当前位置:网站首页>Machine learning - detailed derivation of support vector machine theory (including explanation of examples) (IV)
Machine learning - detailed derivation of support vector machine theory (including explanation of examples) (IV)
2022-07-21 10:32:00 【Width in the journey~】
12. Nonlinear support vector machine and kernel function
Linearly separable : Use a separating hyperplane ω ⋅ x + b \omega\cdot x+b ω⋅x+b Separate the data set completely ;
Nonlinear separability : Separate data sets with a hypersurface .
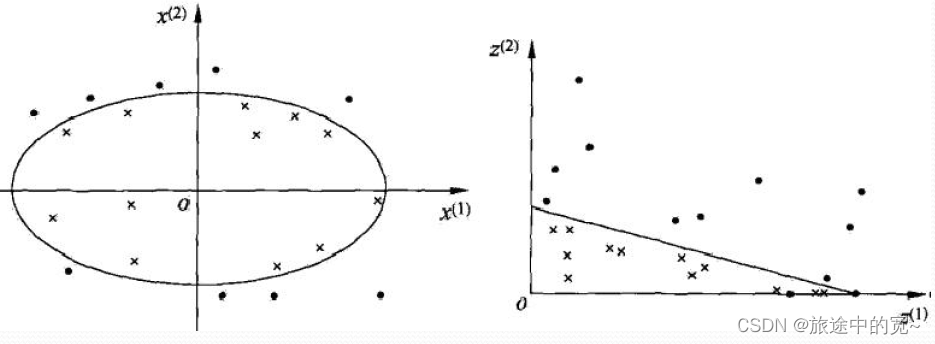
Nonlinear problems are often difficult to solve , So I hope to solve this problem by solving linear classification problems .
The method adopted is to make a nonlinear transformation , Transform nonlinear problems into linear problems , Solve the original nonlinear problem by solving the transformed linear problem .
namely : How to map points in the original space to points in the new space !
13. What is the use of kernel function ?
The original space : input space min ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 , α i ≥ 0 , i = 1 , 2 , ⋯ , N \begin{split} &\min\;\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_jy_iy_j(x_i\cdot x_j)-\sum_{i=1}^{N}\alpha_i\\ &s.t.\;\sum_{i=1}^{N}\alpha_iy_i=0\;,\;\alpha_i\geq0\;,\;i=1,2,\cdots,N \end{split} mini=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαis.t.i=1∑Nαiyi=0,αi≥0,i=1,2,⋯,N
In the upper form x i ⋅ x j x_i\cdot x_j xi⋅xj It's an inner product , In the new space, it may become z z z, Corresponding to Hilbert space , Be able to calculate z i ⋅ z j z_i\cdot z_j zi⋅zj.
Hope to find a mapping ϕ ( x ) : χ → \phi(x):\chi\rightarrow ϕ(x):χ→ H H H z i = ϕ ( x i ) , z j = ϕ ( x j ) z i ⋅ z j = ϕ ( x i ) ⋅ ϕ ( x j ) = K ( x i , x j ) \begin{split} &z_i=\phi(x_i)\;,\;z_j=\phi(x_j)\\ &z_i\cdot z_j=\phi(x_i)\cdot \phi(x_j)=K(x_i,x_j) \end{split} zi=ϕ(xi),zj=ϕ(xj)zi⋅zj=ϕ(xi)⋅ϕ(xj)=K(xi,xj)
If it can be achieved , Nonlinear support vector machine becomes :
min ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i \min\;\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(x_i,x_j)-\sum_{i=1}^{N}\alpha_i mini=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
Now let's look at an example :
K ( x , z ) = ( x ⋅ z ) 2 , x z ∈ R 2 K(x,z)=(x\cdot z)^2\;,\;x\;z\in R^2 K(x,z)=(x⋅z)2,xz∈R2
Excuse me, : ϕ → H \phi\rightarrow H ϕ→H?
Explain : x = ( x ( 1 ) , x ( 2 ) ) T , z = ( z ( 1 ) , z ( 2 ) ) T x=(x^{(1)},x^{(2)})^T\;,\;z=(z^{(1)},z^{(2)})^T x=(x(1),x(2))T,z=(z(1),z(2))T
K ( x , z ) = ( x ( 1 ) z ( 1 ) + x ( 2 ) z ( 2 ) ) 2 = ( x ( 1 ) z ( 1 ) ) 2 + 2 x ( 1 ) x ( 2 ) z ( 1 ) z ( 2 ) + ( x ( 2 ) z ( 2 ) ) 2 \begin{split} K(x,z)&=(x^{(1)}z^{(1)}+x^{(2)}z^{(2)})^2\\ &=(x^{(1)}z^{(1)})^2+2x^{(1)}x^{(2)}z^{(1)}z^{(2)}+(x^{(2)}z^{(2)})^2 \end{split} K(x,z)=(x(1)z(1)+x(2)z(2))2=(x(1)z(1))2+2x(1)x(2)z(1)z(2)+(x(2)z(2))2
We try H = R 3 H=R^3 H=R3
ϕ ( x ) = ( ( x ( 1 ) ) 2 , 2 x ( 1 ) x ( 2 ) , ( x ( 2 ) ) 2 ) T \phi(x)=((x^{(1)})^2,\sqrt{2}x^{(1)}x^{(2)},(x^{(2)})^2)^T ϕ(x)=((x(1))2,2x(1)x(2),(x(2))2)T
1) ϕ : R 2 → R 3 \phi:R^2\rightarrow R^3 ϕ:R2→R3
ϕ ( x ) ⋅ ϕ ( z ) = ( x ( 1 ) z ( 1 ) ) 2 + 2 x ( 1 ) x ( 2 ) z ( 1 ) z ( 2 ) + ( x ( 2 ) z ( 2 ) ) 2 = K ( x , z ) \phi(x)\cdot \phi(z)=(x^{(1)}z^{(1)})^2+2x^{(1)}x^{(2)}z^{(1)}z^{(2)}+(x^{(2)}z^{(2)})^2=K(x,z) ϕ(x)⋅ϕ(z)=(x(1)z(1))2+2x(1)x(2)z(1)z(2)+(x(2)z(2))2=K(x,z)
2) ϕ ( x ) = 1 2 ( ( x ( 1 ) ) 2 − ( x ( 2 ) ) 2 , 2 x ( 1 ) x ( 2 ) , ( x ( 1 ) ) 2 + ( x ( 2 ) ) 2 ) T ϕ ( x ) ⋅ ϕ ( z ) = K ( x , z ) \begin{split} &\phi(x)=\frac{1}{\sqrt{2}}((x^{(1)})^2-(x^{(2)})^2\;,\;2x^{(1)}x^{(2)}\;,\;(x^{(1)})^2+(x^{(2)})^2)^T\\ &\phi(x)\cdot \phi(z)=K(x,z) \end{split} ϕ(x)=21((x(1))2−(x(2))2,2x(1)x(2),(x(1))2+(x(2))2)Tϕ(x)⋅ϕ(z)=K(x,z)
For the same kernel function , There are many different mappings !
