当前位置:网站首页>Summary of five methods of window function
Summary of five methods of window function
2022-07-22 10:40:00 【Energetic Wang Dapeng】
The window function is also called OLAP function , Is to operate on a set of values , But when operating on a set of values , You don't need to use group by Clause , To achieve the logical implementation of Grouping calculation . And it can also be achieved that a piece of data is divided into multiple groups for repeated calculation .
When encountering accumulation 、 Cumulative 、 Until what time is this scene , Give priority to window analysis OVER solve .

List of articles
One 、 polymerization :sum,avg,max,min
data
task1,2022-04-10,1
task1,2022-04-11,5
task1,2022-04-12,7
task1,2022-04-13,3
task1,2022-04-14,2
task1,2022-04-15,4
task1,2022-04-16,4
Cumulative calculation
SELECT taskid,createtime,pv,
-- pv1: Within the group from the starting point to the current line pv The cumulative , Such as ,11 The no. pv1=10 The no. pv+11 The no. pv, 12 Number =10 Number +11 Number +12 Number
SUM(pv) OVER(PARTITION BY taskid ORDER BY createtime) AS pv1,
-- pv2: Same as pv1
SUM(pv) OVER(PARTITION BY taskid ORDER BY createtime ROWS BETWEEN UNBOUNDED
PRECEDING AND CURRENT ROW) AS pv2,
-- pv3: Within group (cookie1) be-all pv Add up
SUM(pv) OVER(PARTITION BY taskid) AS pv3,
-- pv4: Go ahead in groups + forward 3 That's ok ,11 Number =10 Number +11 Number , 12 Number =10 Number +11 Number +12 Number , 13 Number =10 Number +11 Number +12 Number +13 Number , 14 Number =11 Number +12 Number +13 Number +14 Number
SUM(pv) OVER(PARTITION BY taskid ORDER BY createtime ROWS BETWEEN 3 PRECEDING
AND CURRENT ROW) AS pv4,
-- pv5: Go ahead in groups + forward 3 That's ok + Back up 1 That's ok , Such as ,14 Number =11 Number +12 Number +13 Number +14 Number +15 Number =5+7+3+2+4=21
SUM(pv) OVER(PARTITION BY taskid ORDER BY createtime ROWS BETWEEN 3 PRECEDING
AND 1 FOLLOWING) AS pv5,
-- pv6: Go ahead in groups + All the way back , Such as ,13 Number =13 Number +14 Number +15 Number +16 Number =3+2+4+4=13,14 Number =14 Number +15 Number +16 Number =2+4+4=10
SUM(pv) OVER(PARTITION BY taskid ORDER BY createtime ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS pv6
FROM hive_zjyprc_hadoop.tmp.task1 order by taskid, createtime;
Get the results :
Templates
The logic of aggregation after grouping , When calculating a record , Which data should be put into a group for aggregate calculation . We take pv4 To illustrate :SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv4
First determine which data is a group , And in a group , What is the order of the data
PARTITION BY cookieid ORDER BY: according to cookieid To group , according to createtime Sort by . The grouping here can be understood as opening a window , The default window size is two . When this is done , The data looks like this :
Then determine the length of the window
The window length refers to which record to traverse now , What data are calculated for this window .
The template of window length is :Rows between A and B.
A There are three ways of writing :- unbounded preceding Indicates that it starts from the first item of the current group , Until the first item in this group
- X preceding Start with the current number of rows , Not counting the current one , Count forward X strip
- current row Current row
B There are three ways of writing :
- unbounded following To the end of the last line of the Group , From the current row to the last row of the Group
- X following After the current line * That's ok , Take it back X That's ok
- current row Current row
take pv4 Look at :ROWS BETWEEN 3 PRECEDING AND CURRENT ROW

