当前位置:网站首页>Pytorch dynamically adjusts the learning rate, and the learning rate automatically decreases according to loss
Pytorch dynamically adjusts the learning rate, and the learning rate automatically decreases according to loss
2022-07-22 20:31:00 【Dull as dull】
0 Why introduce learning rate decay ?
We all know that almost all neural networks adopt gradient descent method to optimize the model , The standard weight update formula :
W + = α ∗ gradient W+=\alpha * \text { gradient } W+=α∗ gradient
- Learning rate α \alpha α Controls the step size of gradient update (step), α \alpha α The bigger it is , It means the faster the decline , The faster you get to the best , If 0 0 0, Then the network will stop updating
- Excessive learning rate , In the early stage of algorithm optimization, it will accelerate learning , It makes the model easier to approach the local or global optimal solution . But there will be big fluctuations in the later stage , Even the value of the loss function hovers around the minimum value , There's a lot of volatility , It is always difficult to achieve the best .
Therefore, the concept of learning rate attenuation is introduced , Straight white point , At the beginning of model training , Will use a large learning rate for model optimization , As the number of iterations increases , The learning rate will gradually decrease , Ensure that the model will not fluctuate too much in the later stage of training , So as to be closer to the optimal solution .
All the experimental codes in this article can be downloaded and tested at the following link
lr_scheduler_test.py- Deep learning document resources -CSDN download
1 Look at the learning rate
print("Lr:{}".format(optimizer.state_dict()['param_groups'][0]['lr']))
Then I will test the learning rate with code similar to the following
def train():
traindataset = TrainDataset()
traindataloader = DataLoader(dataset = traindataset,batch_size=100,shuffle=False)
net = Net().cuda()
myloss = nn.MSELoss().cuda()
optimizer = optim.SGD(net.parameters(), lr=0.001 )
for epoch in range(100):
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][0]['lr']))
for data,label in traindataloader :
data = data.cuda()
label = label.cuda()
output = testnet(data)
loss = myloss(output,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
2 The most commonly used global learning rate setting
You need to specify what you want according to the type of optimizer you choose lr As part of the optional parameters, it is passed into the initialization of the new optimizer class

optimizer = optim.SGD(net.parameters(), lr=0.001 )
3 Set different learning rates for different layers
When we are using a pre trained model , The classification layer needs to be modified and initialized separately , The parameters of other layers are initialized with pre trained model parameters , At this time, we hope that during the training process , Layers other than the classification layer are only fine tuned , There is no need to change parameters too much , Therefore, it is necessary to set a small learning rate . The corrected classification layer needs to converge with a larger step , The learning rate is often set higher
Take a simple network as an example
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net1 = nn.Linear(2,10)
self.net2 = nn.Linear(10,1)
def forward(self, x):
x = self.net1(x)
x = self.net2(x)
return x
net = Net()
optimizer = optim.SGD([
{
"params":model.net1.parameters()},
{
"params":model.net2.parameters(),"lr":1e-5},],
lr=1e-2, # Default parameters
)
for epoch in range(100):
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][0]['lr']))
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][1]['lr']))
optimizer.step()

With resnet101 For example , Set the learning rate hierarchically .
model = torchvision.models.resnet101(pretrained=True)
large_lr_layers = list(map(id,model.fc.parameters()))
small_lr_layers = filter(lambda p:id(p) not in large_lr_layers,model.parameters())
optimizer = torch.optim.SGD([
{
"params":large_lr_layers},
{
"params":small_lr_layers,"lr":1e-4}
],lr = 1e-2,momenum=0.9)
notes :large_lr_layers The learning rate is 1e-2,small_lr_layers The learning rate is 1e-4, The two parameters share one momenum
4 Manually set the learning rate of automatic attenuation
def adjust_learning_rate(optimizer, epoch, start_lr):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = start_lr * (0.1 ** (epoch // 3))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
notes : When calling this function, you need to input the initialized optimizer And corresponding epoch, also start_lr The learning rate as initialization also needs to be given .
optimizer = torch.optim.SGD(net.parameters(),lr = start_lr)
for epoch in range(100):
adjust_learning_rate(optimizer,epoch,start_lr)
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][0]['lr']))
for data,label in traindataloader :
data = data.cuda()
label = label.cuda()
output = net(data)
loss = myloss(output,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
5 Manually specify the learning rate according to the customized list
def adjust_learning_rate_list(optimizer, epoch):
lr_set_list = [[1,1e-1],[2,1e-2],[3,1e-3],[4,1e-4],[5,1e-5]]# Execute this learning rate epoch Count
lr_list = []
for i in lr_set_list:
for j in range(i[0]):
lr_list.append(i[1])
for param_group in optimizer.param_groups:
if epoch < len(lr_list)-1:
param_group['lr'] = lr_list[epoch]
else:
param_group['lr'] = lr_list[-1]

