当前位置:网站首页>[infrastructure] [flink] Flink / Flink CDC code to achieve business access
[infrastructure] [flink] Flink / Flink CDC code to achieve business access
2022-07-22 00:05:00 【0xYGC】
brief introduction
DataStream and FlinkSQL A comparison of ways
DataStream stay Flink1.12 and 1.13 Both can be used. , and FlinkSQL Only in Flink1.13 Use .
DataStream It can monitor multiple databases and tables at the same time , and FlinkSQL Only a single table can be monitored .
Method / step
One : Encoding
1.1 Import correlation dependency
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<!-- You can hit dependency to jar In bag -->
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
1.2 Business coding
1.2.1 Entrance class
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/** * Description: * * @author: YangGC */
public class FlinkCDC2 {
public static void main(String[] args) throws Exception {
//1. obtain Flink execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 Turn on Checkpoint
env.enableCheckpointing(5000);
env.getCheckpointConfig().setCheckpointTimeout(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));
//2. adopt FlinkCDC structure SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("192.168.1.220")
.port(3308)
.username("root")
.password("useradmin")
//flinkcdc All the watches below
.databaseList("flinkcdc.*")
// .tableList("flinkcdc.user_info")
// Use a custom deserializer
.deserializer(new CustomerDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3. The data to print
dataStreamSource.print();
//4. Start the task
env.execute("FlinkCDC2");
}
}
1.2.2 Custom deserializer
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
/** * Custom deserializer * Description: * * @author: YangGC */
public class CustomerDeserializationSchema implements DebeziumDeserializationSchema<String> {
/** * { * "db":"", * "tableName":"", * "before":{"id":"1001","name":""...}, * "after":{"id":"1001","name":""...}, * "op":"" * } */
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
// establish JSON Object is used to encapsulate the result data
JSONObject result = new JSONObject();
// Get library name & Table name
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
result.put("db", fields[1]);
result.put("tableName", fields[2]);
// obtain before data
Struct value = (Struct) sourceRecord.value();
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
// Get column information
Schema schema = before.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
beforeJson.put(field.name(), before.get(field));
}
}
result.put("before", beforeJson);
// obtain after data
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
// Get column information
Schema schema = after.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
afterJson.put(field.name(), after.get(field));
}
}
result.put("after", afterJson);
// Get operation type
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
result.put("op", operation);
// Output data
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
1.3 Business packaging

Packing is done :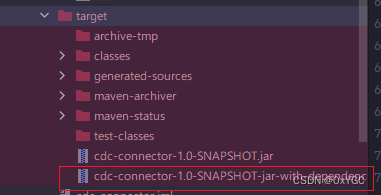
Two :Flink Job to task panel
2.1 Add tasks from the command line
hold cdc-connector-1.0-SNAPSHOT-jar-with-dependencies.jar Packages uploaded to To flink Home directory
And run the following command line
# It mainly configures the entry class Appoint flink The running address of
bin/flink run -m 127.0.0.1:8081 -c com.yanggc.cdc.FlinkCDC2 ./cdc-connector-1.0-SNAPSHOT-jar-with-dependencies.jar

