当前位置:网站首页>Mysql, I'll create 200W pieces of data casually and tell you about paging optimization.
Mysql, I'll create 200W pieces of data casually and tell you about paging optimization.
2022-07-21 03:06:00 【Small target youth】
Preface
【 Consultation 1 】

MySql Index failure 、 Back to table parsing 【 Gentlemen Chen , Read this first 】
【 Consultation II 】
Text
Don't talk much , First check the goods on the spot , Create a 200w Data :
Prepare a table :
Build a function to create data :

It is estimated that many beginners may rarely write these , No problem , You can try to play together :
CREATE DEFINER=`mytoor`@`%` FUNCTION `JcTestData`() RETURNS int(11)
BEGIN
DECLARE num INT DEFAULT 2000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
INSERT INTO test_order(`platform_sn`,`third_sn`,`type`,`create_time`)
VALUES(CONCAT('SN',i),UUID(),1,now());
SET i = i + 1;
END WHILE;
RETURN i;
END
Just say it , If you see clearly, you can ignore this ( Still learning that sentence , It's just a prophet who knows later ):

Click on the run :
29 Finished in seconds , just so so .

The goods have arrived , Ready to start :

Start the drill :
First give type Add an index , Simulate a real query scenario :


Put a few more pieces of data type Change the data a little ,:
First, query by page according to the normal scenario limit 0,50:
sql:
select * FROM test_order where type=1 limit 0,50;
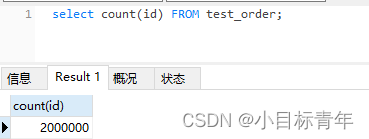
You can see the query limit 0,50 The speed is very fast ,0.022 second :

Next, we simulate it as a query N Data after page limit 1200000,50:
120W After the article , The offset 50 Data ,roll come out
sql:
select * FROM test_order where type=1 limit 1200000,50;
Look at the effect , It was used 3.765 second :
explain:

You can see that the index has been hit index_type , But it's still slow , Why? ?
The reason for the slow ①
① Indexes index_type It's a non clustered index , And our query statement yes select * , Contains other fields .
Through non clustered index index_type roll The data column , Only type and id , So in order to get other fields ,
You can get the clustered index first id , According to id Take out all column values , This is the operation of returning tables .
The reason for the slow ②
limit First number , The second number
limit Of roll What are the data rules ?
It's to be sure sql Eligible data ,
according to limit Of First number + The second number , First calculate The total amount of data to be scanned How much is the ,
Then go to traverse from the beginning to the first number of data rows , Start dropping to the return set ,
How many pieces are lost ? The second number determines how many pieces are lost .
limit Sample explanation
That is to say limit 0,50 :
Calculation 0+ 50 =50 , Take out the qualified 50 strip , Match the first number from the beginning 0,OK, from 0 At the beginning, you can throw the data into the return set .
How much is lost ? The second number is 50, So it will be lost one by one , lose 50 strip , Finally, return the data .
So if it is implemented in our article limit 1200000,50 :
120w+50 ....
It means to get 50 Data , Need to scan out 1200050 Data , Then start searching quickly. The first number is 120W, Start throwing away the front 120W A meaningless time , Then determine that the second number is 50, Start the whole process 50 Pieces of data are thrown into the return set , Finally, return the data .
Now that we know the situation , We can start to play optimization .
programme 1 :
Optimize the return table
If we can get the data we know to return id Set , As a condition , By hitting the non clustered index type When , You can get it directly id, This way id Take the data column , So it's convenient .
sql:
select * FROM test_order where id in
(
select id from (select id FROM test_order where type=1 limit 1200000,50) child
)
Look at the effect :

3.765 second Turned into 1.56 second !!!
3.765 second Turned into 1.56 second !!!
3.765 second Turned into 1.56 second !!!
Why? ?
explain have a look :

