当前位置:网站首页>视频46 13.9. 语义分割和数据集 13.10转置卷积
视频46 13.9. 语义分割和数据集 13.10转置卷积
2022-07-21 21:00:00 【俺想发SCI】



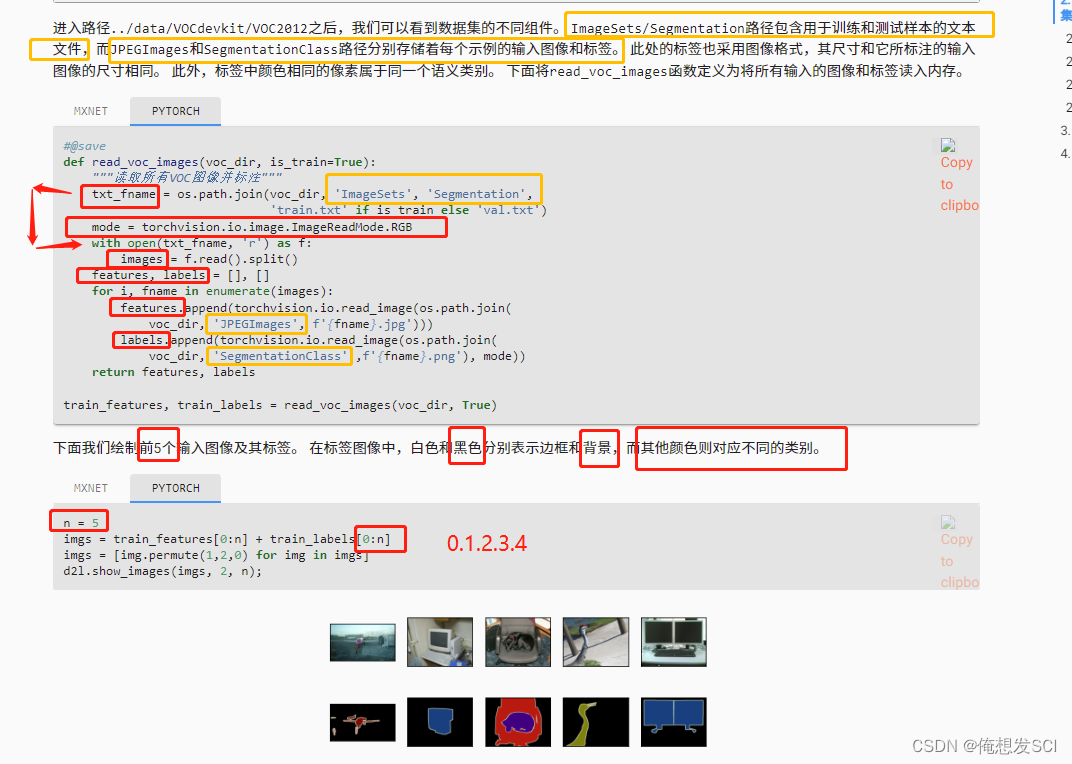
#@save def read_voc_images(voc_dir, is_train=True): """读取所有VOC图像并标注""" txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation', 'train.txt' if is_train else 'val.txt')哪些是做训练 哪些做验证数据集 mode = torchvision.io.image.ImageReadMode.RGB 彩色图片 rgb格式 with open(txt_fname, 'r') as f: images = f.read().split() features, labels = [], [] for i, fname in enumerate(images): features.append(torchvision.io.read_image(os.path.join( 读图片 voc_dir, 'JPEGImages', f'{fname}.jpg'))) 根文件下 有'JPEGImages' 读 labels.append(torchvision.io.read_image(os.path.join( voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode)) 语义分割的label需要对每个像素有label 在SegmentationClass文件夹下 存的是没有压缩的png return features, labels train_features, train_labels = read_voc_images(voc_dir, True)n = 5 imgs = train_features[0:n] + train_labels[0:n] imgs = [img.permute(1,2,0) for img in imgs] permute 画的时候 吧channel放最后 d2l.show_images(imgs, 2, n);

