当前位置:网站首页>Mathematical modeling - K-means clustering
Mathematical modeling - K-means clustering
2022-07-21 17:44:00 【chen_ :)】

solve the problem
The process of dividing a sample into multiple classes composed of similar objects ( clustering ).
After clustering , The statistical model can be used separately in each class to estimate more accurately 、 Analyze or predict ; You can also explore the correlation and main differences between different classes .
(KMeans In essence, it is a data division method based on Euclidean distance measurement )
ps. Classification is a known category , Clustering unknown .
Algorithm flow
K-means clustering algorithm :
- Specify the number of clusters to be divided K value ( Number of classes );
- Select randomly K A data object is used as the initial clustering center ( It doesn't have to be our sample point );
- Calculate the remaining data objects to this K Initial cluster centers
Distance of , Classify the data object to the center closest to it
In the cluster class of ; - Adjust the new class and recalculate the center of the new class ;
- Cycle steps three and four , See if the center converges ( unchanged ), Such as
If it converges or reaches the number of iterations, the cycle will stop ; - end
 Formula process : k-means clustering algorithm
Formula process : k-means clustering algorithm
Model characteristics
K-means Clustering advantages :
(1) Method is simple 、 Fast .
(2) For dealing with big data sets , The algorithm is relatively efficient .
When clusters are dense 、 Spherical or agglomerated , And the difference between clusters is obvious , The clustering effect is good .
K-means Clustering disadvantages :
(1) Users are required to give the number of clusters to be generated in advance K.
(2) Sensitive to initial values .
(3) Sensitive to outlier data .
ps. K‐means++ Algorithm To solve 2 and 3 These two shortcomings .
K-means++ The basic principle for the algorithm to select the initial clustering center is :
initial The interaction between clustering centers distance Try to far .( Only right K-means Algorithm “ initialization K Cluster centers ” This step is optimized )
That is to optimize the pretreatment :
Step one : Randomly select a sample as the first cluster center ;
Step two : Calculate the shortest distance between each sample and the current existing cluster center ( That is, the distance from the nearest cluster center ), The bigger this is , It means that the probability of being selected as the cluster center is high ;
Last , Use the roulette method ( Select according to the probability ) Select the next cluster center ;
Step three : Repeat step 2 , Until the election K Cluster centers . After selecting the initial point , Just keep using the standard K-means The algorithm .
Usage method
utilize Spss Software
 The default is K-means++ Algorithm
The default is K-means++ Algorithm utilize matlab Software
X2 = zscore(X); % zscore Methods standardize data
Y2 = pdist(X2); % Calculated distance ( Default Euclidean distance )
Z2 = linkage(Y2); % Define the connection between variables , Calculate the system clustering tree with the specified algorithm
T = cluster(Z2,6); % Create clusters
H = dendrogram(Z2); % Make a pedigree ( I'm tired of reading the scatter clustering diagram , Draw a pedigree here )
combination MATLAB Some functions in , Results make a pedigree
ps. MATLAB as well as sklearn The corresponding kmeans() Function can be used for direct clustering
from 5 Minutes will help you understand K-means clustering
matters needing attention
a. Number of clusters (K value )
It depends on personal experience and feeling , The usual way is to try a few more K value , See the results divided into several categories for better explanation , More in line with the analysis purpose, etc .( That is, you should know the number of classifications in advance )
ps. If you can't judge in advance, you should divide it into several categories , May adopt System ( level ) clustering algorithm .
b. Data dimension
If the dimensions of the data are different , Then it's meaningless to calculate the distance . for example : If X1 The unit is meters ,X2 The unit is ton , Using the distance formula, you will see “ Square meters ” add “ Square of tons ” Re square , The final calculation has no mathematical meaning , That's a problem .
So we should preprocess the data first ( Standardized treatment )
Can be used directly spss Realization :
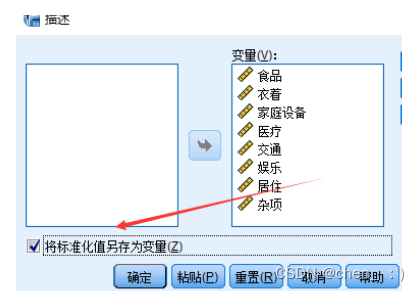
c. The difference between classification and clustering
classification : The category is known , Through training and learning the data of known categories , Find the characteristics of these different classes , Then classify the data of unknown categories . Belongs to supervised learning .
clustering : I didn't know in advance that the data will be divided into several categories , The data are aggregated into several groups by cluster analysis . Clustering does not require data training and learning . It belongs to unsupervised learning .
generally speaking , Is there supervision , It depends on whether the input data has a label , The input data has labels , Supervised learning , Otherwise, it is unsupervised learning .
d. Applicable conditions
KMeans Method can only be used if the average value of the cluster is defined , And it is not suitable for the data of some classification attributes .
Outliers will have a great impact on the calculation of the mean , Cause the center to shift , So for " noise " And outlier data should be filtered in advance .
e. about K Choice of value
 from K-Means Algorithmic K Choice of value
from K-Means Algorithmic K Choice of value
f. The form of clusters

from K-means clustering algorithm
g. Comparison with other clustering algorithms
k-means Advantages and disadvantages of clustering algorithm ?
Reference material
Qingfeng mathematical modeling
5 Minutes will help you understand K-means clustering
K-Means Algorithmic K Choice of value
k-means Advantages and disadvantages of clustering algorithm ?
machine learning ,KMeans Detailed explanation of cluster analysis
边栏推荐
猜你喜欢

How to use measurement data to drive the improvement of code review

接口自动化测试实践指导(下):接口自动化测试断言设置思路

Mutex mutex of thread C (43) is mutually exclusive

Find in 2D array

Huawei wireless device configuration WMM and priority mapping

星巴克CEO称可能关闭更多店面以保证员工安全

有效防止softmax计算时上溢出(overflow)和下溢出(underflow)的方法

Jmeter-正则、xpath、JSON
![[CS231N]Notes_1-Introduction](/img/df/5d465d73bd15c740887c4a5f184e37.png)
[CS231N]Notes_1-Introduction
Thread of C (41)
随机推荐
解决Metasploit中shell乱码的问题
两地三中心部署
JMeter regular, XPath, JSON
What does it operation and maintenance management mean? How to establish an effective IT operation and maintenance management system?
为啥有些经理,总是强行刷存在感?(你遇到过吗?)
如何提取Matlab可视化图像窗口Figure中的坐标信息
Thread deadlock of C (44)
Advanced audio and video development | Lecture 4: audio automatic gain control AGC
动手学moveit2|介绍和安装
接口自动化测试实践指导(下):接口自动化测试断言设置思路
力扣133题:只出现一次的数字
Yii framework installation steps (Yii Framework version 1.1.20, time is November 2018)
ICML 2022 | 教程效度,可靠性和意义:可复现机器学习的统计方法教程
Dependency injection with different flavors in swift
Data analysis demo
At the age of 30, I was laid off by the company, and some people never recovered, but I turned against the wind and was reborn~
C#(四十一)之线程
【MySql 实战】以 sql 的方式多表联动更新数据
超级奶思的笔记软件:Obsidain
What resources cannot be shared between threads?