6 Use pytorch The learning rate provided
stay torch.optim.lr_scheduler Inside , Based on the present epoch The numerical , Several corresponding dynamic learning rate adjustment methods are encapsulated , The official manual portal of this part ——optim.lr_scheduler Official documents . It should be noted that the adjustment of learning rate needs to be applied after the optimizer parameter is updated , in other words :
optimizer = torch.optim.XXXXXXX()# Specifically optimizer The initialization
scheduler = torch.optim.lr_scheduler.XXXXXXXXXX()# Initialization of specific learning rate change strategy
for i in range(epoch):
for data,label in dataloader:
out = net(data)
output_loss = loss(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
A brief code example of its specific learning rate strategy application is as follows :
6.1 lr_scheduler.LambdaLR
Update strategy :
Adjust the learning rate of each parameter group to Initialize learning rate lr Times the given function of (lr_lambda), stay fine-tune Very useful in , We can not only set different learning rates for different layers , You can also set different learning rate adjustment strategies for them .
Initialization method :
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
Some of the most commonly used functions :
# Open world shuffleNet The learning rate change strategy used in the series
lr_lambda = lambda step : (1.0-step/args.total_iters) if step <= args.total_iters else 0
# CCNet The way to change the learning rate in the official source code . This learning rate decay strategy is the most commonly used , It is called polynomial decay method .
def lr_poly(base_lr, iter, max_iter, power):
return base_lr*((1-float(iter)/max_iter)**(power))
def adjust_learning_rate(optimizer, learning_rate, i_iter, max_iter, power):
"""Sets the learning rate to the initial LR divided by 5 at 60th, 120th and 160th epochs"""
lr = lr_poly(learning_rate, i_iter, max_iter, power)
optimizer.param_groups[0]['lr'] = lr
return lr
Parameters
optimizer(Optimizer): It is the instance name of the optimizer that needs to be optimized defined beforelr_lambda(function or list): It can be function or function list, Given an integer parameter epoch A function that calculates multipliers , Or is it list Function of form , Calculate each... Separately parameter groups The learning rate used to update the learning rate . It's usually about epoch Function of number , Thus a multiplier factor is calculated , And adjust the initial learning rate according to the multiplier factor .last_epoch(int): The default is -1, It generally does not need to be set , by -1 The function of time is to set the artificially set learning rate as the basic value for adjusting the learning rate lr. What needs to be noted here is ,last_epoch The default is -1 Only when the learning rate is adjusted for the first time , The original value to be adjusted is the manually set initial learning rate , And when adjusting the learning rate for the second time , The adjusted base value becomes the learning rate after the first adjustment . If you train a lot epoch After that , Keep training , This value is equal to the... Of the loaded model epoch. The default is -1 Means to train from scratch , From epoch=1 Startverbose(bool):True Print one for each update stdout, The default is False
Be careful :
Will be optimizer Pass to scheduler after , stay shcduler Class __init__ The method will give optimizer.param_groups The element in the list ( Dictionaries ) Add one more key = "initial_lr" The element of represents the initial learning rate , be equal to optimizer.defaults['lr'].
give an example :
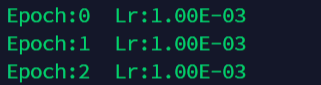
lambda1 = lambda epoch: 0.95 ** epoch # The adjustment method of the second group of parameters
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) # Select the adjustment method
6.2 torch.optim.lr_scheduler.StepLR
Update strategy :
This is a commonly used method of equal interval dynamic adjustment , Each pass step_size individual epoch, Do a learning rate decay, With gamma The value is the reduction factor .
Initialization method :
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
Parameters :
optimizer(Optimizer): It is the instance name of the optimizer that needs to be optimized defined beforestep_size(int): Is the period of learning rate decay , Each pass step_size individual epoch, Do a learning rate decaygamma(float): Multiplication factor of learning rate decay .Default:0.1last_epoch(int): The default is -1, It generally does not need to be set , by -1 The function of time is to set the artificially set learning rate as the basic value for adjusting the learning rate lr. What needs to be noted here is ,last_epoch The default is -1 Only when the learning rate is adjusted for the first time , The original value to be adjusted is the manually set initial learning rate , And when adjusting the learning rate for the second time , The adjusted base value becomes the learning rate after the first adjustment . If you train a lot epoch After that , Keep training , This value is equal to the... Of the loaded model epoch. The default is -1 Means to train from scratch , From epoch=1 Startverbose(bool): If True, Each update will print a standard output ,Default:False
Be careful :
This function produces decay effect , It may happen at the same time as the change of learning rate outside the function , When last_epoch = -1 when , take initial lr Set to Ir.
give an example :
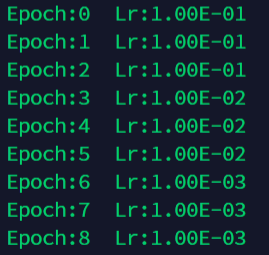
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)