Let's summarize :
The original space : χ ∈ R 2 , x = ( x ( 1 ) , x ( 2 ) ) T ∈ χ \chi\in R^2\;,\;x=(x^{(1)},x^{(2)})^T\in \chi χ∈R2,x=(x(1),x(2))T∈χ
New space : Z ∈ R 2 , z = ( z ( 1 ) , z ( 2 ) ) T ∈ Z z = ϕ ( x ) = ( ( x ( 1 ) ) 2 , ( x ( 2 ) ) 2 ) T ⇒ ω 1 ( x ( 1 ) ) 2 + ω 2 ( x ( 2 ) ) 2 + b = 0 ⇒ ω 1 z ( 1 ) + ω 2 z ( 2 ) + b = 0 \begin{split} &Z\in R^2\;,\;z=(z^{(1)},z^{(2)})^T\in Z\\ &z=\phi(x)=((x^{(1)})^2,(x^{(2)})^2)^T\\ \Rightarrow &\omega_1(x^{(1)})^2+\omega_2(x^{(2)})^2+b=0\\ \Rightarrow &\omega_1z^{(1)}+\omega_2z^{(2)}+b=0 \end{split} ⇒⇒Z∈R2,z=(z(1),z(2))T∈Zz=ϕ(x)=((x(1))2,(x(2))2)Tω1(x(1))2+ω2(x(2))2+b=0ω1z(1)+ω2z(2)+b=0
There are two steps to solve the nonlinear classification problem with the linear classification method :
First, a transformation is used to map the data from the original space to the new space ;
Then in the new space, the linear classification learning method is used to learn the classification model from the training data .
Nuclear techniques belong to such methods .
Application of kernel technique to support vector machine , Its basic idea :
The input space is transformed by a nonlinear transformation ( Euclidean space R” Or discrete set ) Corresponding to a feature space ( Hilbert space ), Make the hypersurface model in the input space correspond to the hyperplane model in the feature space ( Support vector machine ). The learning task of classification problem is to solve the linear branch in the feature space
With vector machine, you can complete .
14. How to find a positive definite nucleus
primary : x i ⋅ x j x_i\cdot x_j xi⋅xj
new : ϕ ( x i ) ⋅ ϕ ( x j ) = K ( x i , x j ) \phi(x_i)\cdot \phi(x_j)=K(x_i,x_j) ϕ(xi)⋅ϕ(xj)=K(xi,xj) Kernel function
We want to replace the original inner product definition , The inner product of the same vector must be greater than or equal to 0, So finding a positive definite nucleus is the most appropriate .
Explain : First step : We want to find symmetric functions K ( x , z ) K(x,z) K(x,z)
x , z ∈ χ x,z\in\chi x,z∈χ, For input space .
Need to be right ∀ x 1 , x 2 , ⋯ , x m ∈ χ \forall x_1,x_2,\cdots,x_m\in\chi ∀x1,x2,⋯,xm∈χ, K ( x , z ) K(x,z) K(x,z) Corresponding G r a m Gram Gram Matrix positive semidefinite .
Why choose at will ? Because the training data set is uncertain .
our G r a m Gram Gram The matrix of the :
The original : [ x 1 ⋅ x 1 x 1 ⋅ x 2 ⋯ x 1 ⋅ x m x 2 ⋅ x 1 x 2 ⋅ x 2 ⋯ x 2 ⋅ x m ⋯ ⋯ ⋯ ⋯ x m ⋅ x 1 x m ⋅ x 2 ⋯ x m ⋅ x m ] \begin{bmatrix} x_1\cdot x_1 & x_1\cdot x_2 & \cdots & x_1\cdot x_m \\ x_2\cdot x_1 & x_2\cdot x_2 & \cdots & x_2\cdot x_m \\ \cdots & \cdots & \cdots & \cdots \\ x_m\cdot x_1 & x_m\cdot x_2 &\cdots &x_m\cdot x_m \end{bmatrix} ⎣⎡x1⋅x1x2⋅x1⋯xm⋅x1x1⋅x2x2⋅x2⋯xm⋅x2⋯⋯⋯⋯x1⋅xmx2⋅xm⋯xm⋅xm⎦⎤
new : [ K ( x 1 ⋅ x 1 ) K ( x 1 ⋅ x 2 ) ⋯ K ( x 1 ⋅ x m ) K ( x 2 ⋅ x 1 ) K ( x 2 ⋅ x 2 ) ⋯ K ( x 2 ⋅ x m ) ⋯ ⋯ ⋯ ⋯ K ( x m ⋅ x 1 ) K ( x m ⋅ x 2 ) ⋯ K ( x m ⋅ x m ) ] \begin{bmatrix} K(x_1\cdot x_1) & K(x_1\cdot x_2) & \cdots & K(x_1\cdot x_m) \\ K(x_2\cdot x_1) & K(x_2\cdot x_2) & \cdots & K(x_2\cdot x_m) \\ \cdots & \cdots & \cdots & \cdots \\ K(x_m\cdot x_1) & K(x_m\cdot x_2) &\cdots & K(x_m\cdot x_m) \end{bmatrix} ⎣⎡K(x1⋅x1)K(x2⋅x1)⋯K(xm⋅x1)K(x1⋅x2)K(x2⋅x2)⋯K(xm⋅x2)⋯⋯⋯⋯K(x1⋅xm)K(x2⋅xm)⋯K(xm⋅xm)⎦⎤
Our new matrix needs to satisfy positive semidefinite .
Definition of positive semidefinite : About matrix A A A, Yes ∀ x \forall x ∀x( Nonzero ) There is , x T A x ≥ 0 x^TAx\geq0 xTAx≥0, It's called matrix A A A It's positive semidefinite .
Definition of seminegative definite : x T A x ≤ 0 x^TAx\leq0 xTAx≤0
The definition of positive definite : x T A x > 0 x^TAx>0 xTAx>0
The definition of negative definite : x T A x < 0 x^TAx<0 xTAx<0
Our judgment method is as follows :
The first method : x T A x = y T D y ≥ 0 x^TAx=y^TDy\geq0 xTAx=yTDy≥0
among D D D It's a diagonal matrix , All elements are greater than or equal to 0.
look for A A A The characteristic root of the , All are greater than or equal to 0
The second method :
All primary and secondary determinants are greater than or equal to 0
15. New space under mapping
Let's review the previous definition of European space :
Our original space is called vector space or linear space , This space is characterized by addition (+) And number multiplication ( × \times ×) It's closed .