When it comes to 4-13 When the data is , Push forward 3 Calculate to the current line 3, seek sum:1+5+7+3=16
- Finally, let's see what calculations are performed on this window
The last calculation performed is the aggregate function , You can ask in the window sum,avg,max or min.
Two 、 ranking :row_number,rank,dense_rank
When it comes to sorting every piece of data in the table, it is necessary to put it into the corresponding group .row_number, rank, dense_rank It's very useful .
data
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
Row number
ROW_NUMBER() The function is : from 1 Start , In order , Generating a sequence of records within a group . such as :
- May, in accordance with the pv Descending order , Generate... For each day in the group pv Ranking ;
- Get the first ranked record in the group ;
- Get one session First of all refer
SELECT taskid, createtime, pv,
ROW_NUMBER() OVER(PARTITION BY taskid ORDER BY pv desc) AS rn
FROM hive_zjyprc_hadoop.tmp.task1;
So if you need to take the front of each group 3 name , It only needs rn<=3 that will do .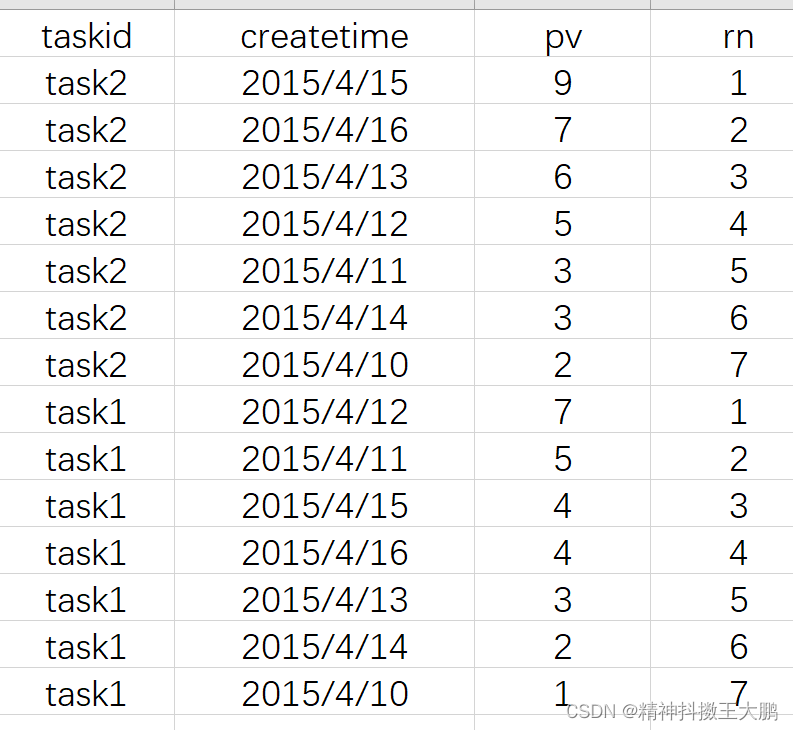
rank and dense_rank
- RANK() Generate the ranking of data items in the group , When the ranking is equal , Will leave a vacancy in the ranking , The new value sorting will increase . Such as :335
- DENSE_RANK() Generate the ranking of data items in the group , When the ranking is equal , There will be no vacancy in the ranking , Parallel ranking , The sorting of new values will not change . Such as :334
SELECT taskid, createtime, pv,
RANK() OVER(PARTITION BY taskid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY taskid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY taskid ORDER BY pv DESC) AS rn3
FROM hive_zjyprc_hadoop.tmp.task1
WHERE taskid = 'task1';

