当前位置:网站首页>Orepa: Ali proposed a heavy parameter strategy with fast training. The memory is halved and the speed is doubled | CVPR 2022
Orepa: Ali proposed a heavy parameter strategy with fast training. The memory is halved and the speed is doubled | CVPR 2022
2022-07-21 18:43:00 【Xiaofei's algorithm Engineering Notes】
This paper proposes an online heavy parameter method OREPA, In the training stage, complex structural parameters can be converted into single convolution , So as to reduce the time-consuming of a lot of training . In order to achieve this goal , In this paper, the linear scaling layer is used to replace the training BN layer , The diversity of optimization directions and the ability of feature expression are maintained . From the experimental results ,OREPA The accuracy and efficiency of various tasks are very good
source : Xiaofei's algorithm Engineering Notes official account
The paper : Online Convolutional Re-parameterization

- Address of thesis :https://arxiv.org/abs/2204.00826
- Paper code :https: //github.com/JUGGHM/OREPA_CVPR2022
Introduction
In addition to accuracy , The reasoning speed of the model is also very important . In order to obtain a deployment friendly and high-precision model , Recently, many studies have proposed to improve the model performance based on structural re parameterization . The model used for structural re parameterization has different structures in the training stage and the reasoning stage , Complex structures are used in training to achieve high accuracy , After training, a complex structure is compressed into a linear layer that can be inferred quickly by equivalent transformation . The compressed model usually has a simple architecture , For example, similar VGG Or similar ResNet Structure . From this point of view , The re parameterization strategy can improve the performance of the model without introducing additional reasoning time cost . Official account was sent before RepVGG Interpretation of the thesis 《RepVGG:VGG, The eternal God ! | 2021 New article 》, If you are interested, you can have a look at .

BN Layer is the key component of heavy parameter model , Add one after each convolution layer BN layer , If the figure 1b Shown , remove BN Layers can cause serious accuracy degradation . In the reasoning stage , Complex structures can be compressed into a single convolution layer . And in the training phase , because BN Layers need to nonlinearly divide the characteristic graph by its standard deviation , Each branch can only be calculated separately . therefore , There are a lot of intermediate computing operations ( Big FLOPS) And buffer characteristic diagram ( High memory usage ), Bring huge computing overhead . What's worse is , The high training cost hinders the exploration of more complex and possibly more powerful re parametric structures .
Why? BN Layer pair parameterization is so important ? Based on experiments and analysis , The paper found that BN The scaling factor in the layer can diversify the optimization direction of different branches . Based on this discovery , This paper proposes an online re parameterization method OREPA, Pictured 1c Shown , There are two steps :
- block linearization: Remove all nonlinear generalization layers , Instead, we introduce the linear scaling layer . The linear scaling layer can not only work with BN The optimization directions of different branches are diversified by the same layer , It can also be combined during training .
- block squeezing: Simplify the complex linear structure into a single convolution layer .
OREPA Reduce the computing and storage overhead caused by the middle tier , It can significantly reduce training consumption (65%-75% Video memory savings 、 Speed up 1.5-2.3 times ) And has little impact on performance , It makes it possible to explore more complex re parameterized results . To test this , The paper further proposes several re parameterized components to obtain better performance .
The contribution of this paper includes the following three points :
- An online re parameterization method is proposed OREPA, It can greatly improve the training efficiency of the heavily parameterized model , It makes it possible to explore stronger heavy parameter structures .
- According to the analysis of the principle of the counterweight parameter model , take BN Replace layer with linear scaling layer , Maintain the diversity of optimization direction and feature expression ability .
- Experiments on various visual tasks show that ,OREPA In terms of accuracy and training efficiency, it is better than the previous heavily parameterized model .
Online Re-Parameterization

OREPA It can simplify the complex structure during training into a single convolution , Keep the accuracy unchanged .OREPA The transformation process of is shown in the figure 2 Shown , contain block linearization and block squeezing Two steps .
Preliminaries: Normalization in Re-param

BN Layer is the key structure of multi-layer and multi branch structures in heavy parameters , It is the basis of heavy parameter model performance . With DBB and RepVGG For example , Get rid of BN After the layer ( Change to multiple branches and proceed uniformly BN operation ) There will be a significant decline in performance , As shown in the table 1 Shown .
What's more surprising is that ,BN The use of layer will bring too much training consumption . In the reasoning stage , All intermediate operations in the heavy parameter structure are linear , You can perform consolidation . And in the training phase , because BN The layer is nonlinear ( It needs to be divided by the standard deviation of the characteristic diagram ), Cannot perform consolidation . Failure to merge will cause intermediate operations to be calculated separately , Generate huge computing consumption and memory cost . and , The high cost also hinders the exploration of more complex structures .
Block Linearization
although BN Layer prevents merging during training , But due to the problem of accuracy , It still cannot be deleted directly . To solve this problem , The paper introduces channel-wise Linear scaling of as BN Linear substitution of layers , Zoom the feature map through the learnable vector . The linear scale layer has BN Similar effect of layer , Guide multiple branches to optimize in different directions , This is the core of heavily parameterized performance .