#@save VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]] #@save VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']rgb颜色对应飞机还是大鹅啊
#@save def voc_colormap2label(): """构建从RGB到VOC类别索引的映射""" colormap2label = torch.zeros(256 ** 3, dtype=torch.long) for i, colormap in enumerate(VOC_COLORMAP): colormap2label[ (colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i #RGB换算整数 return colormap2label #@save def voc_label_indices(colormap, colormap2label): """将VOC标签中的RGB值映射到它们的类别索引""" 图片RGB 标号对应的数值 colormap = colormap.permute(1, 2, 0).numpy().astype('int32') 移动channel idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256 rgb换算成下标 + colormap[:, :, 2]) return colormap2label[idx] 拿到每个像素对应的标号的编号


y = voc_label_indices(train_labels[0], voc_colormap2label()) 第一个飞机图片 查找标号给y y[105:115, 130:140], VOC_CLASSES[1]吧105-115,130-140小区域画出来
标号读出来了y是个图片有三个channel 现在变成了每个像素对应的值
VOC_CLASSES = ['background', 'aeroplane',第二个是飞机
(tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 1, 1, 1], [0, 0, 0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]), 'aeroplane')
增广用于语义分割:


#@save
def voc_rand_crop(feature, label, height, width):
"""随机裁剪特征和标签图像"""
rect = torchvision.transforms.RandomCrop.get_params(
feature, (height, width))
RandomCrop get_param 返回裁剪出的bodingbox
feature = torchvision.transforms.functional.crop(feature, *rect)
label = torchvision.transforms.functional.crop(label, *rect)
保证一个图片裁剪出一个框 对于标号也裁剪出来那个框 像素和像素一一对应
return feature, label
imgs = []
for _ in range(n):
imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300)
imgs = [img.permute(1, 2, 0) for img in imgs]
d2l.show_images(imgs[::2] + imgs[1::2], 2, n); 
#@save
class VOCSegDataset(torch.utils.data.Dataset):
"""一个用于加载VOC数据集的自定义数据集"""
def __init__(self, is_train, crop_size, voc_dir):
#是不是训练集 crop多大 文件放哪
self.transform = torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
#rgb三个channel 均值方差
self.crop_size = crop_size
features, labels = read_voc_images(voc_dir, is_train=is_train)
self.features = [self.normalize_image(feature)
for feature in self.filter(features)]
#去掉比我们想裁剪的图片还小的之后 normalize_image
self.labels = self.filter(labels)
#标号也去掉
self.colormap2label = voc_colormap2label()
#colormap-----label
print('read ' + str(len(self.features)) + ' examples')
def normalize_image(self, img):
return self.transform(img.float() / 255)
def filter(self, imgs):
return [img for img in imgs if (
img.shape[1] >= self.crop_size[0] and
img.shape[2] >= self.crop_size[1])]
def __getitem__(self, idx):
feature, label = voc_rand_crop(self.features[idx], self.labels[idx],
*self.crop_size)
return (feature, voc_label_indices(label, self.colormap2label))
def __len__(self):
return len(self.features)

batch_size = 64 train_iter = torch.utils.data.DataLoader(voc_train, batch_size, shuffle=True, drop_last=True, num_workers=d2l.get_dataloader_workers()) for X, Y in train_iter: print(X.shape) print(Y.shape) break
torch.Size([64, 3, 320, 480]) torch.Size([64, 320, 480])

#@save
def load_data_voc(batch_size, crop_size):
"""加载VOC语义分割数据集"""
voc_dir = d2l.download_extract('voc2012', os.path.join(
'VOCdevkit', 'VOC2012'))
num_workers = d2l.get_dataloader_workers()
train_iter = torch.utils.data.DataLoader(
VOCSegDataset(True, crop_size, voc_dir), batch_size,
shuffle=True, drop_last=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
VOCSegDataset(False, crop_size, voc_dir), batch_size,
drop_last=True, num_workers=num_workers)
return train_iter, test_iter



