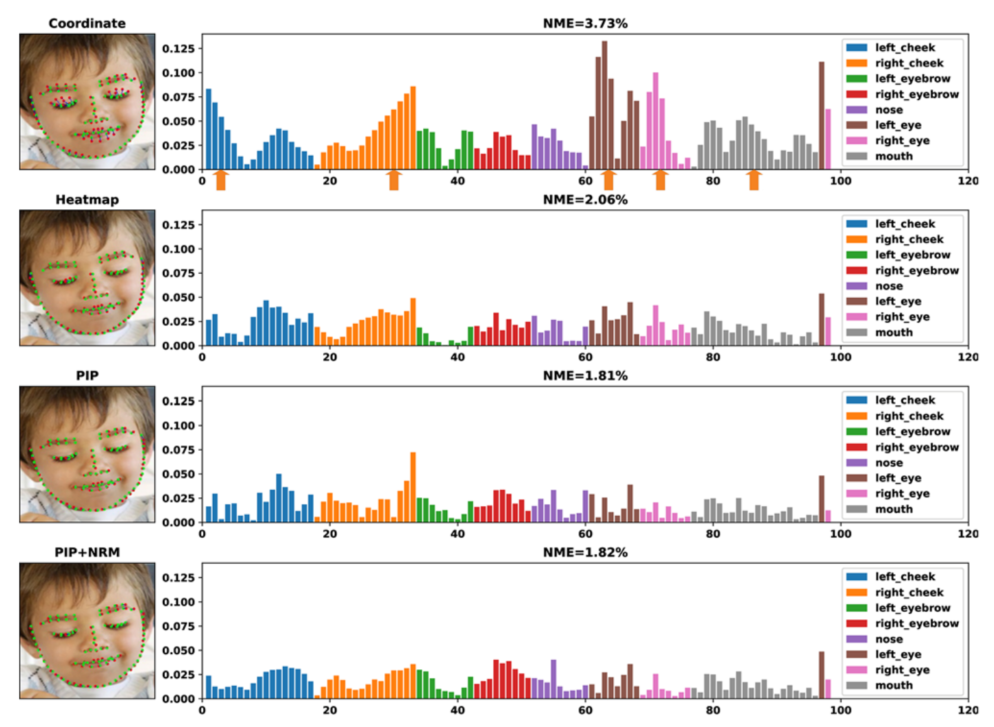 图6a中的图像比较简单,坐标回归的预测在左右脸颊、左右眼、嘴巴区域有明显的偏移,这就是它得到最差的NME=3.73%的原因。
图6a中的图像比较简单,坐标回归的预测在左右脸颊、左右眼、嘴巴区域有明显的偏移,这就是它得到最差的NME=3.73%的原因。
实验
在 300W、COFW 和 AFLW 上与最先进的方法进行比较
边栏推荐
- 带你认识C语言自定义类型——结构体、枚举、联合
- Is it safe to open Huatai account on your mobile phone?
- 个人开发的解ctf usb的键盘流量的工具 KeyboardTraffic
- ovirt: api
- 《PyTorch深度学习实践》学习笔记:卷积神经网络(高级篇)
- LeetCode 练习——剑指 Offer 32 - III. 从上到下打印二叉树 III
- DOM operation of JS - Events
- DOM operation of JS - event type
- Daily question brushing record (XXVII)
- 亲测五种高效实用的脱单方法,赶紧收藏帮你快速找到优质对象!
猜你喜欢
The difference between router and switch

VLAN aggregation

Understand the scope of the synchronized synchronization lock

Conditions and details of polar coordinate substitution for solving the limit of multivariate functions with high numbers

防电子墨水屏ST7302

Deep understanding of ArrayList
华为虚拟化FusionCompute知识点总结

【LeetCode每日一题】——108.将有序数组转换为二叉搜索树

Solution to expiration of visual studio tomato plug-in -- continue to resume trial

重磅!中国开源地图正式启动,诚挚邀请所有开源社区加入共创~
随机推荐
React.Context和redux缓存的数据无法跨浏览器Tab共享,怎么解决?
【C 练习】公务员面试
Tutoriel de requête SQL pour la science des données avec mon serveur SQL
DeFi 2.0的LaaS协议Elephant,重振DeFi赛道发展的关键
rman备份压缩比例?5倍左右
VIM编辑器的宏操作
二——01Day:對象的索引理解,對象上的this指向,對象轉換為字符串,函數的預解析,arguments.callee的用法,
迭代器和生成器(es6)
商业中心vr全景拍摄制作帮助商家有效吸引人流
</ script>& lt; script> console. log(7890)-{" xxx" :" aaa
DOM operation of JS - event type
亲测五种高效实用的脱单方法,赶紧收藏帮你快速找到优质对象!
fuser和lsof的用法
[C exercise] arrow pattern
.NET 序列化枚举为字符串
二——01Day:对象的索引理解,对象上的this指向,对象转换为字符串,函数的预解析,arguments.callee的用法,
华为虚拟化FusionCompute知识点总结
Financial banking software testing super large strategy, the most popular financial banking big secret cover questions
线程与进程------理论篇
【文件操作的重难点详解】