6.3 lr_scheduler.MultiStepLR
Update strategy :
Once you reach a certain stage (milestones) when , You can go through gamma The coefficient reduces the learning rate of each parameter group .
May, in accordance with the milestones The learning rate given in the list , Adjust the learning rate in stages .
Initialization method :
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
Parameters :
optimizer(Optimizer): It is the instance name of the optimizer that needs to be optimized defined beforemilestones(list): It's a story about epoch Numericallist, Indicates which epoch The range begins to change , Must be in ascending ordergamma(float): Multiplication factor of learning rate decay .Default:0.1last_epoch(int): The default is -1, It generally does not need to be set , by -1 The function of time is to set the artificially set learning rate as the basic value for adjusting the learning rate lr. What needs to be noted here is ,last_epoch The default is -1 Only when the learning rate is adjusted for the first time , The original value to be adjusted is the manually set initial learning rate , And when adjusting the learning rate for the second time , The adjusted base value becomes the learning rate after the first adjustment . If you train a lot epoch After that , Keep training , This value is equal to the... Of the loaded model epoch. The default is -1 Means to train from scratch , From epoch=1 Startverbose(bool): If True, Each update will print a standard output ,Default:False
Be careful :
This function produces decay effect , It may happen at the same time as the change of learning rate outside the function , When last_epoch = -1 when , take initial lr Set to lr.
give an example :
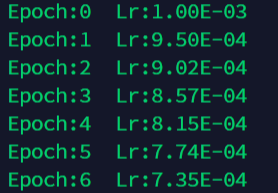
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[2,6,15], gamma=0.1)
6.4 lr_scheduler.ExponentialLR
Update strategy :
every time epoch,lr Ducheng gamma
Initialization method :
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
Parameters :
optimizer(Optimizer): It is the instance name of the optimizer that needs to be optimized defined beforegamma(float): Multiplication factor of learning rate decay .Default:0.1last_epoch(int): The default is -1, It generally does not need to be set , by -1 The function of time is to set the artificially set learning rate as the basic value for adjusting the learning rate lr. What needs to be noted here is ,last_epoch The default is -1 Only when the learning rate is adjusted for the first time , The original value to be adjusted is the manually set initial learning rate , And when adjusting the learning rate for the second time , The adjusted base value becomes the learning rate after the first adjustment . If you train a lot epoch After that , Keep training , This value is equal to the... Of the loaded model epoch. The default is -1 Means to train from scratch , From epoch=1 Startverbose(bool): If True, Each update will print a standard output ,Default:False
give an example :
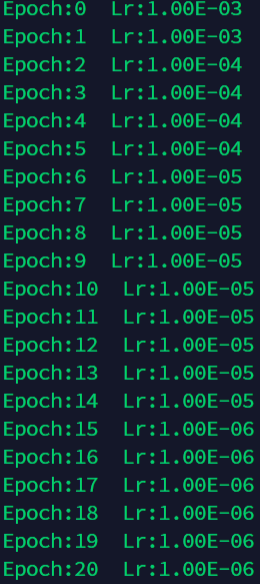
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.1)

