当前位置:网站首页>MySQL and Mongo database warehousing in scratch pipeline
MySQL and Mongo database warehousing in scratch pipeline
2022-07-22 00:47:00 【Fan zhidu】
mysql database
stay setting.py In file
# Mysql Settings
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'images360'
MYSQL_PORT = 3306pipeline.py in
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.port = port
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
self.db = pymysql.connect(self.host,self.database, charset='utf8', port=self.port)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (item.table, keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
def close_spider(self, spider):
self.db.close()mongo database
stay setting.py In file
MONGO_URL = 'localhost'
MONGO_DB = 'images360'pipeline.py in
class MongoPipeline(object):
def __init__(self, mongo_url, mongo_db):
self.mongo_url = mongo_url
self.mong_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
# adopt crawler The object gets Scrapy All the core components of ( Such as global configuration information ) And create a Pipeline example
return cls(
mongo_url=crawler.settings.get('MONGO_URL'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
# Create database connection object
self.client = pymongo.MongoClient(self.mongo_url)
# Specify database
self.db = self.client[self.mong_db]
def process_item(self, item, spider):
# Insert data into the specified table
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
# Close database connection
self.client.close()Self contained imagepipeline download
setting.py
IMAGES_STORE = './images'
ITEM_PIPELINES = {
'images360.pipelines.MongoPipeline': 300,
'images360.pipelines.MysqlPipeline': 301,
'images360.pipelines.ImagePipeline': 302,
}pipeline.py
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['url'])边栏推荐
- 【进阶数据挖掘技术】进阶数据挖掘技术介绍
- Comment les applets utilisent la barre de navigation personnalisée
- 分享50个免费的云盘网盘服务——拥有无限储存空间
- 【特征转化】特征转化是为了保证很小的信息损失,但有高品质的预测结果。
- Special writing method of if statement in go language (if with semicolon;)
- Several usages of return statement in go language
- Request consolidation (batch) in high concurrency scenarios
- Structured design SD
- 批量转移(复制)文件夹内同类型文件(win10)
- Applet to upload pictures
猜你喜欢
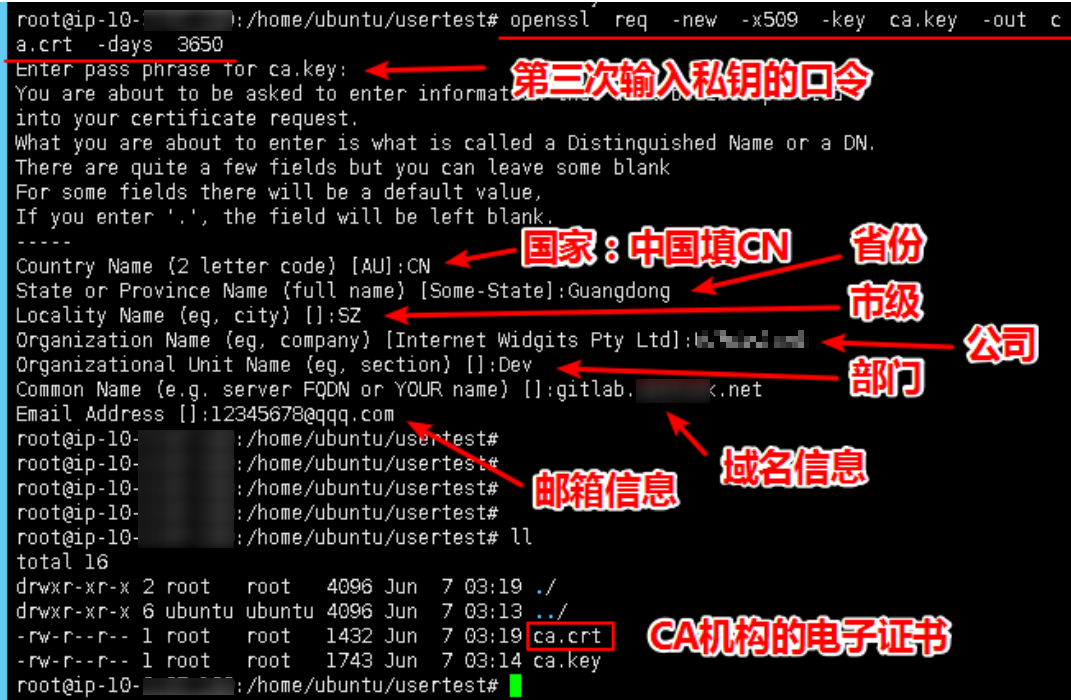
生成自签名证书:生成证书和秘钥

小程序如何使用自定義導航欄

【特征选择】特征选择的几种方法

【特征工程概要】解释什么是特征,特征工程的步骤
![[natural language processing and text analysis] PCA text dimensionality reduction. Singular value decomposition SVD, Pu decomposition method. Unsupervised word embedding model glove. The method of tra](/img/24/37983c4c92a0905203d770d0052a6b.png)
[natural language processing and text analysis] PCA text dimensionality reduction. Singular value decomposition SVD, Pu decomposition method. Unsupervised word embedding model glove. The method of tra

1. Basic concepts of machine learning
![[natural language processing and text analysis] summary of text feature extraction methods. Keyword extraction method. IDF and RCF with good effect are recognized.](/img/8c/b923630a78094cc5d6e8ef2ec19749.png)
[natural language processing and text analysis] summary of text feature extraction methods. Keyword extraction method. IDF and RCF with good effect are recognized.

如何实现退出小程序 重新进入到最新版

【自然语言处理与文本分析】非结构文本转结构数据。BP神经网络,反向传播神经网络,神经网络优化的底层原理,梯度优化法
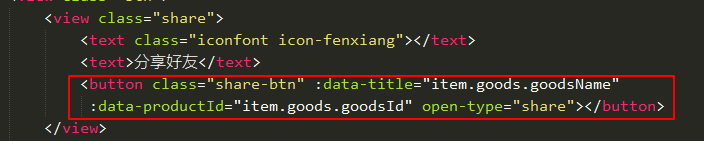
小程序分享如何传递参数
随机推荐
oracle创建表空间及查看表空间和使用情况
[natural language processing and text analysis] two sub models of word2vec (supervised neural network model), skip gram and cbow model.
[feature learning] use association rules and neural networks to establish new features
js获取服务端IP、端口、协议
解决插入word文档中的图片变得不清晰问题
《Redis深度历险核心原理与应用实践》读书笔记
How to realize SKU screening of goods by applet
Download of typora and use of markdown
新一代企业IT架构到底是什么?云原生?低代码?
SparkSQL 实验
结构化分析SD SASP
TypeScript(二)
从装配式建筑流行看云原生技术中台价值 (二)
[natural language processing and text analysis] summary of text feature extraction methods. Keyword extraction method. IDF and RCF with good effect are recognized.
一个程序员的水平能差到什么程度?
基于无法安装64位版本的visio,因为在您的PC上找到了以下32位程序的解决办法
【基础数据挖掘技术】探索性数据分析
【自然语言处理和文本分析】基本信息检索技术中的全面扫描法和逐项翻转法。
【 traitement du langage naturel et analyse de texte】 cet article présente la méthodologie de l'exploration de texte avec deux cas de projet.
dataframe 统计重复次数