主要关心的还是语义分割
3. Q&A
标注工具?
labelme

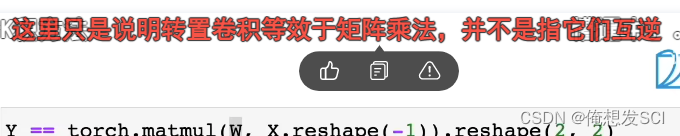
卷积就是一个一个小框对应和卷积核计算 然后变成一个数字
但是这个没有是吧重复位置进行增加啦 步幅为1 就多一个行一列
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i: i + h, j: j + w] += X[i, j] * K
return Y
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2) tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False) tconv.weight.data = K tconv(X)


X = torch.rand(size=(1, 10, 16, 16)) #输入10 conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3) 10-》20 tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3) 20-》10 tconv(conv(X)).shape == X.shape#10=10



加了填充 输出变小了
![]()

X = torch.arange(9.0).reshape(3, 3) #3*3 0-9的值 K = torch.tensor([[1.0, 2.0], [3.0, 4.0]]) Y = d2l.corr2d(X, K) Ytensor([[27., 37.], [57., 67.]])def kernel2matrix(K): k, W = torch.zeros(5), torch.zeros((4, 9)) #输入3*3拉长=9 k[:2], k[3:5] = K[0, :], K[1, :] W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, k return W W = kernel2matrix(K) Wtensor([[1., 2., 0., 3., 4., 0., 0., 0., 0.], [0., 1., 2., 0., 3., 4., 0., 0., 0.], [0., 0., 0., 1., 2., 0., 3., 4., 0.], [0., 0., 0., 0., 1., 2., 0., 3., 4.]])

 https://www.bilibili.com/video/BV17o4y1X7Jn?p=2&vd_source=eba877d881f216d635d2dfec9dc10379
https://www.bilibili.com/video/BV17o4y1X7Jn?p=2&vd_source=eba877d881f216d635d2dfec9dc10379 https://www.bilibili.com/video/BV1CM4y1K7r7?spm_id_from=333.999.0.0&vd_source=eba877d881f216d635d2dfec9dc10379
https://www.bilibili.com/video/BV1CM4y1K7r7?spm_id_from=333.999.0.0&vd_source=eba877d881f216d635d2dfec9dc10379








边栏推荐
- TZC 1283: simple sort - quick sort
- 基于加权朴素贝叶斯的水质数据分类研究
- In depth analysis of pycocotools' installation and operation error & installation of mmcv full and mmpycocotools
- 重载与重写
- PR
- Apple lost 340million Yuan due to bad keyboard. SpaceX took the order. Webb's successor, meta, sued meta. Today, more new things are here
- 关系运算符3(阁瑞钛伦特软件-九耶实训)
- 基于SSM+MySQL+Bootstrap+JQuery的在线购物商城电子商务系统
- Cadence学习之路:导入网表出错之引脚不对应
- OpenOffice startup and auto startup settings
猜你喜欢
重载与重写
Light up through UDP

Frame coding of h264 -- dialysis (I frame +p frame +b frame coding) principle and process

3 亿

【开发教程5】开源蓝牙心率防水运动手环-电池电量检测

Go语言 并发与通道

Leetcode skimming -- bit by bit record 019

Delete adjacent files with different names in the folder & adapt to the situation that the label name corresponds to the image name during neural network training

TZC 1283: simple sort - quick sort

How do you choose sentinel vs. hystrix?
随机推荐
加密市场飙升至1万亿美元以上 不过是假象?加密熊市远未见底
Jmeter-测试脚本学习(登录脚本)
baseline
Ctfhub (RCE wisdom tree)
Delete adjacent files with different names in the folder & adapt to the situation that the label name corresponds to the image name during neural network training
移动端Web App 的屏幕适配方法(总结)
Go language concurrency and channel
HCIP第五天
News blog publishing system based on jsp+servlet+mysql
【學習筆記】帶你從0開始學習 01Trie
多线程与高并发day10
Leetcode skimming -- bit by bit record 019
es6 的 class 与 es5 的语法对比
001_ Getting started with kubernetes
GaitSet源代码解读(三)
Call the "Transformers pipeline API created by the face hugging team" & quickly train and fine tune your own model through pre training model
EN 1504-4: structural bonding of concrete structure products - CE certification
师傅教你~LNMP源码搭建
Frame coding of h264 -- dialysis (I frame +p frame +b frame coding) principle and process
第01篇:分布式注册中心