6.5 lr_scheduler.CosineAnnealingLR
Update strategy :
Update the learning rate according to the decay period of the cosine waveform , In the first half of the cycle, the maximum value is reduced to the minimum value , The second half of the cycle rises from the minimum to the maximum
Initialization method :
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
Parameters :
optimizer(Optimizer): It is the instance name of the optimizer that needs to be optimized defined beforeT_max (int): Half the period of cosine waveform , such as T_max=10, Then the learning rate decay period is 20, The first half is the first 10 The learning rate of each cycle decreases from the maximum to the minimum , after 10 Cycles rise from minimum to maximumeta_min(float): The minimum value of learning rate attenuation ,Default:0last_epoch(int): The default is -1, It generally does not need to be set , by -1 The function of time is to set the artificially set learning rate as the basic value for adjusting the learning rate lr. What needs to be noted here is ,last_epoch The default is -1 Only when the learning rate is adjusted for the first time , The original value to be adjusted is the manually set initial learning rate , And when adjusting the learning rate for the second time , The adjusted base value becomes the learning rate after the first adjustment . If you train a lot epoch After that , Keep training , This value is equal to the... Of the loaded model epoch. The default is -1 Means to train from scratch , From epoch=1 Startverbose(bool): If True, Each update will print a standard output ,Default:False
give an example :
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max = 10)