Based on linear scaling layer , Modify the heavily parameterized structure , Pictured 3 Shown , There are three steps :
- Remove all non-linear layers , That is, the normalization layer in the heavily parameterized structure .
- In order to maintain the diversity of optimization , A scaling layer is added at the end of each branch , namely BN Linear substitution of layers .
- To stabilize the training process , Add a after all branches BN layer .
after block linearization After the operation , There are only linear layers in the heavy parameter structure , This means that all components in the structure can be merged during the training phase .
Block Squeezing
Block squeezing Transform the operation on the intermediate characteristic graph with too much computation and memory into a faster single convolution kernel operation , This means that the extra training cost of heavy parameters will be reduced from O ( H × W ) O(H\times W) O(H×W) Reduced to O ( K H × K W ) O(KH\times KW ) O(KH×KW), among ( K H , K W ) (KH, KW) (KH,KW) Is the shape of convolution kernel .
Generally speaking , No matter how complex the linear multiparameter structure is , The following two properties are always true :
- All linear layers in the heavy parameter structure ( For example, depth convolution 、 Average pooling and recommended linear scaling ) Can be represented by convolution layer with corresponding parameters , See the appendix of the original text for specific proof .
- The multiparameter structure can be expressed as a set of parallel branches , Each branch contains a string of convolutions .

With the above two properties , So we can make multi-layer ( That is, sequential structure ) And multiple branches ( Parallel structure ) Compress to a single convolution , Pictured 4a Sum graph 4b Shown . The original text has a formula proof of partial conversion , If you are interested, you can go to the corresponding chapters of the original , This does not affect Block Squeezing The understanding of our thoughts .
Gradient Analysis on Multi-branch Topology
From the perspective of gradient retransmission, this paper analyzes the multi branch and block linearization The role of , It contains some formula derivation , If you are interested, you can go to the corresponding chapters of the original . Here are two main conclusions :
- If branch shared block linearization, The optimization direction and amplitude of multi branch are the same as that of single branch .
- If you use branch independent block linearization, The optimization direction and amplitude of multi branch are different from that of single branch .
The above conclusion shows block linearization The importance of steps . When removing BN After the layer , The zoom layer can maintain the diversification of optimization directions , Avoid multiple branches degenerating into single branches .
Block Design
because OREPA Save a lot of training consumption , It provides the possibility to explore more complex training structures . This paper is based on DBB A new heavy parameter module is designed OREPA-ResNet, The following components are added :

- Frequency prior filter:Fcanet It is pointed out that the pooling layer is a special case of frequency domain filtering , Refer to this work to join 1x1 Convolution + Frequency domain filtering branch .
- Linear depthwise separable convolution: Make a few modifications to the depth separable convolution , Remove the intermediate nonlinear activation to merge during training .
- Re-parameterization for 1x1 convolution: Previous studies have focused on 3×3 The parameters of convolution layer are ignored 1×1 Convolution , but 1x1 Convolution in bottleneck Structure is very important . secondly , The paper adds an additional 1x1 Convolution +1x1 Convolution branch , Yes 1x1 Convolution is also carried out with multiple parameters .
- Linear deep stem: Generally, the network adopts 7x7 Convolution +3x3 Convolution as stem, Some networks replace it with stacked 3 individual 3x3 Convolution achieves good accuracy . However, the paper believes that such a stacking design consumes a lot of computation on the high-resolution feature map at the beginning , For this reason will 3 individual 3x3 Convolution and the linear layer proposed in this paper are compressed into a single 7x7 Convolution layer , It can greatly reduce the calculation consumption and save the accuracy .

OREPA-ResNet Medium block The design is shown in the picture 6 Shown , This should be a down sampling block, Eventually merged into a single 3x3 Convolution for training and reasoning .
Experiment

Comparative experiment of each component .