3、 ... and 、 section :ntile,cume_dist,percent_rank
data
d1,user1,1000
d1,user2,2000
d1,user3,3000
d2,user4,4000
d2,user5,5000
ntile
grammar
NTILE(n), It is used to cut the grouped data into n slice , Returns the current slice value , If the slice is not uniform , The distribution of the first slice is increased by default .
NTILE Window syntax is not supported , namely ROWS BETWEEN, such as NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
Example
SELECT taskid,createtime,pv,
-- Divide the data into 2 slice
NTILE(2) OVER(PARTITION BY taskid ORDER BY createtime) AS rn1,
-- Divide the data into 3 slice
NTILE(3) OVER(PARTITION BY taskid ORDER BY createtime) AS rn2,
-- Divide all the data into 4 slice , Default asc Ascending
NTILE(4) OVER(ORDER BY createtime) AS rn3
FROM hive_zjyprc_hadoop.tmp.task1
ORDER BY taskid,createtime;
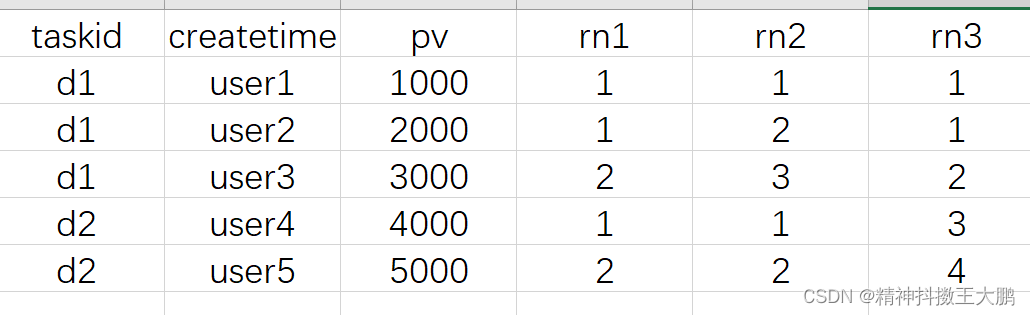
ntile The scene is suitable for counting percentages top Group , such as : Query the top of the day with the highest duration 60% Average duration of users
scene : Query the top of the day with the highest duration 60% Average duration of users
utilize ntile The function divides it into five groups in descending order of duration , The ranking is 1,2,3 The group is the front 60% User duration of .
SELECT avg( Duration )
FROM (
SELECT Duration , ntile ( 5 ) over ( ORDER BY Duration desc ) AS ranking
FROM surface 1
) a
WHERE a.ranking in (1,2,3);
cume_dist
CUME_DIST Number of lines less than or equal to the current value / The total number of rows in the group .
Example
For the current data Count the number of people less than or equal to the current salary , The proportion of the total number of people .
SELECT dept, userid, sal,
round(CUME_DIST() OVER(ORDER BY sal), 2) AS rn1,
round(CUME_DIST() OVER(PARTITION BY dept ORDER BY sal desc), 2) AS rn2
FROM hive_zjyprc_hadoop.tmp.task1;

rn1: No, partition, All data are 1 Group , The total number of rows is 5
- first line : Less than or equal to 3000 The number of lines is 3, therefore ,3/5=0.6
- The third line : Less than or equal to 1000 The number of lines is 1, therefore ,1/5=0.2
rn2: Group by Department ,dpet=d1 The number of lines is 3,
- The second line : Less than or equal to 2000 The number of lines is 2, therefore ,2/3=0.67
For repetition value , When calculating , Take the position of the last row of duplicate values .
scene : Count the number of people in different departments whose salary is less than or equal to the current salary , The proportion of people in different departments
cume_dist The actual scene can be counted The distribution of a value in the total value , Such as :
Count the number of people in different departments whose salary is less than or equal to the current salary , The proportion of people in different departments
SELECT department , people , salary ,
round(CUME_DIST() OVER(PARTITION BY department ORDER BY salary ), 2) AS rn1
FROM surface ;
percent_rank
percent_rank: and cume_dist The difference lies in the method of calculating the distribution results , The calculation method is as follows ( The relative position -1)/( Total number of lines -1)
SELECT dept, userid, sal,
PERCENT_RANK() OVER(ORDER BY sal) AS rn1, -- Within group
RANK() OVER(ORDER BY sal) AS rn11, -- Within group RANK value
SUM(1) OVER(PARTITION BY NULL) AS rn12, -- The total number of rows in the group
PERCENT_RANK() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM hive_zjyprc_hadoop.tmp.task1;

