当前位置:网站首页>[toggle 30 days of ML] Diabetes genetic risk detection challenge (1)
[toggle 30 days of ML] Diabetes genetic risk detection challenge (1)
2022-07-21 16:04:00 【Little spice】
Catalog
Mission
- Mission 1: Sign up for the competition
- step 1: Sign up for the competition 2022 iFLYTEK A.I. Developer competition - IFLYTEK open platform
- step 2: Download game data ( Click the question data on the competition page )
- step 3: Decompress the game data , And use pandas To read ;
- step 4: View training set and test set field types , And write the data reading code to the blog ;
- Mission 2: Game data analysis
- step 1: Missing value of statistical field , Calculate the missing percentage ;
- Through missing value statistics , Whether the distribution of missing values in the training set and the test set is consistent ?
- Through missing value statistics , Is there a column with a high missing proportion ?
- step 2: Analyze the type of field ;
- How many numeric types are there 、 Category type ?
- You judge the field type ?
- Write your judgment in the blog ;
- step 3: Calculate field correlation ;
- adopt
.corr()Calculate the correlation between fields ; - Which fields are most relevant to labels ?
- Try using other visualization methods to add fields And Visualize the distribution differences of labels ;
- adopt
- step 1: Missing value of statistical field , Calculate the missing percentage ;
Mission 3: Logistic regression attempts
- step 1: Import sklearn Logical regression in ;
- step 2: Use training sets and logistic regression for training , And make predictions on the test set ;
- step 3: Will step 2 The predicted result file is submitted to the competition , Screenshot score ;
- step 4: Training set 20% Divided into validation sets , Train in the training section , Make predictions in the test section , Adjust the hyperparameter of logistic regression ;
- step 5: If the accuracy is improved , Then repeat the steps 2 And steps 3; If you don't improve , Try the tree model , Repeat step 2、3;
Mission 6: High order tree model
- step 1: install LightGBM, And learn how to use the basics ;
- step 2: Training set 20% Divided into validation sets , Use LightGBM Finish training , Whether the accuracy has been improved ?
- step 3: Will step 2 The predicted result file is submitted to the competition , Screenshot score ;
- step 4: Try adjusting the search LightGBM Parameters of ;
- step 5: Will step 4 The model after parameter adjustment is trained again , Submit the result file of the latest prediction to the competition , Screenshot score ;
Just Do It!
1. Guide pack
import pandas as pd
import seaborn as sns
from lightgbm import LGBMClassifier
from sklearn.pipeline import make_pipeline
from sklearn.metrics import f1_score
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score2. Read data and analyze
View the shape and type of training set and test set
train_df = pd.read_csv('../data/ Open data of diabetes genetic risk prediction challenge / Game training set .csv', encoding='gbk')
test_df = pd.read_csv('../data/ Open data of diabetes genetic risk prediction challenge / Competition test set .csv', encoding='gbk')
print(train_df.shape, test_df.shape)
print(train_df.dtypes, test_df.dtypes) 
Check the missing values of training set and test set
# Missing value calculation
print(train_df.isnull().mean(0))
print(test_df.isnull().mean(0))
# Correlation calculation
train_df.corr()
You can see , Only diastolic blood pressure in the training set and the test set has a blank value .

Draw the heat map again
# Draw heat map
plot = sns.heatmap(train_df.corr()) 
According to the correlation and heat map, we can see , Triceps brachii skinfold thickness and Body mass index These two characteristics are right label Our contribution is relatively large .
3. Data preprocessing
Use df.map function ( Be similar to df.apply function ) Will include Non numerical The column of corresponds to Non numeric type Convert to the corresponding numeric type , Only in this way can we throw it into the model for training ( The model can only understand numerical data ).
meanwhile , To populate a column with null values .
dict_ Family history of diabetes = {
' No record ': 0,
' One uncle or aunt has diabetes ': 1,
' One uncle or aunt has diabetes ': 1,
' One parent has diabetes ': 2
}
train_df[' Family history of diabetes '] = train_df[' Family history of diabetes '].map(dict_ Family history of diabetes )
test_df[' Family history of diabetes '] = test_df[' Family history of diabetes '].map(dict_ Family history of diabetes )
train_df[' diastolic pressure '].fillna(train_df[' diastolic pressure '].mean().round(2), inplace=True)
test_df[' diastolic pressure '].fillna(train_df[' diastolic pressure '].mean().round(2), inplace=True)
train_df Before conversion 
After the transformation

