当前位置:网站首页>Category loss and location loss of target detection
Category loss and location loss of target detection
2022-07-21 02:19:00 【Little aer】
List of articles
Category loss
Cross Entropy Loss
Cross entropy loss can be divided into two categories loss and multi category loss
Two categories of losses
For dichotomies ( namely 0-1 classification ), That is, it belongs to the third party 1 The probability of a class is p, Belong to the first 0 The probability of a class is 1−p. Then the binary cross entropy loss can be expressed as :
After the unified format is :
It can be understood as : When the actual category is 1 when , We want the forecast to be category 1 The probability is higher , here l o g ( p ) log(p) log(p) The greater the value of , The smaller the loss ; conversely , We want the forecast to be category 0 The probability is higher , here l o g ( 1 − p ) log(1−p) log(1−p) The greater the value of , The smaller the loss . in application , The category probability of two categories is usually sigmoid Function maps the result to (0,1) Between .
Multi class loss

among , Y i Y_i Yi It's a one-hot vector , And defined as follows :
p i j p_{ij} pij It means the first one i Three samples belong to the category j Probability . In practical application, we usually use SoftMax Function to get the probability that the sample belongs to each category .
derivative one-hot The establishment of vectors
nothing num_classes
import torch from torch.nn import functional as F x = torch.tensor([1, 1, 1, 3, 3, 4, 8, 5]) y1 = F.one_hot(x) # There is only one parameter tensor x print(f'x = ',x) print(f'x_shape = ',x.shape) print(f'y1 = ',y1) print(f'y1_shape = ',y1.shape)Output :
x = tensor([1, 1, 1, 3, 3, 4, 8, 5]) x_shape = torch.Size([8]) y = tensor([[0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 1, 0, 0, 0]]) y_shape = torch.Size([8, 9])Yes num_classes
y2 = F.one_hot(x, num_classes = 10) # here num_classes Set to 10, among 10 > max{x} print(f'x = ',x) # Output x print(f'x_shape = ',x.shape) # see x The shape of the print(f'y2 = ',y2) # Output y print(f'y2_shape = ',y2.shape)result :
x = tensor([1, 1, 1, 3, 3, 4, 8, 5]) x_shape = torch.Size([8]) y2 = tensor([[0, 1, 0, 0, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]]) y2_shape = torch.Size([8, 10])
difference : No category specified , As given x Maximum +1 As the number of categories , Otherwise, press the specified num_classes draw one-hot vector
Focal Loss
The word is put forward in RetinaNet In the article , The purpose is to Pay more attention to those samples that are difficult to classify in training , It suppresses the leading role of those easy to classify negative samples . Address of thesis
Focal Loss It is an improvement of the typical cross information entropy loss function , For a dichotomous problem , The cross information entropy loss function is defined as follows :( It just said )
In order to unify the loss function expression of positive and negative samples , First, make the following definition :( To put it bluntly p t p_t pt Is the probability of the sample )
p t p_t pt Formally, it represents the confidence of the correct category predicted to correspond . In this way, the entropy loss of two classification cross information can be rewritten as follows :
α \alpha α Balance positive and negative samples
In order to balance the losses of most classes and a few classes , A conventional idea is to multiply the loss term by an equilibrium coefficient α∈(0,1), When the category is positive , take α t = α \alpha_t = \alpha αt=α, When the category is negative , take α t = 1 − α \alpha_t = 1-\alpha αt=1−α, The cross information entropy loss with equilibrium coefficient obtained in this way is defined as follows :
such , Select according to the number of positive and negative samples in the training samples α \alpha α Value , We can balance the positive and negative samples . However , This does not differentiate between simple and difficult samples , In target detection , Balance most classes ( background ) And minority classes ( Prospects with goals ), Also balance simple samples and difficult samples , The problem often encountered in the training process is that a large number of simple background samples occupy the main part of the loss function . therefore , It is also necessary to further improve the above cross information entropy loss with balance coefficient . So there was Focal Loss, It is defined as follows :
( 1 − p t ) γ (1-p_t)^\gamma (1−pt)γ Balance difficult and easy samples