On this basis, we define the definition of inner product , Make the addition operation (+)、 Number multiplication ( × \times ×) And inner product operation ( ⋅ \cdot ⋅) It's closed . Form inner product space .
If we want to know the length of the vector , We introduce the definition of norm , Form normed linear space .
The vector space above 、 Inner product space 、 Normed linear space constitutes our common European space .
further , Want to study convergence and limit , All points are in space , be called B a n a c h Banach Banach Space .
If we didn't study the above content in the well-known Euclidean space , We changed a space , New inner products and norms are defined , And the space is complete , Called Hilbert space .
Specific implementation steps :
Explain : 1):
Form vector space ( Find the vector space )
ϕ \phi ϕ Expressed as : x → K ( ⋅ , x ) x\rightarrow K(\cdot,x) x→K(⋅,x)
about ∀ x i ∈ χ , α i ∈ R , i = 1 , 2 , ⋯ , m \forall x_i\in\chi\;,\;\alpha_i\in R\;,\;i=1,2,\cdots,m ∀xi∈χ,αi∈R,i=1,2,⋯,m
Definition : f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) f(\cdot)=\sum_{i=1}^{m}\alpha_iK(\cdot,x_i) f(⋅)=i=1∑mαiK(⋅,xi)
f f f Make up a set S S S, S S S Become a vector space .
verification : from S S S in ∀ f , g \forall f,g ∀f,g, Yes : f = ∑ i = 1 m α i K ( ⋅ , x i ) g = ∑ j = 1 v β j K ( ⋅ , z j ) \begin{split} &f=\sum_{i=1}^{m}\alpha_iK(\cdot,x_i)\\ &g=\sum_{j=1}^{v}\beta_jK(\cdot,z_j)\\ \end{split} f=i=1∑mαiK(⋅,xi)g=j=1∑vβjK(⋅,zj) f + g = ∑ i = 1 m α i K ( ⋅ , x i ) + ∑ j = 1 v β j K ( ⋅ , z j ) = ∑ i = 1 m + l a i K ( ⋅ , μ i ) ∈ S a f = ∑ i = 1 m a α i K ( ⋅ , x i ) , a α i ∈ R \begin{split} f+g&=\sum_{i=1}^{m}\alpha_iK(\cdot,x_i)+\sum_{j=1}^{v}\beta_jK(\cdot,z_j)\\ &=\sum_{i=1}^{m+l}a_iK(\cdot,\mu_i)\in S\\ af&=\sum_{i=1}^{m}a\alpha_iK(\cdot,x_i)\;,\;a\alpha_i\in R \end{split} f+gaf=i=1∑mαiK(⋅,xi)+j=1∑vβjK(⋅,zj)=i=1∑m+laiK(⋅,μi)∈S=i=1∑maαiK(⋅,xi),aαi∈R
in summary , S S S It is closed to addition and multiplication .
2) In collection S S S Define inner product on ( Inner product space )
Definition ∗ * ∗, Yes ∀ f , g ∈ S \forall f,g\in S ∀f,g∈S, We define :
f ∗ g = ∑ i = 1 m ∑ j = 1 l α i β j K ( x i , z j ) f*g=\sum_{i=1}^{m}\sum_{j=1}^{l}\alpha_i\beta_jK(x_i,z_j) f∗g=i=1∑mj=1∑lαiβjK(xi,zj)
The inner product must satisfy four conditions : { ( 1 ) : ( c f ) ∗ g = c ( f ∗ g ) , c ∈ R ( 2 ) : ( f + g ) ∗ h = f ∗ h + g ∗ h , h ∈ S ( 3 ) : f ∗ g = g ∗ f ( 4 ) : f ∗ f ≥ 0 ; f ∗ f = 0 ⇒ f = 0 \left\{ \begin{split} &(1):(cf)*g=c(f*g)\;,\;c\in R\\ &(2):(f+g)*h=f*h+g*h\;,\;h\in S\\ &(3):f*g=g*f\\ &(4):f*f\geq0\quad \quad ;f*f=0\Rightarrow f=0 \end{split} \right. ⎩⎨⎧(1):(cf)∗g=c(f∗g),c∈R(2):(f+g)∗h=f∗h+g∗h,h∈S(3):f∗g=g∗f(4):f∗f≥0;f∗f=0⇒f=0
Let's next verify whether four conditions are met :
The first is the first : l e f t : c f = c ∑ i = 1 m α i K ( ⋅ , x i ) = ∑ i = 1 m c α i K ( ⋅ , x i ) ( c f ) ∗ g = ∑ i = 1 m ∑ j = 1 l ( c α i ) β j K ( x i , z j ) = c ∑ i = 1 m ∑ j = 1 l α i β j K ( x i , z j ) = c ( f ∗ g ) = r i g h t \begin{split} left\;:\;&cf=c\sum_{i=1}^{m}\alpha_iK(\cdot,x_i)=\sum_{i=1}^{m}c\alpha_iK(\cdot,x_i)\\ (cf)*g&=\sum_{i=1}^{m}\sum_{j=1}^{l}(c\alpha_i)\beta_jK(x_i,z_j)\\ &=c\sum_{i=1}^{m}\sum_{j=1}^{l}\alpha_i\beta_jK(x_i,z_j)\\ &=c(f*g)=right \end{split} left:(cf)∗gcf=ci=1∑mαiK(⋅,xi)=i=1∑mcαiK(⋅,xi)=i=1∑mj=1∑l(cαi)βjK(xi,zj)=ci=1∑mj=1∑lαiβjK(xi,zj)=c(f∗g)=right
Then there is the second :
First we define : h = ∑ q = 1 t b q K ( ⋅ , v q ) h=\sum_{q=1}^{t}b_qK(\cdot,v_q) h=q=1∑tbqK(⋅,vq)
Make a i , i = 1 , 2 , ⋯ , m + l a_i\;,\;i=1,2,\cdots,m+l ai,i=1,2,⋯,m+l Instead of α 1 , α 2 , ⋯ , α m , β 1 , β 2 , ⋯ , β l \alpha_1,\alpha_2,\cdots,\alpha_m,\beta_1,\beta_2,\cdots,\beta_l α1,α2,⋯,αm,β1,β2,⋯,βl.