rn1: rn1 = (rn11-1) / (rn12-1)
- first line ,(1-1)/(5-1)=0/4=0
- The second line ,(2-1)/(5-1)=1/4=0.25
- In the fourth row ,(4-1)/(5-1)=3/4=0.75
rn2: according to dept grouping ,dept=d1 The total number of rows is 3
- first line ,(1-1)/(3-1)=0
- The third line ,(3-1)/(3-1)=1
Four 、 grouping :grouping sets, grouping_id, cube, rollup
These analysis functions are usually used for OLAP in , It can't add up , And we need to make statistics according to the indicators of drilling up and drilling down in different dimensions , such as ,
Minutes and hours 、 God 、 Of the month UV Count .
data
2015-03,2015-03-10,cookie1
2015-03,2015-03-10,cookie5
2015-03,2015-03-12,cookie7
2015-04,2015-04-12,cookie3
2015-04,2015-04-13,cookie2
2015-04,2015-04-13,cookie4
2015-04,2015-04-16,cookie4
2015-03,2015-03-10,cookie2
2015-03,2015-03-10,cookie3
2015-04,2015-04-12,cookie5
2015-04,2015-04-13,cookie6
2015-04,2015-04-15,cookie3
2015-04,2015-04-15,cookie2
2015-04,2015-04-16,cookie1
grouping sets
In a GROUP BY Querying , Aggregate according to different dimension combinations , It's equivalent to putting different dimensions of GROUP BY The result set is UNION ALL.
SELECT month, day,
COUNT(DISTINCT cookied) AS uv,GROUPING__ID
FROM hive_zjyprc_hadoop.tmp.task4
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
-- Equivalent to respectively group by do union all
ORDER BY GROUPING__ID;
GROUPING__ID, Indicates which grouping set the result belongs to .
cube
according to GROUP BY Aggregation of all combinations of dimensions
SELECT month, day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM hive_zjyprc_hadoop.tmp.task4
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;

rollup
yes CUBE Subset , It's the leftmost dimension , Hierarchical aggregation from this dimension .
such as , With month Dimensions are aggregated hierarchically ,SQL sentence
SELECT month, day, COUNT(DISTINCT cookied) AS uv, GROUPING__ID
FROM hive_zjyprc_hadoop.tmp.task4
GROUP BY month,day WITH ROLLUP ORDER BY GROUPING__ID;

The result is zero : Lunar UV-> Of the month UV-> total UV
with rollup It will finally appear null, This line is for each group before , The value of a column to be displayed by using the grouped set operation .
5、 ... and 、 Take the former value or the latter value :lag,lead,first_value,last_value
data
Peter,2015-10-1201:10:00,url1
Peter,2015-10-1201:15:10,url2
Peter,2015-10-1201:16:40,url3
Peter,2015-10-1202:13:00,url4
Peter,2015-10-1203:14:30,url5
Marry,2015-11-1201:10:00,url1
Marry,2015-11-1201:15:10,url2
Marry,2015-11-1201:16:40,url3
Marry,2015-11-1202:13:00,url4
Marry,2015-11-1203:14:30,url5
lag and lead
grammar
These two functions can get the first... Of the same field in the same query N Row data (Lag) And after N Row data (Lead) As an independent column .
- LAG(col,n,DEFAULT) It is used to count up the n Row value
The first parameter is the column name ,
The second parameter is upward n That's ok ( Optional , The default is 1),
The third parameter is the default value ( When you go up n Behavior NULL When , Take the default value , If not specified , Then for NULL) - LEAD(col,n,DEFAULT) Used for the next... In the statistics window n Row value
The first parameter is the column name ,
The second parameter is next n That's ok ( Optional , The default is 1),
The third parameter is the default value ( When you go down n Behavior NULL When , Take the default value , If not specified , Then for NULL)
scene : Calculate the time each user stays on a page , And the total residence time of each page
The actual scene : Calculate the time each user stays on a page , And the total residence time of each page .
Ideas :
- Get the start and end time of a user's stay on a page
select cookieid,
createtime stime,
lead(createtime) over(partition by cookieid order by createtime) etime,
url
from hive_zjyprc_hadoop.tmp.task5;

- Calculate the time interval that users stay on the page
SELECT cookieid
,stime
,etime
,UNIX_TIMESTAMP(etime,'yyyy-MM-dd HH:mm:ss')- UNIX_TIMESTAMP(stime,'yyyy-MM-dd HH:mm:ss') AS period
,url
FROM
(
SELECT cookieid
,createtime stime
,lead(createtime) over(partition by cookieid ORDER BY createtime) etime
,url
FROM hive_zjyprc_hadoop.tmp.task5
);