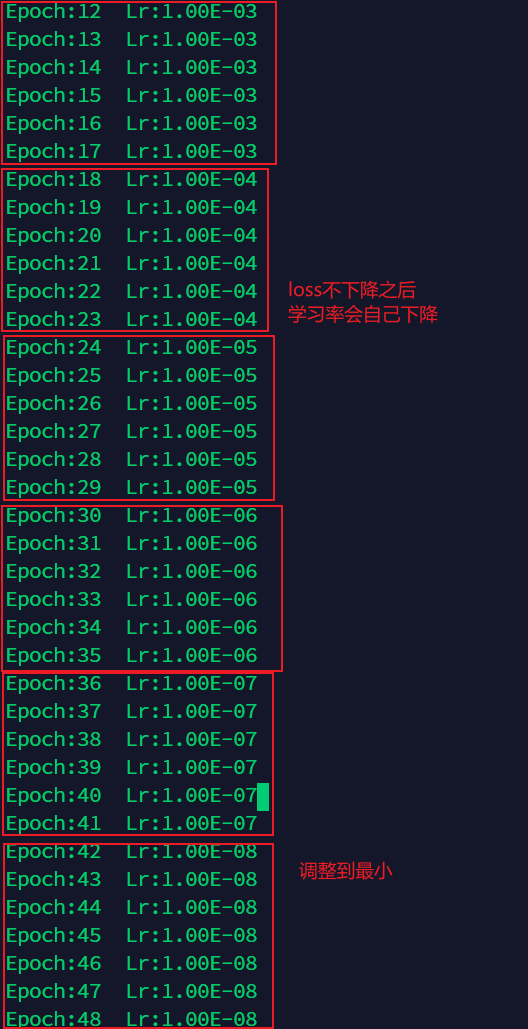
6.6 lr_scheduler.ReduceLROnPlateau
Update strategy :
Based on epoch The number of ways to adjust the learning rate is different , The method is PyTorch An adjustment method based on verification index is provided . Its principle is : When indicators stop improving , Reduce learning rate . When the learning of the model stalls , The training process usually benefits from reducing the learning rate 2~10 times . This adjustment method reads a measure , If in “ Patience, ” No improvement was found during the period , Then it will reduce the learning rate .
Initialization method :
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode= 'rel', cooldown=0, min_1r=0, eps=1e-08)
step() Method :
scheduler.step(loss)
Parameters :
optimizer(Optimizer): It is the instance name of the optimizer that needs to be optimized defined beforemode: Optional str String data , by min or max. When choosing min when , Represents when the measure stops falling , Start reducing the learning rate ; When choosing max when , Represents when the measure stops rising , Start reducing the learning rate .factor:float Type data , Multiplication factor for learning rate adjustment , The default value is 0.1.patience:int Type data , Tolerable metrics do not improve epoch number , The default is 10. Illustrate with examples , When it is set to 10 when , We can tolerate 10 individual epoch There is no improvement in , If in the first place 11 individual epoch Still not improved , Then start reducing the learning rate .verbose:bool data , If set to True, Output the information of each update , The default is False.threshold:float Type data , Measure the new optimal threshold , Focus only on major changes , The default is 0.0001.threshold_mode: Optional str String data , by rel or abs, The default is rel. stay rel In mode , If mode Parameter is max, Dynamic threshold (dynamic_threshold) by best*(1+threshold), If mode Parameter is min, Then the dynamic threshold is best+threshold, If mode Parameter is min, Then the dynamic threshold is best-threshold.cooldown:int Type data , Reduce lr Wait before returning to normal operation after epoch Count , The default is 0.min_lr:float or list Type data , The lower bound of learning rate , The default is 0.eps:float Type data , Minimum change in learning rate . If the difference between the adjusted learning rate and the adjusted learning rate is less than eps Words , Then don't make any adjustments , The default is 1e-8.
give an example :
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min',patience=5)
scheduler.step(loss)
LAST reference
pytorch Different levels of the model set different learning rates - Hua Wei Yun
torch.optim — PyTorch 1.9.0 documentation
边栏推荐
- Introduction to machine learning: Logistic regression-2
- 1072 Gas Station (30 分)
- Exclusive interview with Huang Hui, a scholar of women in AI: dream of drawing shapes and find the door to breakthrough
- vim配置
- SSM框架整合
- 1080 Graduate Admission (30 分)
- 《预训练周刊》第38期: Transformer、BERT结构优化
- RAG小结
- Kubernetes基础
- const 类型数据的总结
猜你喜欢

二分查找(递归函数)

16进制字符串与字节数组之间的转换

Websites jump inexplicably. What is website hijacking from Baidu? DNS hijacking (domain name hijacking) what is DNS hijacking

LeetCode160 & LeetCode141——double pointers to solve the linked list

Class template parsing

Plug in installation of elastic search getting started (5)

What is network hijacking? How to repair web pages that have been tampered with and hijacked (final scheme) how to repair web page hijacking?

Pytorch中 类Parameter的解析,类内成员函数.parameters()的源码分析,参数集合的获取,参数的注册赋值源码分析

AMiner论文推荐

mysql索引
随机推荐
Introduction to elastic search: search full text search (7)
CentOS installs MySQL database
【文献阅读与想法笔记13】Pre-Trained Image Processing Transformer
IDEA下载源码查看
Plug in installation of elastic search getting started (5)
pytorch 动态调整学习率,学习率自动下降,根据loss下降
通过@Autowired注入的bean,即使这个类上没有标注@Comment等这一类的注解,但是这个bean依然能够注入进来
Unix C语言 POSIX 互斥锁 线程同步
《因果学习周刊》第10期:ICLR2022中最新Causal Discovery相关论文介绍
基于canny的亚像素的Devernay Algorithm
Flask cross domain
Introduction to machine learning: support vector machine-6
本地镜像发布到阿里云
1057 Stack (30 分)
信号降噪方法
redission看门狗实现机制一看就懂
AMBert
vim配置
Spark data search
Flask Cross - Domain