Make μ i , i = 1 , 2 , ⋯ , m + l \mu_i\;,\;i=1,2,\cdots,m+l μi,i=1,2,⋯,m+l Instead of x 1 , x 2 , ⋯ , x m , z 1 , z 2 , ⋯ , z l x_1,x_2,\cdots,x_m,z_1,z_2,\cdots,z_l x1,x2,⋯,xm,z1,z2,⋯,zl.
l e f t : ( f + g ) ∗ h = ∑ i = 1 m + l ∑ q = 1 t a i b q K ( μ i , v q ) r i g h t : ∑ i = 1 m ∑ q = 1 t α i b q K ( α i , v q ) + ∑ j = 1 l ∑ q = 1 t β j b q K ( z j , v q ) ⇒ l e f t = r i g h t \begin{split} &left\;:\;(f+g)*h=\sum_{i=1}^{m+l}\sum_{q=1}^{t}a_ib_qK(\mu_i,v_q)\\ &right\;:\;\sum_{i=1}^{m}\sum_{q=1}^{t}\alpha_ib_qK(\alpha_i,v_q)+\sum_{j=1}^{l}\sum_{q=1}^{t}\beta_jb_qK(z_j,v_q)\\ \Rightarrow &left=right \end{split} ⇒left:(f+g)∗h=i=1∑m+lq=1∑taibqK(μi,vq)right:i=1∑mq=1∑tαibqK(αi,vq)+j=1∑lq=1∑tβjbqK(zj,vq)left=right
Let's look at the third : Obviously, it has been established , because α i \alpha_i αi and β j \beta_j βj You can exchange , K ( x i , z j ) K(x_i,z_j) K(xi,zj) It's symmetrical , You can also change positions .
Finally, let's look at the fourth :
Let's start with the first part : f ∗ f ≥ 0 f*f\geq0 f∗f≥0
f ∗ f = ∑ i = 1 m ∑ j = 1 m α i α j K ( x i , x j ) f*f=\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jK(x_i,x_j) f∗f=i=1∑mj=1∑mαiαjK(xi,xj)
because K ( x i , z j ) K(x_i,z_j) K(xi,zj) It's symmetrical , therefore G r a m Gram Gram The matrix is positive semidefinite , Yes x T A x ≥ 0 x^TAx\geq0 xTAx≥0.
So there is f ∗ f ≥ 0 f*f\geq0 f∗f≥0
Next, let's look at the second part :
First, let's look at the sufficiency , That is, if there is f = 0 f=0 f=0. f = ∑ i = 1 m α i K ( ⋅ , x i ) → α i = 0 ⇒ f ∗ f = ∑ i = 1 m ∑ j = 1 m α i α j K ( x i , x j ) = 0 \begin{split} &f=\sum_{i=1}^{m}\alpha_iK(\cdot,x_i)\rightarrow \alpha_i=0\\ \Rightarrow &f*f=\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jK(x_i,x_j)=0 \end{split} ⇒f=i=1∑mαiK(⋅,xi)→αi=0f∗f=i=1∑mj=1∑mαiαjK(xi,xj)=0
The sufficiency is proved !
Before proving the necessity , Let's prove the next :
problem : ∀ f , g ∈ S , ( f ∗ g ) 2 ≤ ( f ∗ f ) ( g ∗ g ) \forall f\;,\;g\in S\;,\;(f*g)^2\leq(f*f)(g*g) ∀f,g∈S,(f∗g)2≤(f∗f)(g∗g)
Explain : take λ ∈ R \lambda\in R λ∈R f + λ g ∈ S ⇒ ( f + λ g ) ∗ ( f + λ g ) ≥ 0 ⇒ f ∗ f + 2 λ ( f ∗ g ) + λ 2 ( g ∗ g ) ≥ 0 \begin{split} f+\lambda g\in S&\Rightarrow (f+\lambda g)*(f+\lambda g)\geq0\\ &\Rightarrow f*f+2\lambda(f*g)+\lambda^2(g*g)\geq0\\ \end{split} f+λg∈S⇒(f+λg)∗(f+λg)≥0⇒f∗f+2λ(f∗g)+λ2(g∗g)≥0
We might as well change : ( g ∗ g ) λ 2 + 2 ( f ∗ g ) λ + f ∗ f ≥ 0 (g*g)\lambda^2+2(f*g)\lambda+f*f\geq0 (g∗g)λ2+2(f∗g)λ+f∗f≥0
Is our above formula very close to the problem of quadratic function , If you want to be greater than 0, Just let the discriminant Δ \Delta Δ Is less than or equal to 0 that will do .
That is, we know : 4 ( f ∗ g ) 2 − 4 ( g ∗ g ) ( f ∗ f ) ≤ 0 ⇒ ( f ∗ g ) 2 ≤ ( f ∗ f ) ( g ∗ g ) \begin{split} &4(f*g)^2-4(g*g)(f*f)\leq0\\ \Rightarrow &(f*g)^2\leq (f*f)(g*g) \end{split} ⇒4(f∗g)2−4(g∗g)(f∗f)≤0(f∗g)2≤(f∗f)(g∗g)
thus , Our conclusion is supported by . Next , Let's go back to the original question .
f = ∑ i = 1 m α i K ( ⋅ , x i ) f=\sum_{i=1}^{m}\alpha_iK(\cdot,x_i) f=i=1∑mαiK(⋅,xi)
because f , g f\;,\;g f,g Is arbitrary , Take something special g g g, Make g = K ( ⋅ , x ) g=K(\cdot,x) g=K(⋅,x) f ∗ g = ∑ i = 1 m α i K ( x , x i ) ( f ∗ g ) 2 = ∑ i = 1 m ∑ j = 1 m α i α j K ( x , x i ) K ( x , x j ) f ∗ f = ∑ i = 1 m ∑ j = 1 m α i α j K ( x i , x j ) g ∗ g = K ( x , x ) ( f ∗ f ) ( g ∗ g ) = ∑ i = 1 m ∑ j = 1 m α i α j K ( x i , x j ) K ( x , x ) ( f ∗ g ) 2 ≤ ( f ∗ f ) ( g ∗ g ) = 0 \begin{split} &f*g=\sum_{i=1}^{m}\alpha_iK(x,x_i)\\ &(f*g)^2=\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jK(x,x_i)K(x,x_j)\\ &f*f=\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jK(x_i,x_j)\\ &g*g=K(x,x)\\ &(f*f)(g*g)=\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jK(x_i,x_j)K(x,x)\\ &(f*g)^2\leq (f*f)(g*g)=0 \end{split} f∗g=i=1∑mαiK(x,xi)(f∗g)2=i=1∑mj=1∑mαiαjK(x,xi)K(x,xj)f∗f=i=1∑mj=1∑mαiαjK(xi,xj)g∗g=K(x,x)(f∗f)(g∗g)=i=1∑mj=1∑mαiαjK(xi,xj)K(x,x)(f∗g)2≤(f∗f)(g∗g)=0
Because square ( f ∗ g ) 2 ≥ 0 (f*g)^2\geq0 (f∗g)2≥0, So we can get : ( f ∗ g ) 2 = 0 ⇒ f ∗ g = 0 ⇒ ∑ i = 1 m α i K ( x , x i ) = 0 ⇒ α i = 0 ⇒ f = 0 \begin{split} &(f*g)^2=0\\ \Rightarrow &f*g=0\Rightarrow \sum_{i=1}^{m}\alpha_iK(x,x_i)=0\Rightarrow \alpha_i=0\Rightarrow f=0 \end{split} ⇒(f∗g)2=0f∗g=0⇒i=1∑mαiK(x,xi)=0⇒αi=0⇒f=0
in summary , ∗ * ∗ Represents inner product operation . At this point, our vector space becomes an inner product space .