The training set is divided into training set and verification set , Convenient for local testing , Otherwise, submit the opportunity three times a day , You can't use the platform every time you adjust parameters .
# The training set is divided into training set and verification set , It is convenient to test the current model , And make appropriate adjustments
train_df2,val_df,y_train,y_val = train_test_split(train_df.drop(' Signs of diabetes ',axis=1),train_df[' Signs of diabetes '],test_size=0.3)
train_df2The number of divided training sets and verification sets is
print('train2 length:',len(train_df2),' ',len(y_train))
print('val length:',len(val_df),' ',len(y_val)) 
4. Model selection
# Choose a model
#
# Use logistic regression for training
# model = LogisticRegression()
# model.fit(train_df.drop(' Number ',axis=1),y_train)
# Build the model
# model = make_pipeline(
# MinMaxScaler(),
# DecisionTreeClassifier()
# )
# model.fit(train_df.drop(' Number ',axis=1),y_train)
model = LGBMClassifier(
objective='binary',
max_depth=3,
n_estimators=4000,
n_jobs=-1,
verbose=-1,
verbosity=-1,
learning_rate=0.1,
)
model.fit(train_df2.drop(' Number ',axis=1),y_train,eval_set=[(val_df.drop(' Number ',axis=1),y_val)])Unified name is model 了 , In this way, the following code directly calls model That's all right. , With different models, you only need to change model Just the back one . At present, I have written logical regression 、 Decision tree 、LGBM Three methods , New models may be updated later . At present, the leaders on the list have reached 100% The accuracy is , It's too much . I don't know what model they use .
5. forecast
# Prediction training set
train_df2['label'] = model.predict(train_df2.drop(' Number ',axis=1))
# Prediction training set
train_df2['label'] = model.predict(train_df2.drop(' Number ',axis=1))6. Evaluation indicators
Platform use F1 assessment , I added a accuracy,F1 Adopted macro How to calculate .
# Evaluate model indicators
def eval(y_true,y_pred):
lr_acc = accuracy_score(y_true,y_pred)
lr_f1 = f1_score(y_true,y_pred,average='macro')
print(f"lr_acc:{lr_acc},lr_f1:{lr_f1}")print(' Training set indicators :')
eval(y_train,train_df2['label'])
print(' Validation set indicator :')
eval(y_val,val_df['label'])7. Get submissions
# Prediction test set
test_df['label'] = model.predict(test_df.drop(' Number ',axis=1))
test_dfIn order to prevent the submitted file from being overwritten by the new output , Specially added a time mark to the output file .
test_df.rename({' Number ':'uuid'},axis=1)[['uuid','label']].to_csv('submit'+str(datetime.now().strftime('%m_%d_%H_%M_%S'))+'.csv',index=None)
OK,Fine!
边栏推荐
- Deep understanding of perfect hash
- At present, pytest, the hottest testing framework, is a magical explanation
- 2022 Shandong vision prevention and control conference, China eye care products exhibition, Jinan myopia correction equipment exhibition
- Cluster deployment of Apache Druid 0.22 real-time analysis database on CentOS 7
- Training of head and neck segmentation networks with shape prior on small datasets
- vtk9.0.1+Qt5.13手动创建四窗口(MPR+3D)
- I2C adapter driver
- Shape and boundary-aware multi-branch model for semi-supervised medical image segmentation
- Amazon cloud technology training and Certification Course in August is wonderful and can't be missed!
- DTOS帝拓思的3D引擎將取代遊戲引擎巨獸,實現國產化替代
猜你喜欢
![[JS] event communication](/img/3e/078d7e59210b2c6fcfd9bb6849ce69.png)
[JS] event communication

Blueprism tool menu bar user rights function description -rpa Chapter 2

Using go TCP to realize simple online group chat function

專注跨境支付一體化服務 iPayLinks榮獲《財資》(The Asset)3A亞洲獎!
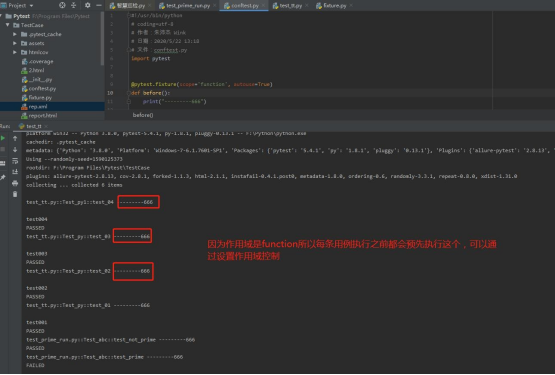
At present, pytest, the hottest testing framework, is a magical explanation

每日一题-LeetCode1260-二维网格迁移-数组-映射
【愚公系列】2022年7月 Go教学课程 014-运算符之算术运算符

This domestic API artifact tool is too strong Let me give up postman

Because mongodb didn't get started, I lost an internship

信号完整性(SI)电源完整性(PI)学习笔记(三十)电源分配网路(二)
随机推荐
EasyGBS平台设置小技巧:如何隐藏平台web页面不被访问?
信号完整性(SI)电源完整性(PI)学习笔记(三十)电源分配网路(二)
这款国产API神器工具也太强了吧...让我放弃了postman
模仿vtk的Widget控件,制作画矩形的控件
Hey, I haven't been a project manager
Wechat vaccine reservation applet graduation design of applet completion work (3) background function
【超好懂的比赛题解】2021 年四川省大学生程序设计竞赛
Why can't Alibaba cloud international account login?
Algorithm summary] 20 questions to complete bat interview - binary tree
-Solid modeling-
Le moteur 3D de dtos titos remplacera le moteur de jeu Giant Beast et réalisera la substitution de localisation
Wechat vaccine appointment applet graduation design of applet completion work (2) applet function
Esp8266 nodemcu - connect WiFi using WiFi manager Library
Database constraint & MySQL advanced query
I2C client driver
Ipaylinks, a cross-border payment integration service, won the 3A Asia Award of the asset!
ESP32-CAM——内网穿透教程
【数字图像处理/双边滤波实验】高分课程实验报告分享
Draw circles and rectangles with VTK controls
伦敦银实时行情能够给人们带来哪方面的信息