Compared with the above, the balance coefficient is added α t \alpha_t αt Compared with the loss function ,Focal Loss There are two differences :
- Fixed equilibrium coefficient α t \alpha_t αt Replaced by a variable balance coefficient ( 1 − p t ) (1-p_t) (1−pt)
- There is another regulator γ \gamma γ, And γ ≥ 0 \gamma≥0 γ≥0
analysis :
- For samples with accurate classification ( That is to say Easy to separate samples , Positive sample p p p Tend to be 1, Negative sample p p p Tend to be 0), p t p_t pt Close to the 1, 1 − p t 1-p_t 1−pt Close to the 0, It shows that the contribution to the loss is small , That is, it reduces the loss proportion of easily distinguishable samples , This is contrary to the original definition of cross entropy loss function ;
- For samples with inaccurate classification ( That is to say Hard sample , Positive sample p p p Tend to be 0, Negative sample p p p Tend to be 1), p t p_t pt Close to the 0, 1 − p t 1-p_t 1−pt Close to the 1, It won't be right loss Too much impact , This is the same as the original definition of cross entropy loss function ;
- In the course of contacts , In a disguised way, the weight of samples with inaccurate classification in the loss function is improved ( Reduce classification accuracy , Although the inaccurate classification does not affect , In fact, it has been improved relatively )
- p t p_t pt It also reflects the difficulty of classification , p t p_t pt The bigger it is , It shows that the higher the confidence of classification , It means that the easier the sample is to be divided ; p t p_t pt The smaller it is , The lower the confidence of classification , It means that the more difficult it is to distinguish the samples . therefore focal loss amount to The weight of hard to distinguish samples in the loss function is added , Make the loss function tend to hard to divide samples , It helps to improve the accuracy of difficult samples .
- γ \gamma γ be equal to 0 When , Just like the normal cross entropy loss function , γ \gamma γ The smaller it is , The more important the loss of hard to distinguish samples , The less important the easy sample is . The differences are given below γ \gamma γ Of Focal Loss The loss function curve :

α + γ \alpha + \gamma α+γ combination

Obviously, both positive and negative samples are balanced , And balance the difficult and easy samples
Position loss
Location loss has L1 Loss,L2 Loss,Smooth L1 Loss( Explain the multi-level target detection architecture in detail Cascade RCNN),IoU Loss,GIOU Loss,DIoU Loss,CIoU Loss( Detailed explanation IoU、GIoU、DIoU、CIoU、EIoU and DIoU-NMS), These loss functions I mentioned in previous articles , Click to arrive at , I'll simply give the formula here .
L1 Loss

L2 Loss

Smooth L1 Loss

IoU Loss
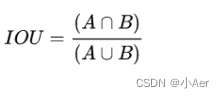

GIOU Loss


DIoU Loss

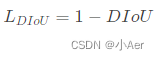
CIoU Loss


Inference
[0] https://blog.csdn.net/sinat_34474705/article/details/105141134
[1] https://zhuanlan.zhihu.com/p/266023273
[2] Hard samples and positive and negative samples
[3] https://blog.csdn.net/BIgHAo1/article/details/121783011
边栏推荐
猜你喜欢

mySQL元数据库&账户管理&引擎

Explain fcos: full revolutionary one stage object detection in detail

scala Breaks.break()、Breaks.breakable()、控制抽象

使用Dos命令生成目录文件树
Use DOS command to generate directory file tree

精确率和召回率 与 置信度之间的关系

Shengteng AI innovation competition | Shengsi track live training, the guide for obtaining up to 10million bonuses is coming

Mindspire open source anniversary carnival, quantum machine learning and deep molecular simulation and other huge new features are coming!

okcc呼叫中心语音短信与语音通知的区别

Fruit loops studio music host software Daw fruit software 20.9 Chinese version
随机推荐
【Pytorch】Tensorboard用法:标量曲线图、直方图、模型结构图
Daily question 1: numbers that appear more than half of the time in the array (Sword finger offer39)
leetcode 剑指 Offer 11. 旋转数组的最小数字
加锁熟悉synchronized和Lock,那么它们有什么区别
机器学习笔记: ELMO BERT
Ppt concise
BOM browser object model (Part 2) - offset, client, scroll three families, plug-ins and local storage features (case: imitation of JD magnifying glass, modal box drag)
The difference between layer 4 and layer 7 load balancing (turn)
【培训课程专用】TEE组件介绍
分享一个好玩的JS小游戏
[special for training course] Introduction to storage API
MySQL metabase & Account Management & Engine
正则表达式教程笔记
Mysql -分区列(横向分区 纵向分区)
Custom MVC add query
Share a fun JS game
See through the "flywheel effect" of household brands from the perspective of three winged birds
Records from July 18, 2022 to July 25, 2022
ResNet知识点补充
[special for training courses] CPU_ Initialization of context to switch