We define f f f and g g g The inner product of is :
f ⋅ g = ∑ i = 1 m ∑ j = 1 l α i β j K ( x i , z j ) f\cdot g=\sum_{i=1}^{m}\sum_{j=1}^{l}\alpha_i\beta_jK(x_i,z_j) f⋅g=i=1∑mj=1∑lαiβjK(xi,zj)
3) In collection S Define norms on , Upgrade Hilbert space
Definition : ∣ ∣ f ∣ ∣ = f ⋅ f ||f||=\sqrt{f\cdot f} ∣∣f∣∣=f⋅f
At this time, the space is transformed into a normed linear space .
In new space K Characteristics : Regeneration ! Such as : f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) K ( ⋅ , x ) ⋅ f = ∑ i = 1 m α i K ( x , x i ) = f ( x ) \begin{split} &f(\cdot)=\sum_{i=1}^{m}\alpha_iK(\cdot,x_i)\\ &K(\cdot,x)\cdot f=\sum_{i=1}^{m}\alpha_iK(x,x_i)=f(x) \end{split} f(⋅)=i=1∑mαiK(⋅,xi)K(⋅,x)⋅f=i=1∑mαiK(x,xi)=f(x)
Another example : K ( ⋅ , x ) ⋅ K ( ⋅ , z ) = K ( x , z ) K(\cdot,x)\cdot K(\cdot,z)=K(x,z) K(⋅,x)⋅K(⋅,z)=K(x,z)
summary : What we do here is how to find a Hilbert space from the original space !
16. Necessary and sufficient conditions for positive definite kernel function
set up K : χ × χ → R K:\chi\times \chi\rightarrow R K:χ×χ→R It's a symmetric function , be K ( x , z ) K(x,z) K(x,z) The necessary and sufficient condition for a positive definite nucleus is ∀ x i ∈ χ , i = 1 , 2 , ⋯ , m \forall x_i\in\chi\;,\;i=1,2,\cdots,m ∀xi∈χ,i=1,2,⋯,m, K ( x , z ) K(x,z) K(x,z) Corresponding G r a m Gram Gram matrix K = [ K ( x i , x j ) ] m × m K=[K(x_i,x_j)]_{m\times m} K=[K(xi,xj)]m×m It's a positive semidefinite matrix .
Next, let's prove this conclusion :
First, let's look at the sufficiency :
K K K It's a positive semidefinite matrix , Our mapping is : ϕ : x → K ( ⋅ , x ) χ → H \begin{split} \phi\;:\;&x\rightarrow K(\cdot,x)\\ &\chi\rightarrow H \end{split} ϕ:x→K(⋅,x)χ→H
K ( ⋅ , x ) ⋅ K ( ⋅ , z ) = K ( x , z ) K(\cdot,x)\cdot K(\cdot,z)=K(x,z) K(⋅,x)⋅K(⋅,z)=K(x,z) It shows that it is regenerative , So at this time K ( x , z ) K(x,z) K(x,z) Positive definite kernel .
The need for :
K ( x , z ) K(x,z) K(x,z) Positive definite kernel , So there is the following mapping : χ → H x → ϕ ( x ) , z → ϕ ( z ) \begin{split} &\chi\rightarrow H\\ &x\rightarrow \phi(x)\;,\;z\rightarrow \phi(z) \end{split} χ→Hx→ϕ(x),z→ϕ(z)
We have : K ( ⋅ , x ) ⋅ K ( ⋅ , z ) = K ( x , z ) K(\cdot,x)\cdot K(\cdot,z)=K(x,z) K(⋅,x)⋅K(⋅,z)=K(x,z)
How to judge a matrix as a positive semidefinite matrix ? ∀ x 1 , x 2 , ⋯ , x m ∈ χ ∀ c 1 , c 2 , ⋯ , c m ∈ R c = ( c 1 , c 2 , ⋯ , c m ) T \begin{split} &\forall x_1,x_2,\cdots,x_m\in \chi\\ &\forall c_1,c_2,\cdots,c_m\in R\\ &c=(c_1,c_2,\cdots,c_m)^T \end{split} ∀x1,x2,⋯,xm∈χ∀c1,c2,⋯,cm∈Rc=(c1,c2,⋯,cm)T
K = [ K ( x 1 , x 1 ) K ( x 1 , x 2 ) ⋯ K ( x 1 , x m ) K ( x 2 , x 1 ) K ( x 2 , x 2 ) ⋯ K ( x 2 , x m ) ⋯ ⋯ ⋯ ⋯ K ( x m , x 1 ) K ( x m , x 2 ) ⋯ K ( x m , x m ) ] K=\begin{bmatrix} K(x_1,x_1) & K(x_1,x_2) & \cdots & K(x_1,x_m) \\ K(x_2,x_1) & K(x_2,x_2) & \cdots & K(x_2,x_m) \\ \cdots &\cdots & \cdots &\cdots\\ K(x_m,x_1) & K(x_m,x_2) & \cdots & K(x_m,x_m) \end{bmatrix} K=⎣⎡K(x1,x1)K(x2,x1)⋯K(xm,x1)K(x1,x2)K(x2,x2)⋯K(xm,x2)⋯⋯⋯⋯K(x1,xm)K(x2,xm)⋯K(xm,xm)⎦⎤
If there is : c T K c ≥ 0 c^TKc\geq0 cTKc≥0 said K K K Is a positive semidefinite matrix . At this time there is :
