当前位置:网站首页>Google asked Indian taggers to tag reddit comment data sets, with an error rate of up to 30%?
Google asked Indian taggers to tag reddit comment data sets, with an error rate of up to 30%?
2022-07-20 22:05:00 【Heart of machine】
Almost Human reports
edit : Egg sauce
One thing is for sure , The manual annotator doesn't understand at all Reddit The stem of netizens .
last year , Google released GoEmotions Data sets , The dataset contains 58K Manually marked Reddit Comment on , Which involves 27 Emotions .
But a man named Edwin Chen Machine learning engineers are using this data set , I found some funny mistakes by chance .
They were trying to be GoEmotions Training models on datasets , Notice that there seem to be some deep-seated quality problems . So they Randomly selected 1000 comments , In which the 308 A serious error was found in .
Here are some representative examples :
- aggressively tells friend I love them—— Marked as 「 anger 」
- Yay, cold McDonald's. My favorite.—— Marked as 「 love 」
- Hard to be sad these days when I got this guy with me—— Marked as 「 sad 」
- Nobody has the money to. What a joke—— Marked as 「 Pleasure 」
- ……
Only from the extracted comments , They counted 25 An emotion that is wrongly marked .
In the field of artificial intelligence , Data annotation is a very basic , But also very critical work . Good data is crucial for training models , When the data is faced with such outrageous errors , How to train the model and evaluate its performance ?
Edwin Chen Last question :「 Can we really believe that Google can create a fair real world AI ?」
therefore , What causes these problems ?
Some people say :「 Is it possible , They didn't hire a manual annotator , Or the manual annotator did not master fluent English ?」
according to the understanding of ,GoEmotions The annotation of data sets is still manual , But these annotators are 「 Native English speaking Indians 」.
At the end of the paper 3.3 In the festival , There's a saying :「 We assigned three evaluators to each sample . For those samples that the evaluators did not agree , We assigned two additional evaluators . All evaluators are native English speaking Indians .」
Because according to 「Cowen et al. (2019b) The conclusion of this study , The emotional judgment dimensions of English users in India and the United States are largely the same .
The fact is that , Although I have mastered fluent English , Many of the annotators may not understand the culture of the marked text 、 Social background . But this is one of the key points , Especially for NLP Data sets , The annotator must have full cultural awareness .
in other words , Given that many taggers may lack the necessary background knowledge , Even most of the data annotation is not controversial ( Pictured above ), It does not mean that the annotation result is completely correct .
Another important reason for this problem is , There is no additional metadata in the data set ( Such as author or sub section name ). This is also mentioned in the original paper :
Language is not in a vacuum , Information such as the section where it is located is very important . Google ignores this when building data sets .
This is not an isolated event : The author also mentioned that , If even Google, a company with a lot of resources, is difficult to create accurate data sets , Then the quality of other data sets we have seen is even more unimaginable .
The good news is , Scholars have paid attention to this problem . Last month, , Wu Enda initiated 「 Data centric AI」 Initiative , He said , Focusing on improving the data quality of artificial intelligence system will help to release its full power .
If you want to deploy in reality work Machine learning model based on , It's time to focus on high-quality data sets rather than larger models .
Reference link :
https://arxiv.org/pdf/2005.00547.pdf
https://www.surgehq.ai/blog/30-percent-of-googles-reddit-emotions-dataset-is-mislabeled
THE END
Please contact the official account for authorization.
To contribute or seek to report :[email protected]
边栏推荐
- Redis distributed lock implemented by annotation
- Analysis of the advantages of eolink and JMeter interface testing
- [record of question brushing] 15 Sum of three numbers
- 开启创客教育课程建设的实体空间
- English grammar_ Possessive pronoun
- Codeforces Round #807 (Div. 2) A-D
- 2022年湖南工学院ACM集训第四次周测题解
- Do you know MySQL mvcc
- 适应大众化教育的创客理念设计
- New research on maker Education under Information Technology
猜你喜欢
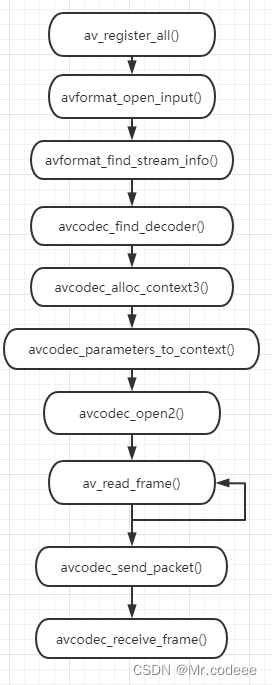
FFmpeg 视频解码

Good news | digital data won the "2022 love analysis · China's low code best practice case"
Ffmpeg video decoding

The LAAS protocol of defi 2.0 is the key to revitalizing the development of defi track
渗透测试靶机实战-SQL注入getshell

How does redis realize inventory deduction and prevent oversold?

Analog implementation library function --strcmp (character binary comparison)

指针数组跟数组指针的简单范例

Record the title of the 13th Landbridge cup embedded provincial competition
![Musk said that he had uploaded his brain to the cloud [the system may have been open source]](/img/3d/1c5941f3d19bc04454b01b972ceabd.png)
Musk said that he had uploaded his brain to the cloud [the system may have been open source]
随机推荐
DIY can decorate the mall system, you can also have!
首个X光下的小样本检测基准和弱特征增强网络,北航、讯飞新研究入选ACM MM 2022
Dest0g3 520 orientation -web-fun_ upload
ES6-11 学习笔记
适应大众化教育的创客理念设计
2022河南萌新联赛第(二)场:河南理工大学 A - 妙手
Has baozi ever played in the multi merchant system?
Notez les titres des 13es championnats provinciaux intégrés de la coupe Blue Bridge
Usage of reduce
2022.07.19 Logu p6588 『 jroi-1 』 vector
记一次爬虫逆向攻防的详细过程
Dest0g3 520 orientation -web easyphp
Mysql8.0 new feature - persistence of self increasing variables
7 月最新编程排行榜:万年不变的前三,啥时候能是头?
详细解读:反射的用法
森马做LP的背后,“温州系”正跑步进入创投圈
2022 Henan Mengxin League game (2): Henan University of technology B - Gem
nacos注册中心之服务地址的查询
Analog implementation library function --strcmp (character binary comparison)
华硕Tinker Board 2S 与树莓派4B的区别在哪里