This situation is much faster , But is there still room for operation ?
answer : Yes .
You can see the current optimization sql , Actually Or does it involve limit 1200000,50 , This is the main time-consuming place .
programme 2:
Paging queries avoid skip page queries , Let's put the previous page id, As the starting condition of the next page .
The above analysis of this sql The rules of : Take a look at this limit 120W,50 Data of :
Take a look at this limit 120W,50 Data of :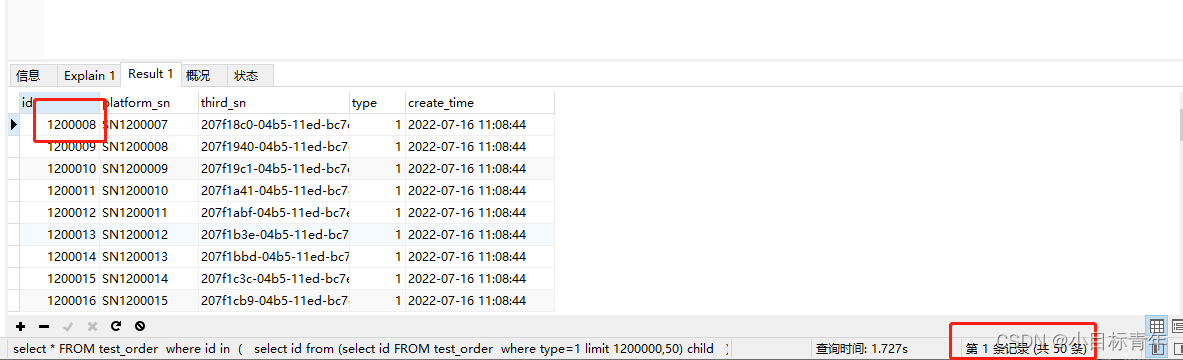
If we add Conditions id >=1200008 , Is it very nice 了 .
sql:
select * FROM test_order where type=1 and id >=1200008 limit 50;
Look at the effect ,0.022 second , Just like direct limit 0,50 Same efficiency :

explain:
Have been indexed by the primary key 
Service end usage scheme 2:
This situation , If it is used in our code , Only when operating large quantities of data , The last data of the last batch of data id Take it out .
Give the next batch of filtered data , As the smallest ID Of The conditions are good .
In fact, it is the paging optimization operation space left by an article I wrote before :
Springboot Manual paging query , Insert data in batches _ Blog of small target youth -CSDN Blog
Based on this article , add The smallest of the last batch ID As a condition , Double the efficiency !
Cooperate with the front-end use scheme 2:
Let's see a trigger mechanism call graph of a ready-made large system :
With sliding , Automatically load the next page of data , The beginning is the smallest of the previous page ID value ( You can also transfer other condition values ) Go to the next page . This is actually the sliding loading of our product experience , Waterfall flow form .
Okay , That's all for this article , Pay attention to me , give the thumbs-up , Collection ( Let me know you are , Let me know that you understand me ).
边栏推荐
- Usage and examples of Apache Doris binlog load
- 解决方案:业主单位智慧工地监管云平台
- 力扣(LeetCode)200. 岛屿数量(2022.07.19)
- X.509证书(结构+原理)
- win10基于IDEA,搭建Presto开发环境
- 二叉树实现(根据层级数组生成二叉树)
- 基于SSM实现水果蔬菜商城管理系统
- An interesting example to illustrate the difference of emplace_ back() and push_ back()
- Calculate the number of days from today
- 数据库事务(常被问的)
猜你喜欢

Qt 6.4中的Qt Quick 3D物理
Apache Doris Grafana监控指标介绍

记录一次C# 使用FFmempeg提取音频文件

Vben admin time selector related configuration and setting of unselectable time
Usage and examples of Apache Doris binlog load
![[AD learning record] copper clad](/img/83/bd2eeec3b165ef53dfbd5038f37f0d.png)
[AD learning record] copper clad

Win10 builds Presto development environment based on idea

DOM之事件对象

ZigBee safety overview
Zigbee安全概述
随机推荐
Apache Doris ODBC appearance PostgreSQL User Guide
[wechat applet] text field input with maximum word limit (1/100)
Idea starts the same project multiple times
Towards Representation Alignment and Uniformity in Collaborative Filtering
Apache Doris ODBC外表数据库主流版本及其ODBC版本对应关系
How should enterprise users choose aiops or APM?
消息队列(MQ)
【科学文献计量】关键词的挖掘与可视化
三极管原理
J9数字平台论:元宇宙中DeFi的可能性和局限性
Silicon Valley classroom notes (Part 1)
第11章 网络物理隔离技术原理与应用
Flink Doris connector design
[scientific literature measurement] keyword mining and visualization
Apache Doris uses the Prometheus alertmanager module to send exception information to the nail alarm group
[flower carving experience] 20 Music Visualization: esp32_ Series attempts of C3 and ws2812b
How does apscheduler set tasks not to be concurrent
二叉树实现(根据层级数组生成二叉树)
With high concurrency, ratelimiter and semaphore are used to limit the flow of access resources
Deep learning 2-linear unit and gradient descent