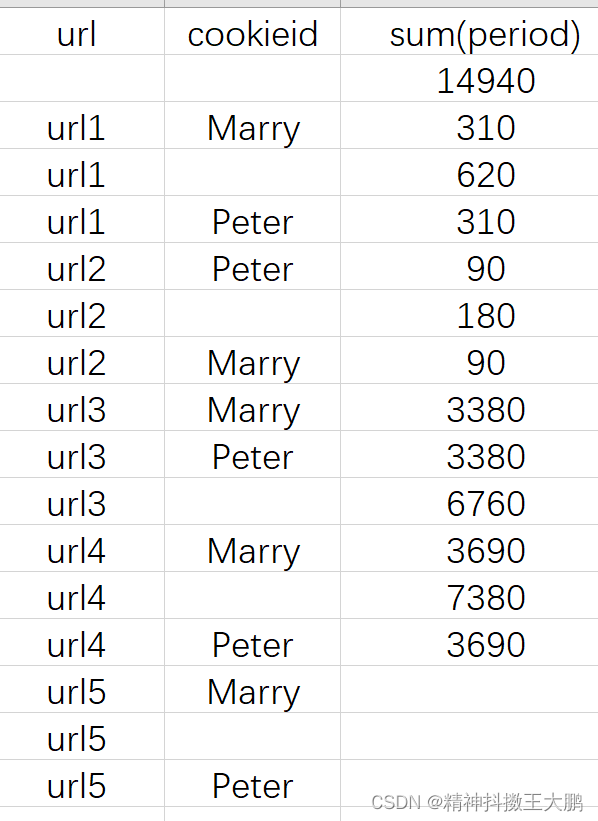
- Calculate the time each user stays on a page , And the total residence time of each page
SELECT url
,cookieid
,sum(period)
FROM
(
SELECT cookieid
,createtime stime
,lead(createtime) over(partition by cookieid ORDER BY createtime) etime
,UNIX_TIMESTAMP(lead(createtime) over(partition by cookieid ORDER BY createtime),'yyyy-MM-dd HH:mm:ss')- UNIX_TIMESTAMP(createtime,'yyyy-MM-dd HH:mm:ss') AS period
,url
FROM hive_zjyprc_hadoop.tmp.task5
) temp
group by url, cookieid with ROLLUP;
first_value and last_value
grammar
first_value: After sorting in groups , Up to the current line , The first value is
last_value: After sorting in groups , Up to the current line , Last value
These two can be used in general : Take positive order for each group last_value That is to put each group in reverse order , And then take first_value.
scene : Check each user , First visited url
scene : Check each user , First visited url
SELECT cookieid, createtime, url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM hive_zjyprc_hadoop.tmp.task5;

边栏推荐
- 控制台字体怎么改为console?
- 通达信上开户安全吗?
- 元宇宙时代到来,Soul张璐团队如何打造全新社交体验?
- 金仓数据库KingbaseES安全指南--2.1. 关于数据库安全威胁
- Lihuadaiyu music player 3.91 source code is open source (add background music to the website)
- Request and response description
- @resource和@autowired的区别
- Wallpaper background wall / avatar / dynamic wallpaper applet source code - support user submissions - with some collection functions + building tutorials
- 窗口函数的5种方法总结
- Servlet Chapter 1
猜你喜欢
窗口函数的5种方法总结

Ingress

Lihuadaiyu music player 3.91 source code is open source (add background music to the website)

面试难题:分布式 Session 实现难点,这篇就够!

day02-2

STD:: thread combine avec des objets de classe

What is the fastapi asynchronous framework? (comprehensive understanding)

IDEA 2022.2 正式发布,骚操作,跟不上了!

光明正大的水贴来自考研人对暑假的感悟

网页保存为pdf神器(可自定义编辑)—Print Edit WE
随机推荐
为什么web中pom的servlet依赖scope为provided
2022.7.21 特殊矩阵压缩
[微信小程序开发者工具] × #initialize-error: Error: ENOENT: no such file or directory, open
BigInteger :new BigInteger(tokenJson.getBytes()).toString(16)什么意思
史上最全的mysql数据类型汇总(下)
Servlet 体系
Construction of Chenzhou stem cell laboratory: analysis of strong current system
Servlet 乱码解决
动作理论基础
At the age of 51, he wrote code for the satellite: tough life, never afraid of late
金仓数据库KMonitor使用指南--3. 部署
Laundry applet source code - add docking with third-party errands
11 classification maintenance of commodity system in gulimall background management
Request 和Response 说明
The latest Hubei construction special worker (construction elevator) simulation question bank and answers in 2022
女性健康养生资讯网类织梦模板(带手机端)【测试可搭建】
Execution failed for task ‘:app:kaptDevDebugKotlin‘.
1307_ Summary of crystal oscillator test in embedded design
新品发布:总线视频监控专用VGA显示驱动模组
封装