- Job panel view job Running


View the normal monitoring output of the business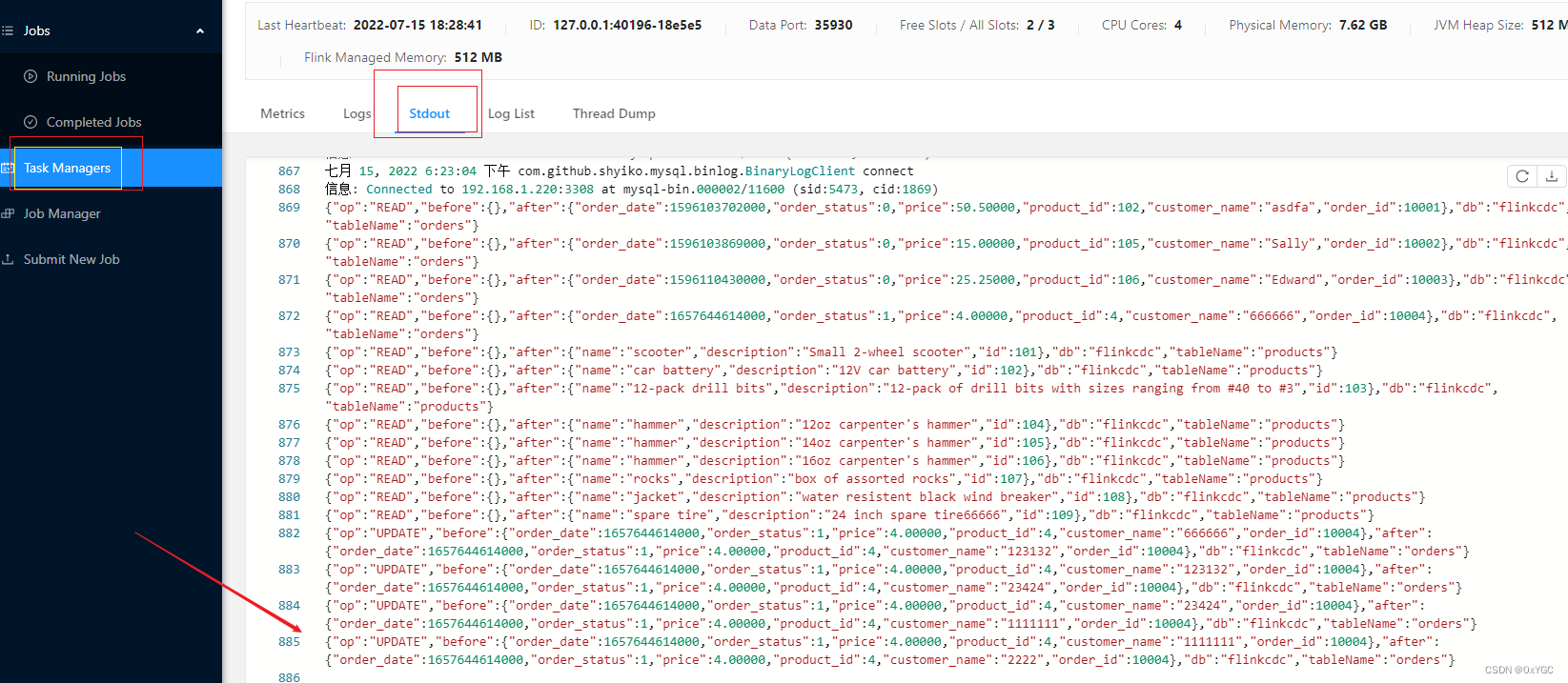
2.2 Upload Jar Package to add tasks
- Add relevant parameters

And command line startup related effects , Normal and successful startup for monitoring

Reference material & thank
边栏推荐
- JMeter read response header information / get request header
- win7系统忘记登录密码怎么办?(不用启动盘情况下)
- Learn IO from simple to deep
- Video 36 Chapter 13
- Deployment of three centers in two places
- Lamp架构——mysql集群及组复制(3)
- [CSV data file configuration of JMeter configuration component]
- Architecture lamp - routeur MySQL (séparateur lecture - écriture)
- view
- JMeter之WebService(soap)请求
猜你喜欢

MySQL multi table Association delete / update

How to test insert and update statements before execution
LAMP架構——mysql路由器(讀寫分離器)

Implementation of static address book

Analysis of cross apply and outer apply query of SQL Server - Part I
FigDraw 16. Dendrogram of SCI article drawing

Peoplecode objects and classes

Realize information exchange between pages
PeopleSoft warning, error, message box

Lamp架构——mysql集群及组复制(3)
随机推荐
Video 36 Chapter 13
Class inheritance experiment report
LR load balancer management, distributed load generator
Centos7 configuring MySQL multiple instances
Jenkins build
File download, how to write the use case?
Install cross compiler: eabi-4.3.3_ EmbedSky_ 20100610.tar. bz2
Common methods and applications of request
Peoplecode assigns values based on context references
JDBC access database
Importance of database monitoring
Learn IO from simple to deep
[secondary development of GeoServer] development of rest automatic deployment module based on GeoServer Manager
How to choose the model for remote real machine test?
Does Navicat 16 support native Apple silicon M1 chips| Apple user must read
Vote | choose the database you want Navicat to support
How to do app installation test?
JMeter之JDBC连接/操作数据库
1056 Mice and Rice
Enterprises and individuals choose cloud terminals or cloud servers for cloud desktops? You will know after reading this article