c T K c = ( c 1 , c 2 , ⋯ , c m ) [ K ( x 1 , x 1 ) K ( x 1 , x 2 ) ⋯ K ( x 1 , x m ) K ( x 2 , x 1 ) K ( x 2 , x 2 ) ⋯ K ( x 2 , x m ) ⋯ ⋯ ⋯ ⋯ K ( x m , x 1 ) K ( x m , x 2 ) ⋯ K ( x m , x m ) ] [ c 1 c 2 ⋯ c m ] c^TKc=(c_1,c_2,\cdots,c_m) \begin{bmatrix} K(x_1,x_1) & K(x_1,x_2) & \cdots & K(x_1,x_m) \\ K(x_2,x_1) & K(x_2,x_2) & \cdots & K(x_2,x_m) \\ \cdots &\cdots & \cdots &\cdots\\ K(x_m,x_1) & K(x_m,x_2) & \cdots & K(x_m,x_m) \end{bmatrix} \begin{bmatrix} c_1\\ c_2\\ \cdots\\ c_m \end{bmatrix} cTKc=(c1,c2,⋯,cm)⎣⎡K(x1,x1)K(x2,x1)⋯K(xm,x1)K(x1,x2)K(x2,x2)⋯K(xm,x2)⋯⋯⋯⋯K(x1,xm)K(x2,xm)⋯K(xm,xm)⎦⎤⎣⎡c1c2⋯cm⎦⎤
Method 1 : We use inner product operation ( c 1 , c 2 , ⋯ , c m ) [ ϕ ( x 1 ) ⋅ ϕ ( x 1 ) ϕ ( x 1 ) ⋅ ϕ ( x 2 ) ⋯ ϕ ( x 1 ) ⋅ ϕ ( x m ) ϕ ( x 2 ) ⋅ ϕ ( x 1 ) ϕ ( x 2 ) ⋅ ϕ ( x 2 ) ⋯ ϕ ( x 2 ) ⋅ ϕ ( x m ) ⋯ ⋯ ⋯ ⋯ ϕ ( x m ) ⋅ ϕ ( x 1 ) ϕ ( x m ) ⋅ ϕ ( x 2 ) ⋯ ϕ ( x m ) ⋅ ϕ ( x m ) ] [ c 1 c 2 ⋯ c m ] \ (c_1,c_2,\cdots,c_m) \begin{bmatrix} \phi(x_1)\cdot \phi(x_1) & \phi(x_1)\cdot \phi(x_2) & \cdots & \phi(x_1)\cdot \phi(x_m) \\ \phi(x_2)\cdot \phi(x_1) & \phi(x_2)\cdot \phi(x_2) & \cdots & \phi(x_2)\cdot \phi(x_m) \\ \cdots &\cdots & \cdots &\cdots\\ \phi(x_m)\cdot \phi(x_1) & \phi(x_m)\cdot \phi(x_2) & \cdots & \phi(x_m)\cdot \phi(x_m) \end{bmatrix} \begin{bmatrix} c_1\\ c_2\\ \cdots\\ c_m \end{bmatrix} (c1,c2,⋯,cm)⎣⎡ϕ(x1)⋅ϕ(x1)ϕ(x2)⋅ϕ(x1)⋯ϕ(xm)⋅ϕ(x1)ϕ(x1)⋅ϕ(x2)ϕ(x2)⋅ϕ(x2)⋯ϕ(xm)⋅ϕ(x2)⋯⋯⋯⋯ϕ(x1)⋅ϕ(xm)ϕ(x2)⋅ϕ(xm)⋯ϕ(xm)⋅ϕ(xm)⎦⎤⎣⎡c1c2⋯cm⎦⎤ = ( c 1 , c 2 , ⋯ , c m ) [ ϕ ( x 1 ) ϕ ( x 2 ) ⋯ ϕ ( x m ) ] [ ϕ ( x 1 ) , ϕ ( x 2 ) , ⋯ , ϕ ( x m ) ] [ c 1 c 2 ⋯ c m ] = ∣ ∣ ∑ i = 1 m c i ϕ ( x i ) ∣ ∣ 2 ≥ 0 =(c_1,c_2,\cdots,c_m) \begin{bmatrix} \phi(x_1)\\ \phi(x_2)\\ \cdots\\ \phi(x_m) \end{bmatrix} [\phi(x_1),\phi(x_2),\cdots,\phi(x_m)] \begin{bmatrix} c_1\\ c_2\\ \cdots\\ c_m \end{bmatrix} =||\sum_{i=1}^{m}c_i\phi(x_i)||^2\geq0 =(c1,c2,⋯,cm)⎣⎡ϕ(x1)ϕ(x2)⋯ϕ(xm)⎦⎤[ϕ(x1),ϕ(x2),⋯,ϕ(xm)]⎣⎡c1c2⋯cm⎦⎤=∣∣i=1∑mciϕ(xi)∣∣2≥0
Method 2 : Directly express quadratic form ∑ i , j = 1 m c i c j K ( x i , x j ) = ∑ i , j = 1 m c i c j ϕ ( x i ) ⋅ ϕ ( x j ) = ∑ i = 1 m ∑ j = 1 m [ c i ϕ ( x i ) ] ⋅ [ c j ϕ ( x j ) ] = [ c 1 ϕ ( x 1 ) + c 2 ϕ ( x 2 ) + ⋯ + c m ϕ ( x m ) ] ⋅ [ c 1 ϕ ( x 1 ) + c 2 ϕ ( x 2 ) + ⋯ + c m ϕ ( x m ) ] = ∣ ∣ ∑ i = 1 m c i ϕ ( x i ) ∣ ∣ 2 2 \begin{split} \sum_{i,j=1}^{m}c_ic_jK(x_i,x_j)&=\sum_{i,j=1}^{m}c_ic_j\phi(x_i)\cdot \phi(x_j)\\ &=\sum_{i=1}^{m}\sum_{j=1}^{m}[c_i\phi(x_i)]\cdot [c_j\phi(x_j)]\\ &=[c_1\phi(x_1)+c_2\phi(x_2)+\cdots+c_m\phi(x_m)]\cdot [c_1\phi(x_1)+c_2\phi(x_2)+\cdots+c_m\phi(x_m)]\\ &=||\sum_{i=1}^{m}c_i\phi(x_i)||_2^2 \end{split} i,j=1∑mcicjK(xi,xj)=i,j=1∑mcicjϕ(xi)⋅ϕ(xj)=i=1∑mj=1∑m[ciϕ(xi)]⋅[cjϕ(xj)]=[c1ϕ(x1)+c2ϕ(x2)+⋯+cmϕ(xm)]⋅[c1ϕ(x1)+c2ϕ(x2)+⋯+cmϕ(xm)]=∣∣i=1∑mciϕ(xi)∣∣22
Equivalent definition of positive definite kernel :
set up χ ∈ R n , K ( x , z ) \chi\in R^n\;,\;K(x,z) χ∈Rn,K(x,z) Is defined in χ × χ \chi\times\chi χ×χ Symmetric functions on , If the ∀ x i ∈ χ , i = 1 , 2 , ⋯ , m \forall x_i\in\chi\;,\;i=1,2,\cdots,m ∀xi∈χ,i=1,2,⋯,m, K ( x , z ) K(x,z) K(x,z) Corresponding G r a m Gram Gram matrix K = [ K ( x i , x j ) ] m × m K=[K(x_i,x_j)]_{m\times m} K=[K(xi,xj)]m×m It's a positive semidefinite matrix , said K ( x , z ) K(x,z) K(x,z) It's positive .