The influence of scaling layers on the similarity of branches of each layer .

Linear scaling strategy comparison ,channel-wise The best zoom .

Comparison of training time of online and offline heavy parameters .

Compare with other heavy parameter strategies .
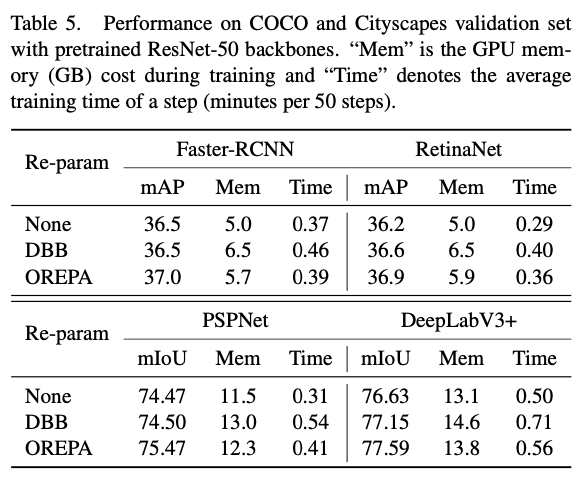
Compare the detection and segmentation tasks .
Conclusion
This paper proposes an online heavy parameter method OREPA, In the training stage, complex structural parameters can be converted into single convolution , So as to reduce the time-consuming of a lot of training . In order to achieve this goal , In this paper, the linear scaling layer is used to replace the training BN layer , The diversity of optimization directions and the ability of feature expression are maintained . From the experimental results ,OREPA The accuracy and efficiency of various tasks are very good .
If this article helps you , Please give me a compliment or watch it ~
More on this WeChat official account 【 Xiaofei's algorithm Engineering Notes 】

边栏推荐
- Golang collection: custom types and method sets
- MIL-101-Fe @UIO-66-NH2金属有机配合物(MOFs)复合材料|聚(1-H苯并吲哚)/Zn-MOF/WO3三元纳米复合材料
- ctfshow web入门 命令执行
- Getting started with ctfshow web (code audit)
- Face recognition attendance system based on jsp/servlet
- Dataframe draw correlation coefficient fitting line scatter plot fitting line
- What impact will Microsoft's closure of basic authentication have on enterprises and employees?
- LeetCode:06Z字形变换
- NepCTF2022
- Getting started with ctfshow web (file upload)
猜你喜欢

Involution: Inverting the Inherence of Convolution for Visual Recognition(CVPR2021)

什么?多商户系统不适配APP?这不就来了么!

ctfshow web入门(文件包含)

C4D用云渲染快不快?
what? Does the multi merchant system not adapt to app? This is coming!
ctfshow web入门(代码审计)

事件对象学习

TiO2-Fe3O4/MIL-101(Cr)磁性复合光催化材料|具有核壳结构的纳米药物载体(siRNA-PCNPs)

Metal organic framework mil-101 (CR) loaded chitosan material | mil-101 (CR) @cs | glycyrrhetinic acid (GA) modified metal organic framework material uio-66-nh2 (uio-66- NH2 GA)

c语言---24 三子棋
随机推荐
c语言---24 三子棋
[notes for question brushing] factorial mantissa
GrayLog分布式日志组件来提高查日志效率!
Field ‘id‘ doesn‘t have a default value 错误的解决办法
国内疫情反反复复,线下实体店的如何转型才能突破困境?
Involution: Inverting the Inherence of Convolution for Visual Recognition(CVPR2021)
TiFlash 源码阅读(五) DeltaTree 存储引擎设计及实现分析 - Part 2
【翻译】在Kubernetes上设计和部署可扩展应用程序的原则
金属有机框架MIL-101(Cr)负载壳聚糖材料|MIL-101(Cr)@CS|甘草次酸(GA)修饰金属有机框架材料UiO-66-NH2(UiO-66- NH2-GA)
从新零售到社区团购,这中间发生了多少变化?
MySQL character set and collation
丹磺酰荧光素标记肽核酸偶联多肽|Dansyl-Ahx-PNA荧光素标记肽核酸的合成路线
Research on the coding sequence of GB 2312
C4D用云渲染快不快?
Leetcode 201 Digit range bitwise and (2022.07.20)
狂神说Es
Dataframe draw correlation coefficient fitting line scatter plot fitting line
USB眼图常识
从部队文职转行程序员,我有这些体会
Control in canoe panel: switch/indicator