17. Common kernel functions
: Defined in European space
1) Polynomial kernel function K ( x , z ) = ( x ⋅ z + 1 ) p K(x,z)=(x\cdot z+1)^{p} K(x,z)=(x⋅z+1)p
The general form is : ( x ⋅ z + c ) p (x\cdot z+c)^{p} (x⋅z+c)p among c c c Is a constant .
Decision function :
f ( x ) = s i g n ( ∑ i = 1 N a i ∗ y i ⋅ ( x i ⋅ x + 1 ) p + b ∗ ) f(x)=sign(\sum_{i=1}^{N}a_i^{*}y_i\cdot(x_i\cdot x+1)^{p}+b^{*}) f(x)=sign(i=1∑Nai∗yi⋅(xi⋅x+1)p+b∗)
2) Gaussian kernel K ( x , z ) = e x p ( − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 ) K(x,z)=exp(-\frac{||x-z||^2}{2\sigma^2}) K(x,z)=exp(−2σ2∣∣x−z∣∣2)
Decision function :
f ( x ) = s i g n ( ∑ i = 1 N a i ∗ y i e x p ( − ∣ ∣ x − x i ∣ ∣ 2 2 σ 2 ) + b ∗ ) f(x)=sign(\sum_{i=1}^{N}a_i^{*}y_i{exp}(-\frac{||x-x_i||^2}{2\sigma^2})+b^{*}) f(x)=sign(i=1∑Nai∗yiexp(−2σ2∣∣x−xi∣∣2)+b∗)
: Defined on discrete data sets
The space corresponding to the string is mapped to the high-dimensional space :
[ ϕ n ( s ) ] μ = ∑ i , s ( i ) = μ λ ( i ) [\phi_n(s)]_{\mu}=\sum_{i,s(i)=\mu}\lambda^{(i)} [ϕn(s)]μ=i,s(i)=μ∑λ(i)
n n n Represents string length , s s s Is string , l ( i ) l(i) l(i) Represents the length of a small string .
Example : A text [’big’,’pig’,’bag’]
The length is 2 The substring of is [’bi’,’bg’,’ig’,’pi’,’pg’,’ba’,’ag’]
The feature space of projection takes R 7 R^7 R7, Calculate the length :( The last element position )-( The first position )+1
bi bg ig pi pg ba ag
big λ 2 \lambda^2 λ2 λ 3 \lambda^3 λ3 λ 2 \lambda^2 λ2 0 0 0 0
pig 0 0 λ 2 \lambda^2 λ2 λ 2 \lambda^2 λ2 λ 3 \lambda^3 λ3 0 0
bag 0 λ 3 \lambda^3 λ3 0 0 0 λ 2 \lambda^2 λ2 λ 2 \lambda^2 λ2
We came to the conclusion that : K ( b i g , p i g ) = λ 4 , K ( b i g , b a g ) = λ 6 K(big\;,\;pig)=\lambda^4\;,\;K(big\;,\;bag)=\lambda^6 K(big,pig)=λ4,K(big,bag)=λ6
The method of measuring the similarity between two strings can be used — Cosine similarity :
cos θ = x ⋅ y ∣ ∣ x ∣ ∣ ∣ ∣ y ∣ ∣ \cos\theta=\frac{x\cdot y}{||x||||y||} cosθ=∣∣x∣∣∣∣y∣∣x⋅y
Compare the similarity between two texts , Such as : K ( b i g , p i g ) ∣ ∣ K ( b i g , b i g ) ∣ ∣ ∣ ∣ K ( p i g , p i g ) ∣ ∣ = λ 4 λ 6 + 2 λ 4 λ 6 + 2 λ 4 = λ 4 λ 6 + 2 λ 4 = 1 2 + λ 2 \begin{split} &\frac{K(big,pig)}{||K(big,big)||||K(pig,pig)||}\\ =&\frac{\lambda^4}{\sqrt{\lambda^6+2\lambda^4}\sqrt{\lambda^6+2\lambda^4}}\\ =&\frac{\lambda^4}{\lambda^6+2\lambda^4}=\frac{1}{2+\lambda^2} \end{split} ==∣∣K(big,big)∣∣∣∣K(pig,pig)∣∣K(big,pig)λ6+2λ4λ6+2λ4λ4λ6+2λ4λ4=2+λ21
2) String kernel function [ ϕ n ( s ) ] μ = ∑ i , s ( i ) = μ λ ( i ) [\phi_n(s)]_{\mu}=\sum_{i,s(i)=\mu}\lambda^{(i)} [ϕn(s)]μ=i,s(i)=μ∑λ(i)
18. summary
Linear support vector machines
[ Linear support vector machines ]{}
Input : Training set T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}, among , x i ∈ χ ∈ R n , y i ∈ { − 1 , + 1 } x_i\in\chi\in R^n\;,\;y_i\in\{-1,+1\} xi∈χ∈Rn,yi∈{ −1,+1}.
Output : Separating hyperplane and classification decision function
Algorithm :
Given penalty coefficient c ≥ 0 c\geq0 c≥0, Construction optimization problem min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ c , i = 1 , 2 , ⋯ , N \begin{split} &\min_{\alpha}\;\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_jy_iy_j(x_i\cdot x_j)-\sum_{i=1}^{N}\alpha_i\\ &s.t.\;\sum_{i=1}^{N}\alpha_iy_i=0\;,\;0\leq\alpha_i\leq c\;,\;i=1,2,\cdots,N \end{split} αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαis.t.i=1∑Nαiyi=0,0≤αi≤c,i=1,2,⋯,N
Solve the optimization problem , Get the best solution
α ∗ = ( α 1 ∗ , α 2 ∗ , ⋯ , α N ∗ ) T \alpha^{*}=(\alpha_1^{*},\alpha_2^{*},\cdots,\alpha_N^{*})^T α∗=(α1∗,α2∗,⋯,αN∗)T
according to α ∗ \alpha^{*} α∗ solve ω ∗ = ∑ i = 1 N α i ∗ y i x i \omega^{*}=\sum_{i=1}^{N}\alpha_i^{*}y_ix_i ω∗=i=1∑Nαi∗yixi
Pick out the ones that match 0 < α i ∗ < c 0<\alpha_i^{*}<c 0<αi∗<c The point of ( x j , y j ) (x_j,y_j) (xj,yj) Calculation :
b ∗ = y j − ∑ i = 1 N α i ∗ y i ( x i ⋅ x j ) b^{*}=y_j-\sum_{i=1}^{N}\alpha_i^{*}y_i(x_i\cdot x_j) b∗=yj−i=1∑Nαi∗yi(xi⋅xj)
The separation hyperplane is : ω ∗ ⋅ x + b ∗ = 0 \omega^{*}\cdot x+b^{*}=0 ω∗⋅x+b∗=0
The decision function is : f ( x ) = s i g n ( ω ∗ ⋅ x + b ∗ ) f(x)=sign(\omega^{*}\cdot x+b^{*}) f(x)=sign(ω∗⋅x+b∗)
Nonlinear support vector machines
[ Nonlinear support vector machines ]
Algorithm :
Given penalty coefficient c ≥ 0 c\geq0 c≥0, Construction optimization problem min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ c , i = 1 , 2 , ⋯ , N \begin{split} &\min_{\alpha}\;\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(x_i,x_j)-\sum_{i=1}^{N}\alpha_i\\ &s.t.\;\sum_{i=1}^{N}\alpha_iy_i=0\;,\;0\leq\alpha_i\leq c\;,\;i=1,2,\cdots,N \end{split} αmin21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαis.t.i=1∑Nαiyi=0,0≤αi≤c,i=1,2,⋯,N
Solve the optimization problem , Get the best solution
α ∗ = ( α 1 ∗ , α 2 ∗ , ⋯ , α N ∗ ) T \alpha^{*}=(\alpha_1^{*},\alpha_2^{*},\cdots,\alpha_N^{*})^T α∗=(α1∗,α2∗,⋯,αN∗)T
according to α ∗ \alpha^{*} α∗ solve
ω ∗ = ∑ i = 1 N α i ∗ y i K ( ⋅ , x i ) \omega^{*}=\sum_{i=1}^{N}\alpha_i^{*}y_iK(\cdot,x_i) ω∗=i=1∑Nαi∗yiK(⋅,xi)
Pick out the ones that match 0 < α i ∗ < c 0<\alpha_i^{*}<c 0<αi∗<c The point of ( x j , y j ) (x_j,y_j) (xj,yj) Calculation :
b ∗ = y j − ∑ i = 1 N α i ∗ y i K ( x i , x j ) b^{*}=y_j-\sum_{i=1}^{N}\alpha_i^{*}y_iK(x_i,x_j) b∗=yj−i=1∑Nαi∗yiK(xi,xj)
Decision function : f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x , x i ) + b ∗ ) f(x)=sign(\sum_{i=1}^{N}\alpha_i^{*}y_iK(x,x_i)+b^{*}) f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
among x x x For new instances .
边栏推荐
- Calculate the rotation matrix between two vectors
- MySQL ON DELETE CASCADE(级联删除)[猿教程]
- 一套.Net Core学校管理系统源码
- 自注意力和 CNN 的结合 ACmix : On the Integration of Self-Attention and Convolution
- [bug solution] warning: grad and param do not obey the gradient layout contract This is not an error, but..
- LeetCode 0123.买卖股票的最佳时机III:常数空间下的动态规划+模拟
- Good at C (day 70)
- 一篇文章快速复习flex属性与用法
- mysql 常用基础命令
- If you know something about deep learning, you can send nature? It is more important to find the right problem and the problem with scientific value
猜你喜欢

论文速读:FAIR 最新 ViT 模型 改进多尺度 ViT --- Improved Multiscale Vision Transformers

redis6.2 systemd 启动 提示 redis.service: Failed with result ‘protocol‘.

Quick reading of the paper: axial deeplab: stand alone axial attention for panoramic segmentation
![[bug resolution] visibledeprecationwarning: creating an ndarray from ragged needed sequences](/img/41/f9fef517c917995e2bcc4d6cac5671.png)
[bug resolution] visibledeprecationwarning: creating an ndarray from ragged needed sequences

Introduction and learning of Jason

At the same time, RF interference signal inspection and mitigation are realized

宏创建内联函数读写cpu reg
![[论文速度] 同时解决成像时,曝光不足和曝光过度问题:Deep Reciprocating HDR Transformation](/img/66/b935ba29cf147a253c15e5eb9a4016.png)
[论文速度] 同时解决成像时,曝光不足和曝光过度问题:Deep Reciprocating HDR Transformation

Another lightweight vit:lite vision transformer with enhanced self attention

4 个简单操作,实现 CPU 轻量级网络 ---- PP-LCNet: A Lightweight CPU Convolutional Neural Network
随机推荐
连通块中点的数量(DAY 68)
语义分割-Rethinking BiSeNet For Real-time Semantic Segmentation-1-Cityscapes数据集
懂点深度学习,就能发 Nature ?找对问题、有科学价值的问题更重要
迅为龙芯开发板固态硬盘启动(烧写系统到固态)-分区
ModuleNotFoundError_ No_ module_ Popular explanations and methods of named
The k-th smallest array sum in an ordered matrix
论文速读:FAIR 最新 ViT 模型 改进多尺度 ViT --- Improved Multiscale Vision Transformers
UE5 官方案例LyraStarter 全特性详解 2.消息系统使用示例
Huawei cloud: serve everything, build a whole scene of smart Finance
Kubernetes应用程序设计指南
机器学习—支持向量机理论详细推导(含例题讲解)(三)
4.浸泡测试
实现一个《头像循环轮播控件》
有序矩阵中的第 k 个最小数组和
微信小程序开发学习5(自定义组件)
2022河南萌新联赛第(二)场:河南理工大学 I - 22数
看似简单的input框输入竟异常卡顿,记一个日常性能问题的排查思路
Layoutinflater layout rendering tool
Cluster chat server: Project Introduction
根据两个向量计算它们之间的旋转矩阵